
In this NetApp training tutorial, I will cover NetApp MetroCluster. This is NetApp’s solution for redundancy for a storage system spread across two different buildings that are within the same geographical region. Before I get into the details of MetroCluster, it’s going to be easier to understand it if we have a quick review of High Availability first. Scroll down for the video and also text tutorial.
NetApp MetroCluster Video Tutorial

Rodney Banipal

I am happy to say that I have passed the NetApp NCDA exam. Your video course was very informative to understand how NetApp works. I have practiced a lot in my lab and that led me to get a NetApp job. Without your course I would not be here so a big thank you goes to you. I could not have done it without your course.
Controller Failure Scenario
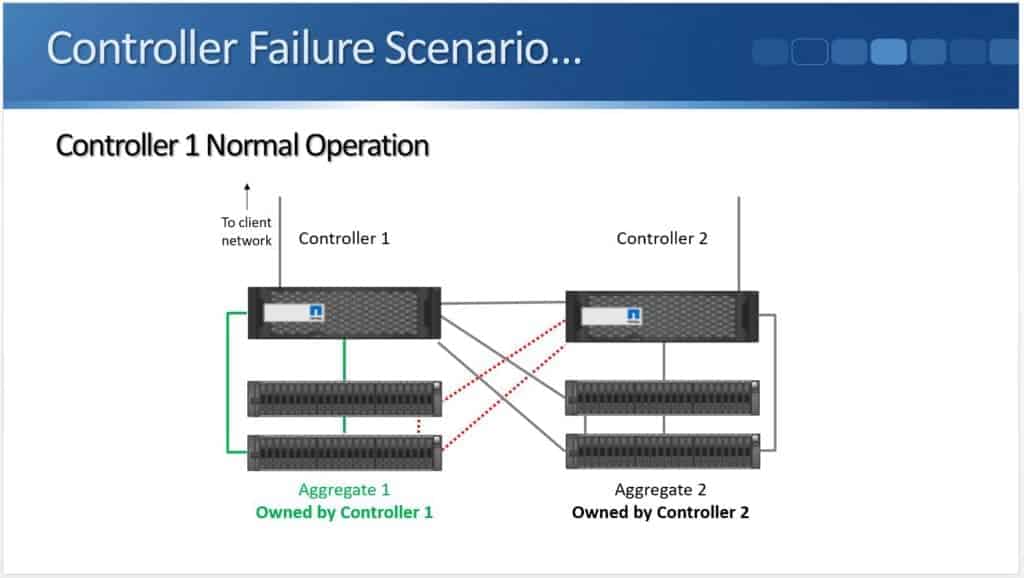
Looking at the diagram above, I've got my standard high availability pair we are calling “Controller 1” and “Controller 2”. In Netapp ONTAP our disks are always owned by one and only one controller. Our disks are grouped into aggregates. You can see in the diagram that Aggregate 1 is owned by Controller 1 and Aggregate 2 is owned by Controller 2.
High availability gives us redundancy for our controllers so if Controller 1 fails…
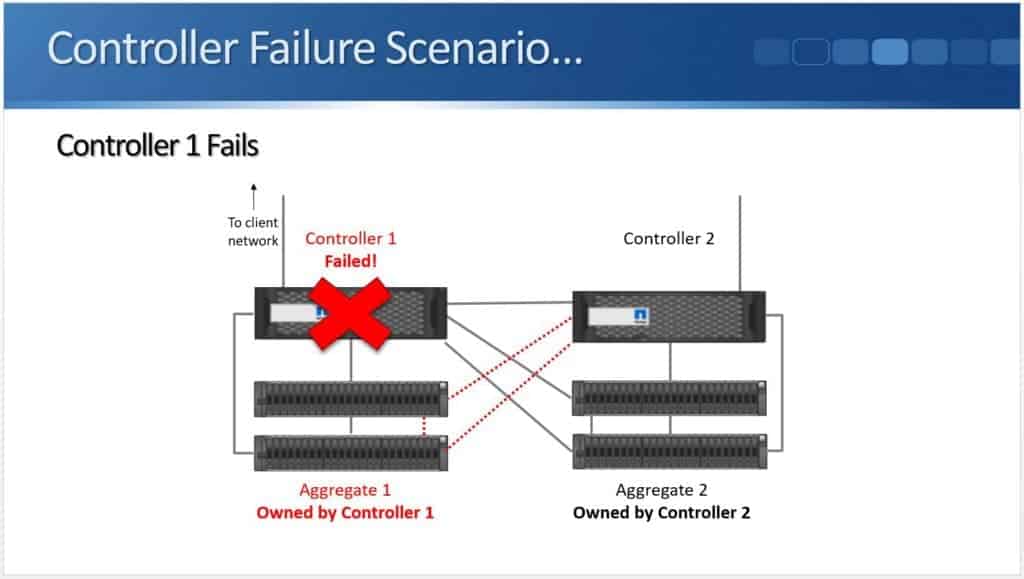
… its High Availability partner (in this case, Controller 2) is going to detect that.
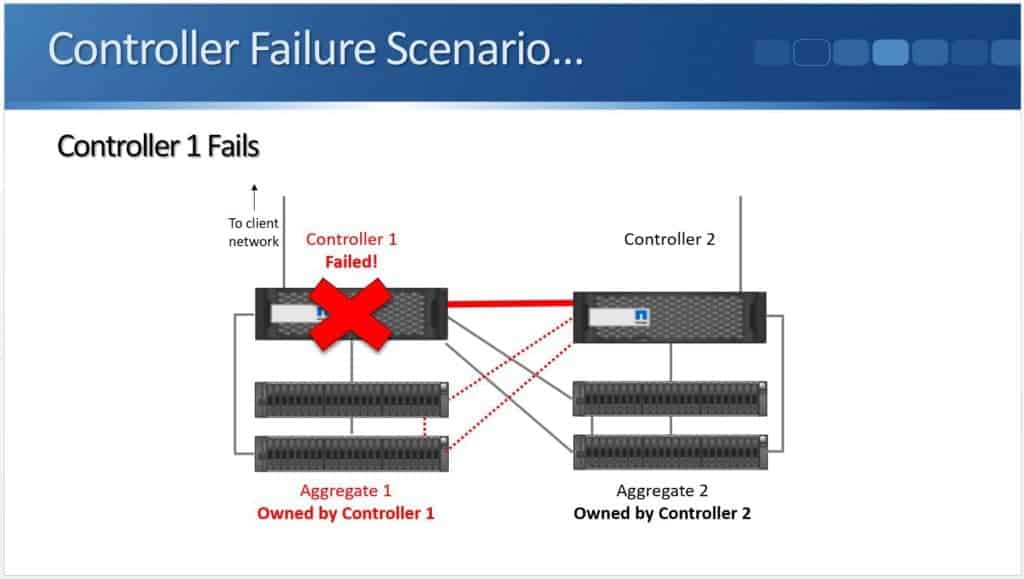
It can either detect it over the High Availability connection (highlighted above), or it can detect it using the Service Processors with hardware assisted fail over…
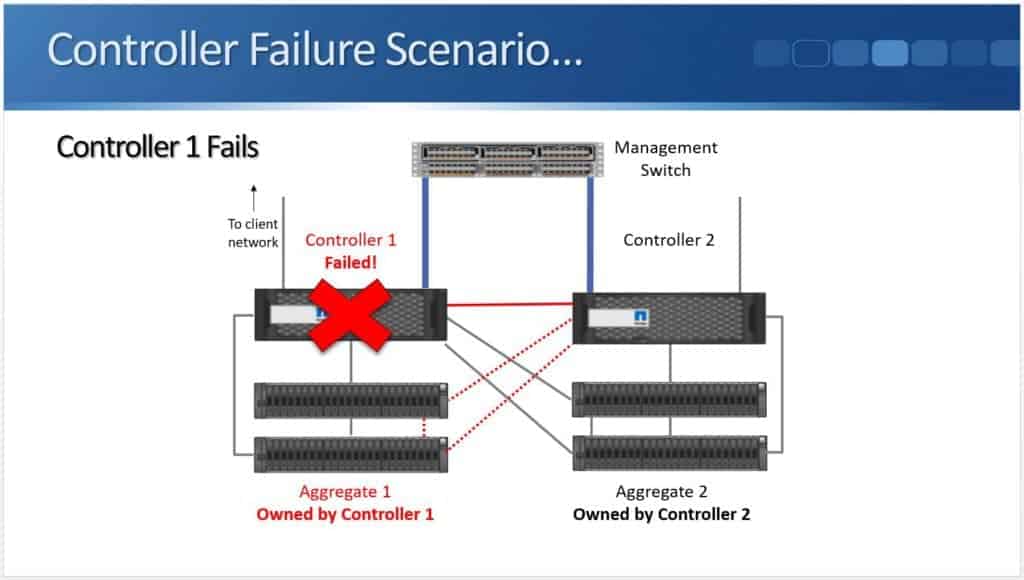
When Controller 2 detects that Controller 1 has failed, it will take temporary ownership of its disks.
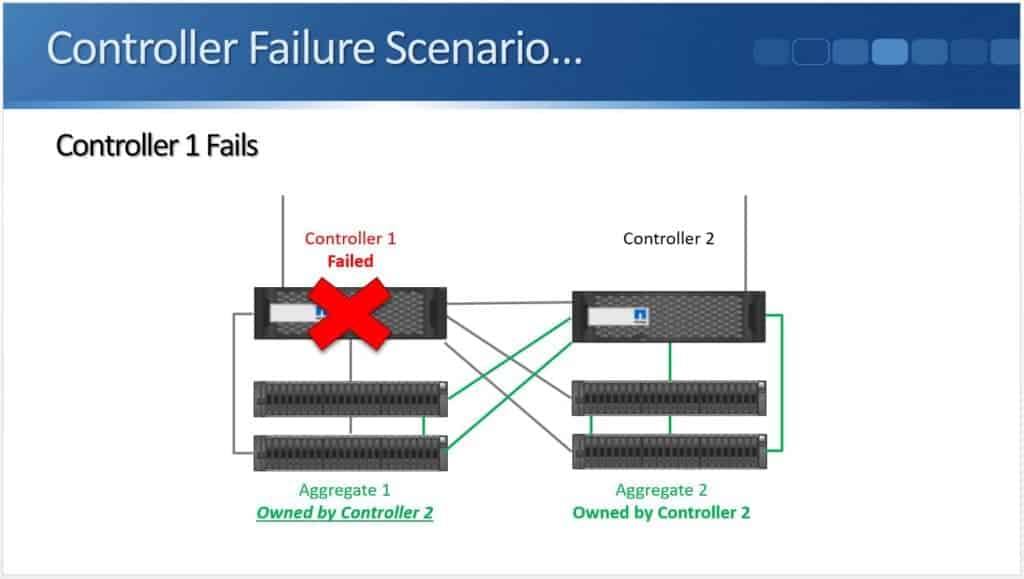
As you see above, Controller 2 now owns Aggregate 1 and Aggregate 2, and our clients are still able to reach all of their data.
Building Failure Scenario
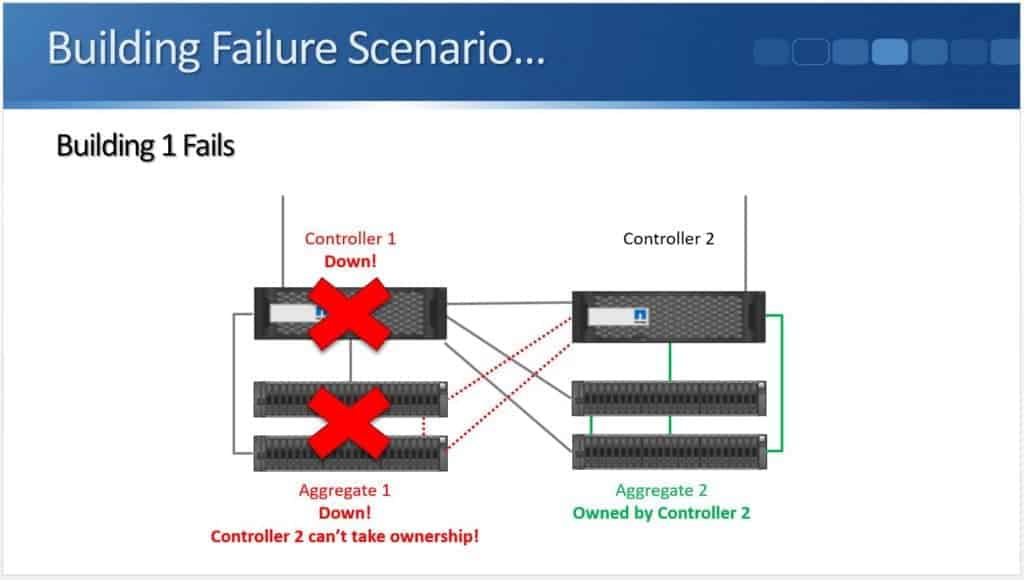
High availability helps when we have a controller failure, but what if the whole building goes down?
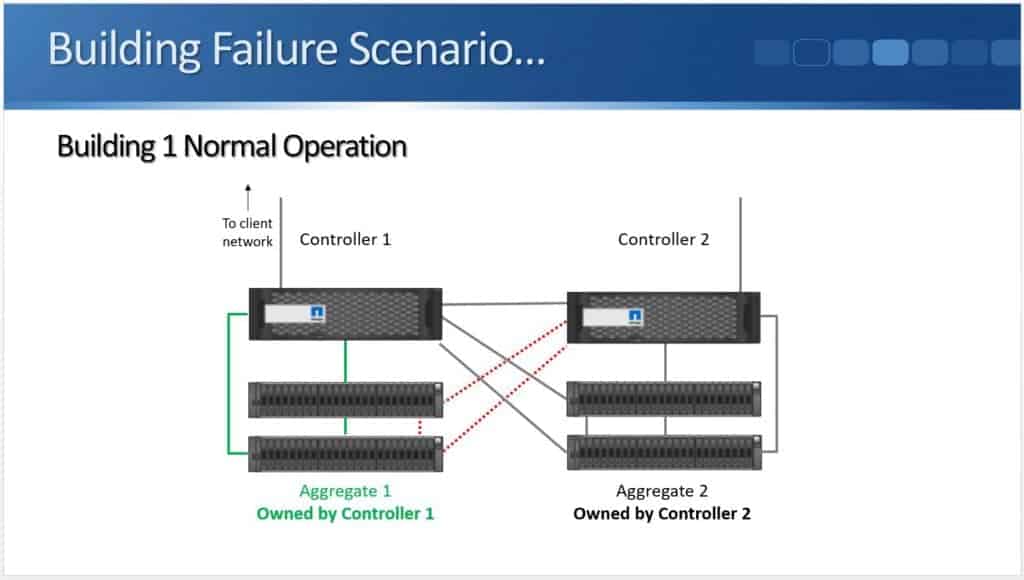
In the example above I've got Controller 1 and its disk shelves in one building. Controller 2 and its disk shelves are in a different building. This time, it's not just the controller that fails, we lose the whole building.
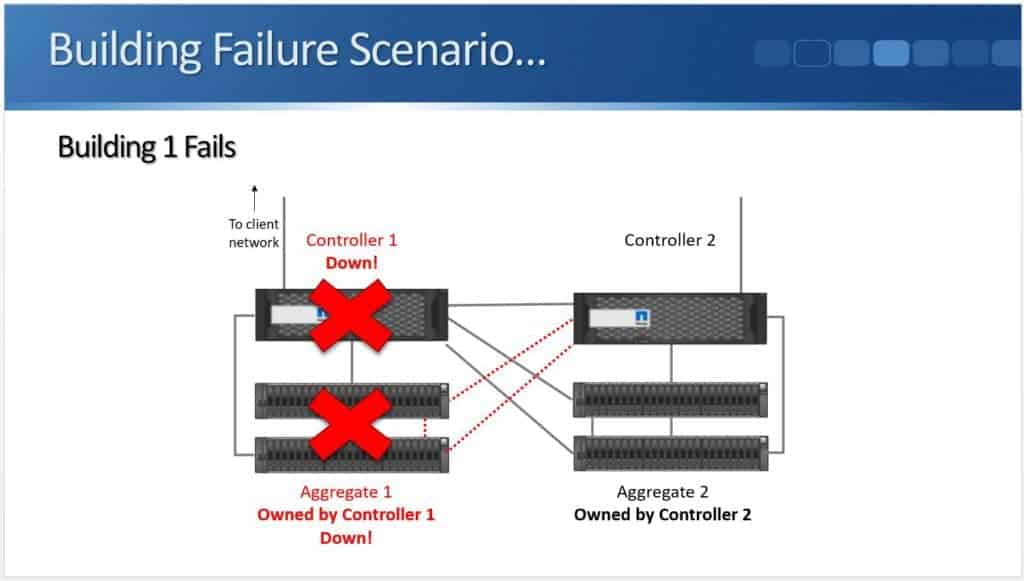
In this example let's say it’s a power outage. I've lost my controller and I've lost my disk shelves as well.
Controller 2 will still detect the failure over the High Availability connection because it's no longer going to be receiving a keepalive signal.
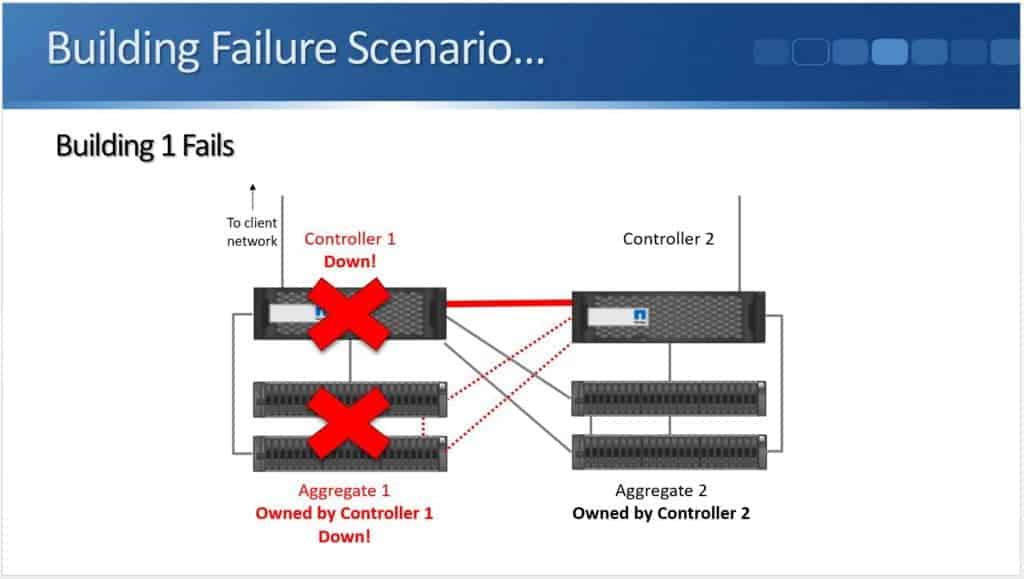
The problem, though, is that it can't take control of Aggregate 1 because the disk shelves are gone. Aggregate 1 isn't there anymore due to the failure.
High availability gives us redundancy for our controllers, but it doesn't give us redundancy should we lose the entire building. That's where NetApp MetroCluster comes in.
NetApp MetroCluster
NetApp MetroCluster gives us redundancy in case of a building failure by combining High Availability and SyncMirror. SyncMirror is used to mirror the aggregates to a disk shelf in each building.
- High Availability - gives us redundancy for our controllers.
- SyncMirror - gives us redundancy for our disk shelves.
By combining the two, we get redundancy for the entire building. If we wanted to, we could selectively choose which aggregates to mirror. We could either mirror all of them or we could cut down on disk hardware costs by only mirroring our mission critical aggregates.
Building Failure Scenario… with NetApp MetroCluster
Let's take a look at how NetApp MetroCluster is going to work.
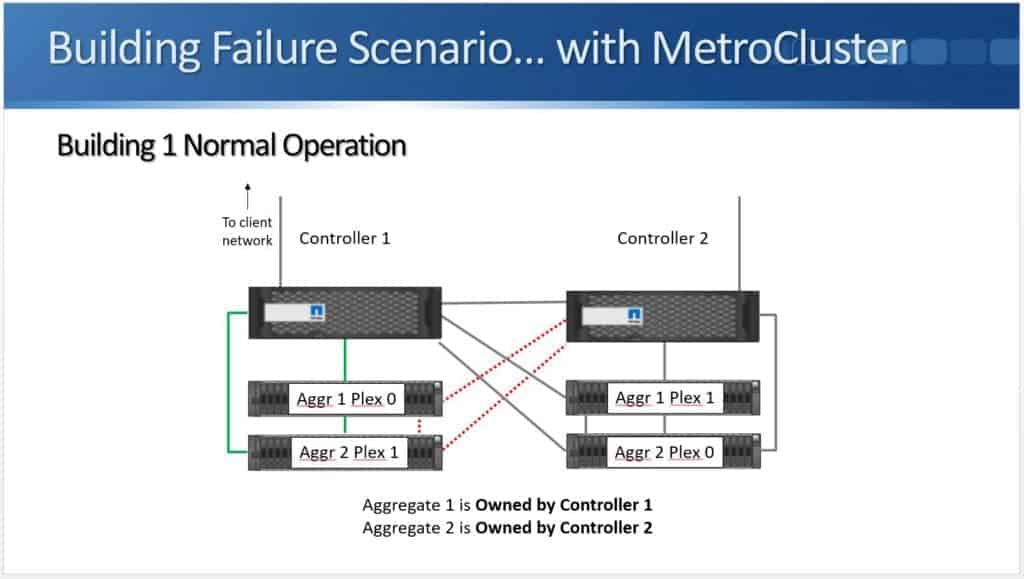
You can see above that I've got my two controllers again. Controller 1 in one building, Controller 2 in another building. Controller 1 has its disk shelves and Controller 2 has its disk shelves. Aggregate 1 is still owned by Controller 1, but I have it SyncMirrored across the two buildings. Plex 0 is in one building and Plex 1 is in the other building. I’ve done that for Aggregate 2 as well.
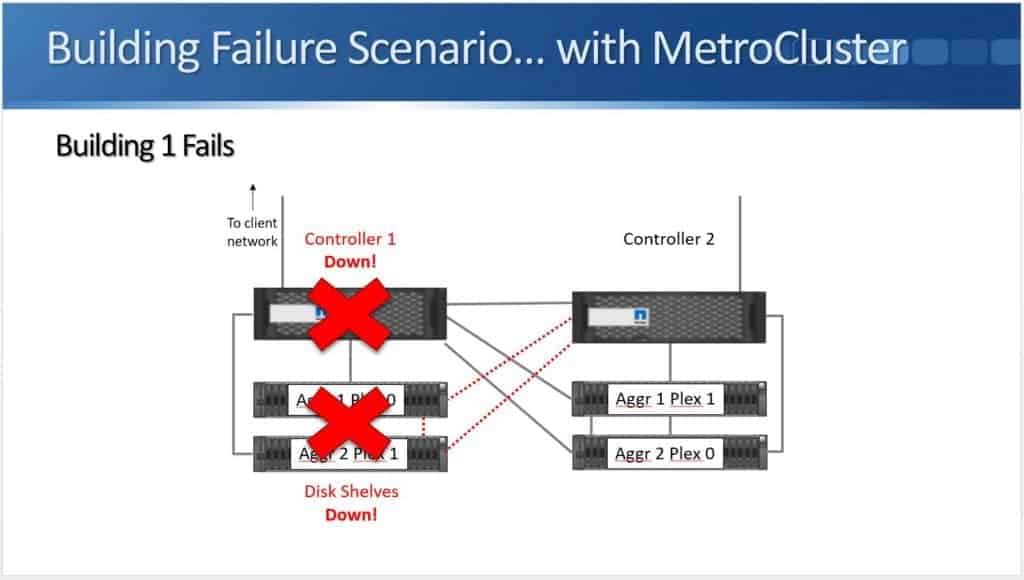
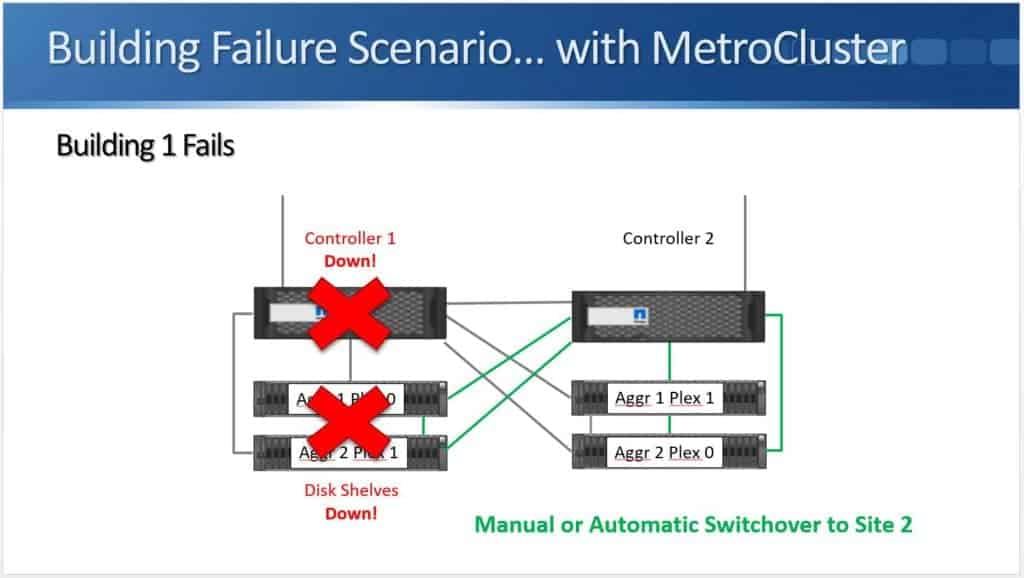
If building 1 fails (as shown above), I lose the controller and I lose the disk shelves, but because Aggregate 1 and Aggregate 2 are still available in the other building, my clients don't lose access to their data.
The switchover to the second building can either be done manually or we can use automatic switchover. I'll go into more detail on that later.
Recovery Point Objective (RPO)
SyncMirror, and therefore MetroCluster, uses synchronous replication. Data is written to both buildings before the acknowledgment is sent back to the client. Due to synchronous replication, NetApp MetroCluster has a Recovery Point Objective of zero. No data is lost in the case of an outage.
NetApp MetroCluster in ONTAP 8.3.0
There's been a few different implementations of MetroCluster in Clustered ONTAP. It first became available in ONTAP version 8.3.0. That's actually the version that coincided with the decision to discontinue 7-mode. MetroCluster had been available in 7-mode for quite a while, and was practically the last major feature to be ported over to Clustered ONTAP. This likely played a major part in the decision to discontinue 7-mode.
In ONTAP 8.3.0, NetApp MetroCluster only supports a four node setup. This configuration is also available in later versions of ONTAP. With the four node MetroCluster setup, both sites host an independent two node cluster.
MetroCluster only runs across two sites. We can't have three or more.
The two nodes in each site are an HA pair for each other. SyncMirror mirrors the aggregates across both sites. Not across both nodes in the same site, across both actual sites. It's an active-active configuration. Each site serves read requests to local clients from the local Plex.
If a single controller fails, the remaining controller in the same site will take over its aggregates, just like in a standard High Availability scenario. If both controllers in a site go down (meaning the entire site is down) you can failover to the other site.
The sites can be up to 200 kilometres apart.
Controller to Shelf Distance Problem
If SAS is being used for the controller to disk shelf connections, there is a controller to shelf distance problem because SAS only supports short cable lengths. How can we cable controllers to a disk shelf in another building?
Fabric-Attached MetroCluster
An option that does support long length cables is Fibre Channel. A pair of Fibre Channel switches can be installed in both sites. Now we have the next problem - the current models of disk shelves have SAS, not Fibre Channel ports. If we're using these long distance Fibre Channel cables to go from the controller to the shelves in the other site, how are we going to actually get the cable into the disk shelf?
ATTO FireBridge
That's where the ATTO Fibre Bridge comes in. It's a Fibre Channel to SAS Gateway. It has both a Fibre Channel and a SAS port, and it can convert between the two. The controller connects to the Fibre Bridge with Fibre Channel cables via the Fibre Channel switches. The Fibre Bridge connects to the disk shelves with SAS cables. This will look clearer when you see it in the next section below.
Fabric-Attached MetroCluster Cabling
Let's look at the NetApp MetroCluster Cabling for Fabric-Attached MetroCluster. The term “Fabric-Attached MetroCluster” means we are using Fibre Channel switches.
In the example here, we have our HA pair for our four node MetroCluster in Building 1:

That's Site 1 Controller 1 and Site 1 Controller 2. We also have our HA pair in Building 2. That's Site 2 Controller 1 and Site 2 Controller 2:

The next thing we're going to look at is our disk shelves. Over in Building 1, we have the Aggregate 1 Plex, which is owned by Site 1 Controller 1:

We have the SyncMirror Plex (Plex 1) for Aggregate 1 located in the other site, which is again owned by Site 1 Controller 1:

We are also going to have a second aggregate, Aggregate 2 Plex 0, which is owned by Controller 2 in Site 1:

… and we have the SyncMirror Plex (Plex 1) for that aggregate over in Site 2:

Then we have a third aggregate, Aggregate 3 Plex 0, which is in Site 2 and is owned by Site 2 Controller 1:

… and we have Plex 1 for that, which is in Site 1. Again, both Plexes are owned by Site 2 Controller 1.

Finally, we have Aggregate 4, which is owned by Site 2 Controller 2.

Plex 0 is in Building 2 and Plex 1 is in Building 1:

In the example above, I've used four aggregates and I've got a single stack of disk shelves in both sites. That's just to make the diagram really clear and easy to understand. You can have as many aggregates as you want and you can also have multiple stacks in the different sites if needed.
The next thing to look at is the ATTO Fibre Bridges.
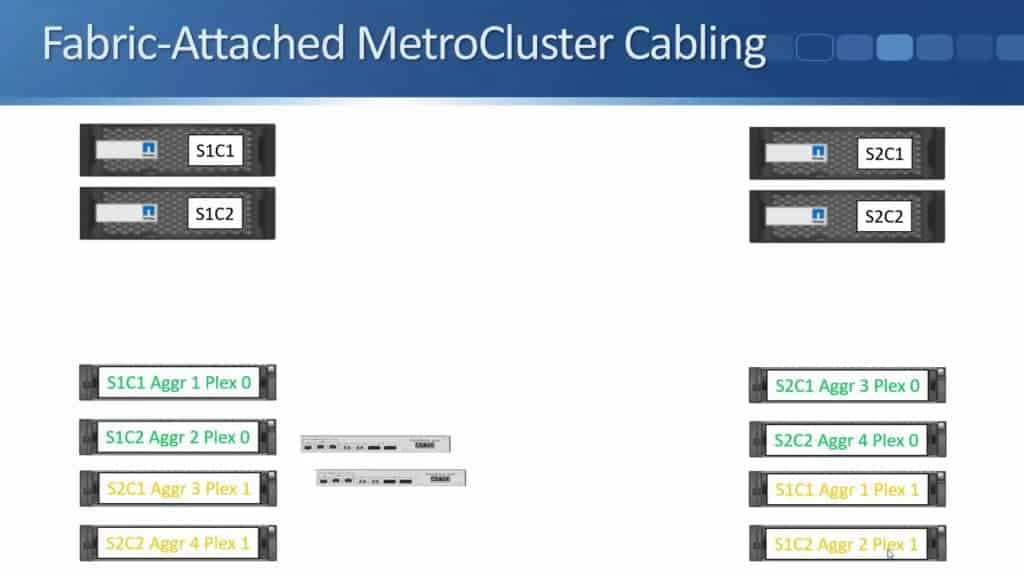
We're going to cable these up to our disk shelves using SAS cables. In Site 1, Fibre Bridge 1 gets connected to the top shelf in the stack.
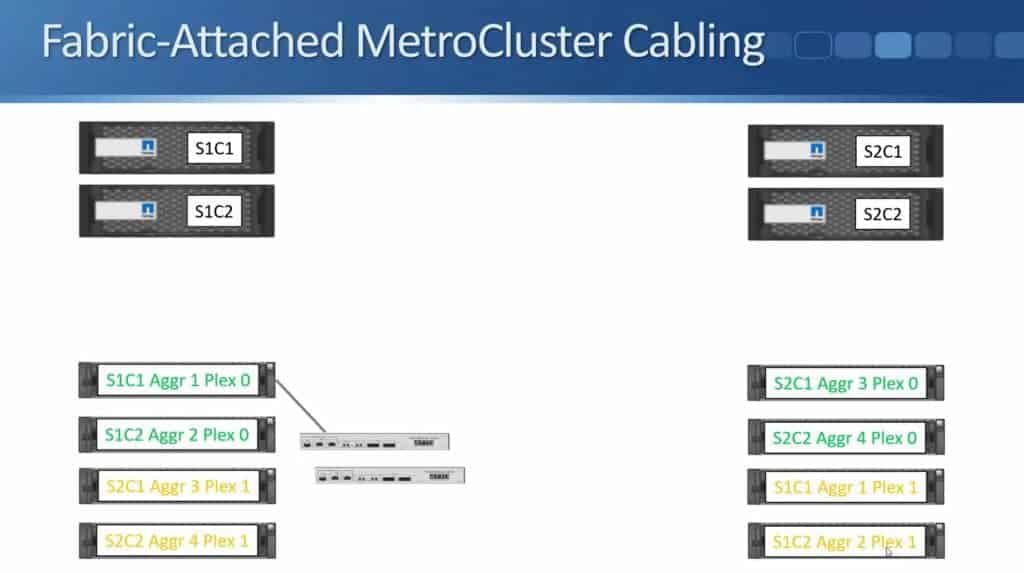
We then daisy chain the shelves going down from there:
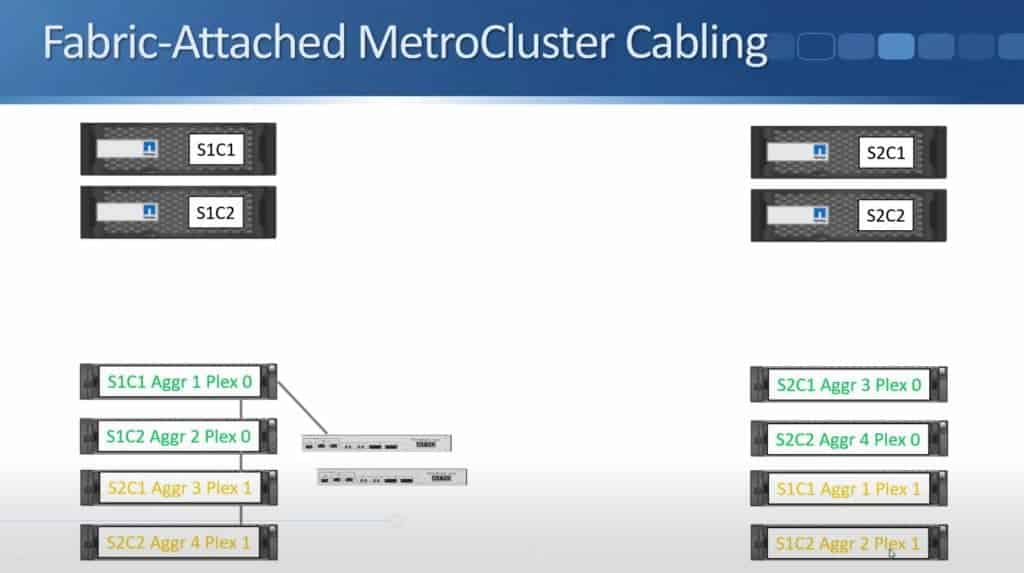
… and then Fibre Bridge 2 is connected to the bottom shelf in the stack.
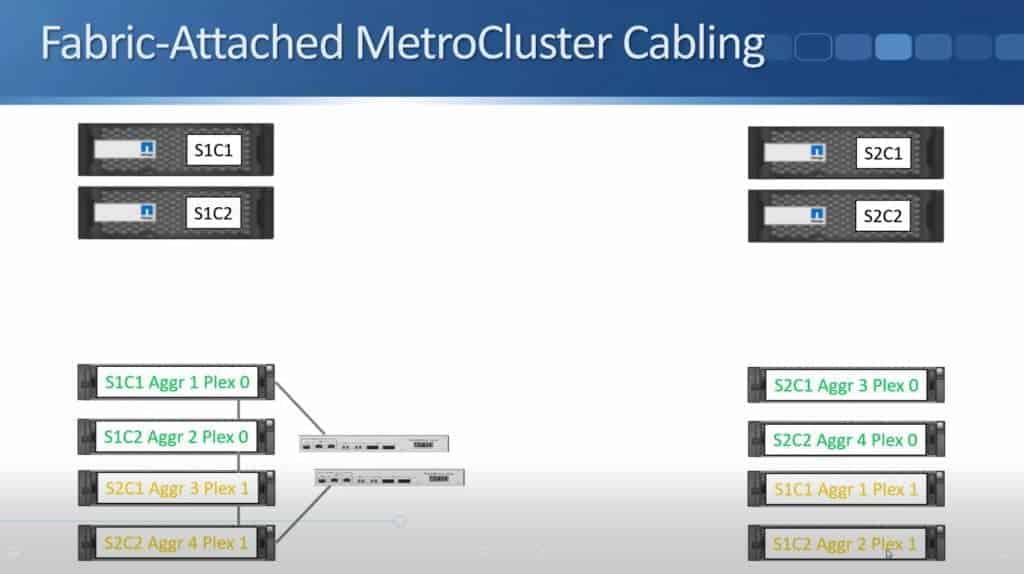
Once that’s done in Site 1 I also do a matching configuration in Site 2.
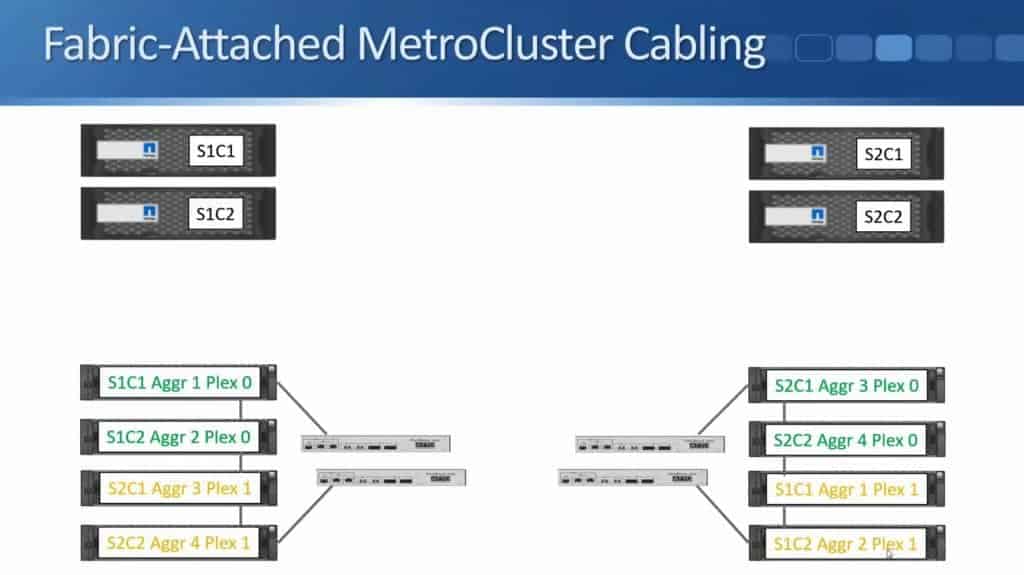
The next thing that we need is our Fibre Channel switches.
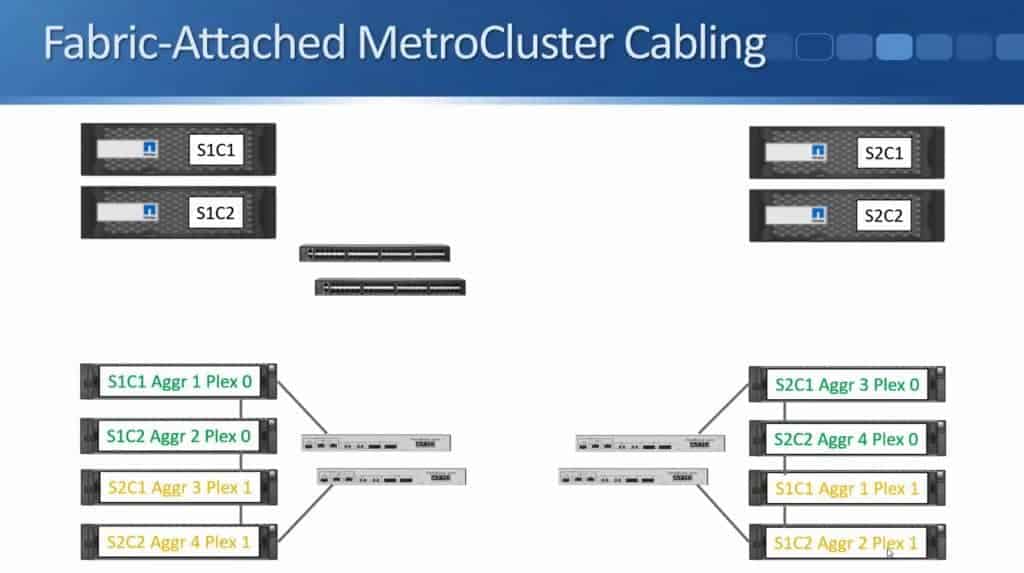
These are going to either come from Cisco or from Brocade. Fibre Channel Switch 2 gets connected to Fibre Bridge 2 and Fibre Channel Switch 1 gets connected to Fibre Bridge 1, using Fibre Channel cables.
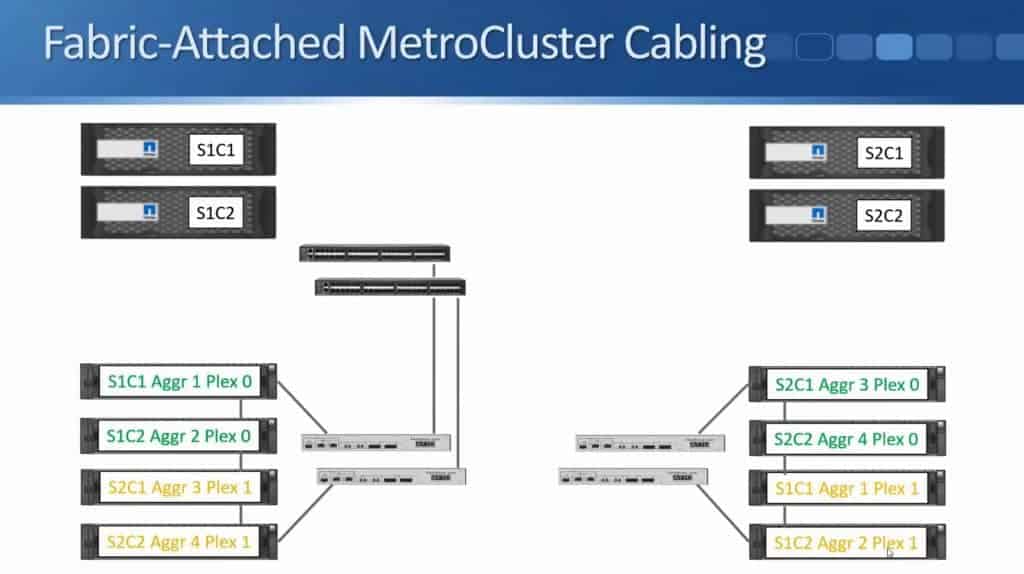
I've got my Fibre Channel switches in Site 1, and I'm also going to have a similar setup in Site 2.
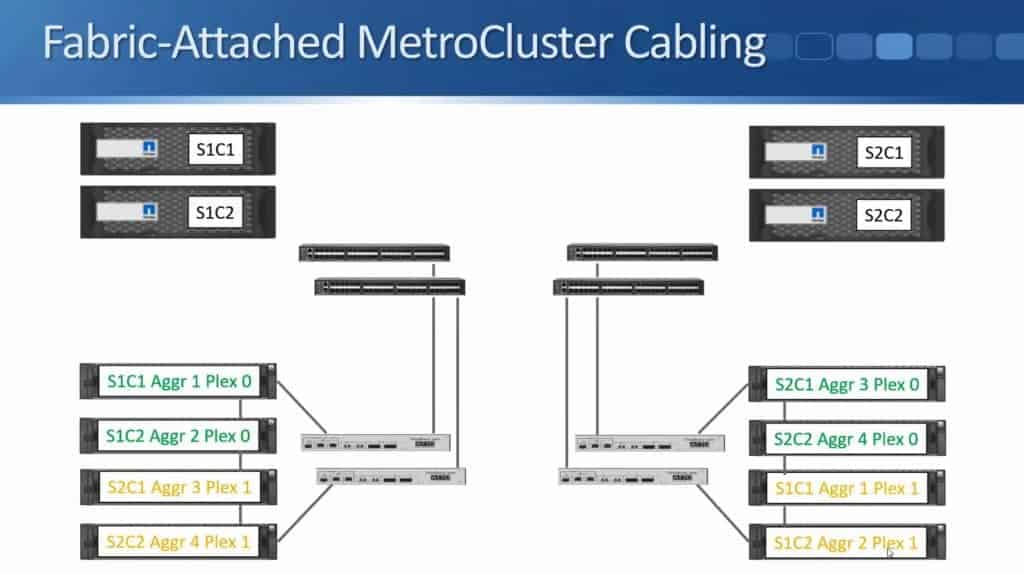
The next thing to do is to cable my controllers to my Fibre Channel switches, using Fibre Channel cables again. Site 1 Controller 1 gets connected to the first Fibre Channel switch and it also gets connected to the second Fibre Channel switch.
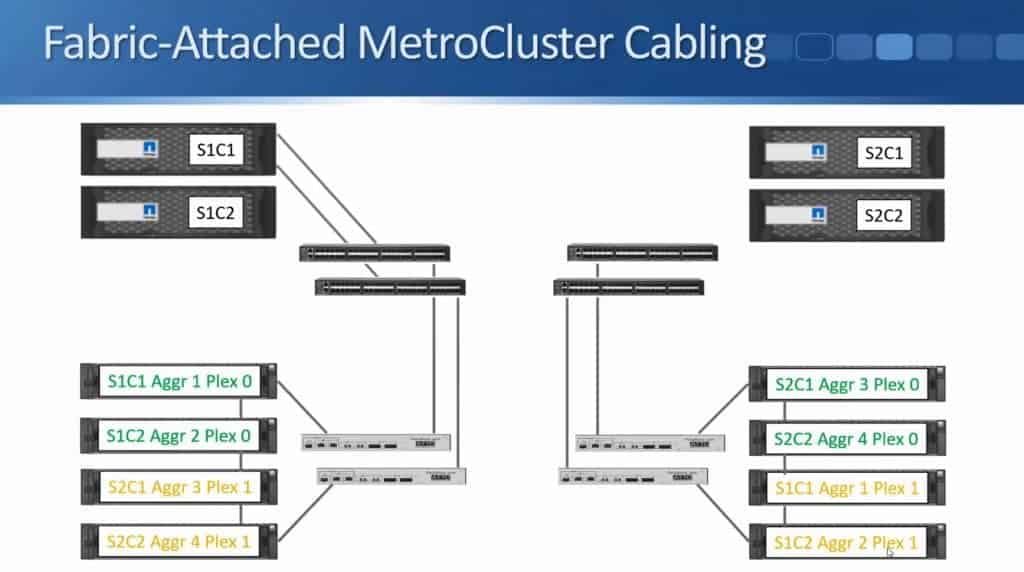
I do the same for Site 1 Controller 2 - it also gets connected to both switches.
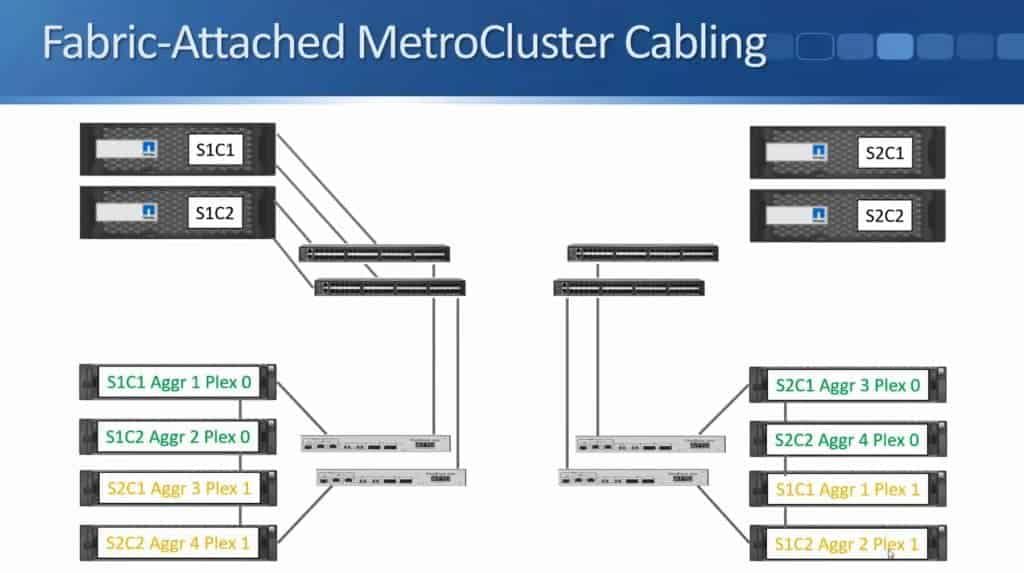
In the diagram above, I only showed one connection to make it tidier in the diagram. There's actually two connections from each node to each switch.
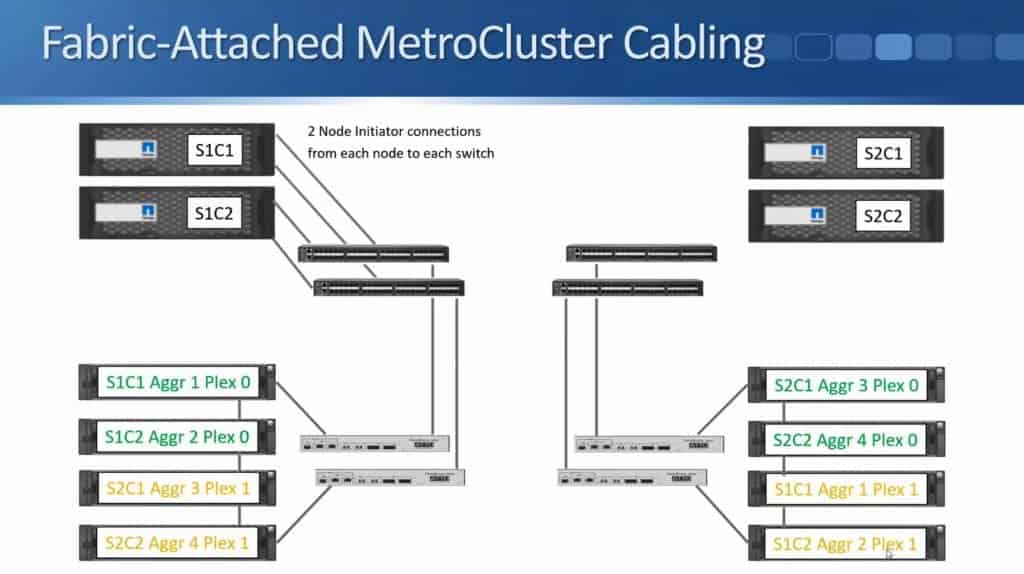
These are your Node Initiator connections, which give the controllers connectivity over Fibre Channel to the disk shelves on both sides.
I'll also configure similar connections in Site 2.
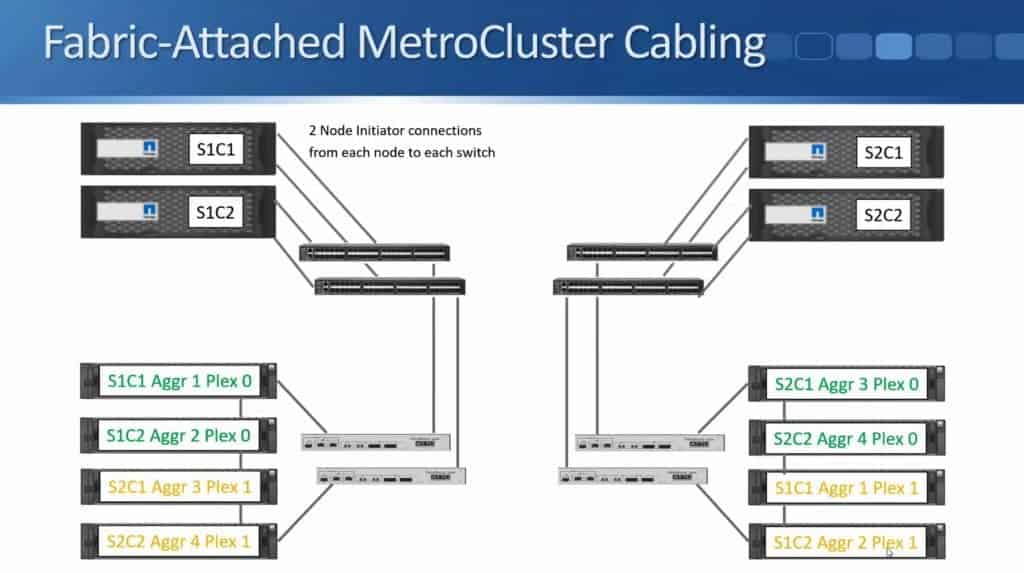
That gives my controllers connections to the disk shelves in the same site, but because we're using SyncMirror to write to both locations they need to have connections to the disk shelves in both sites. This is why I also connect my Fibre Channel switches together. Fibre Channel Switch 1 in both sites get connected to each other. I also connect Fibre Channel Switch 2 from both sites to each other.
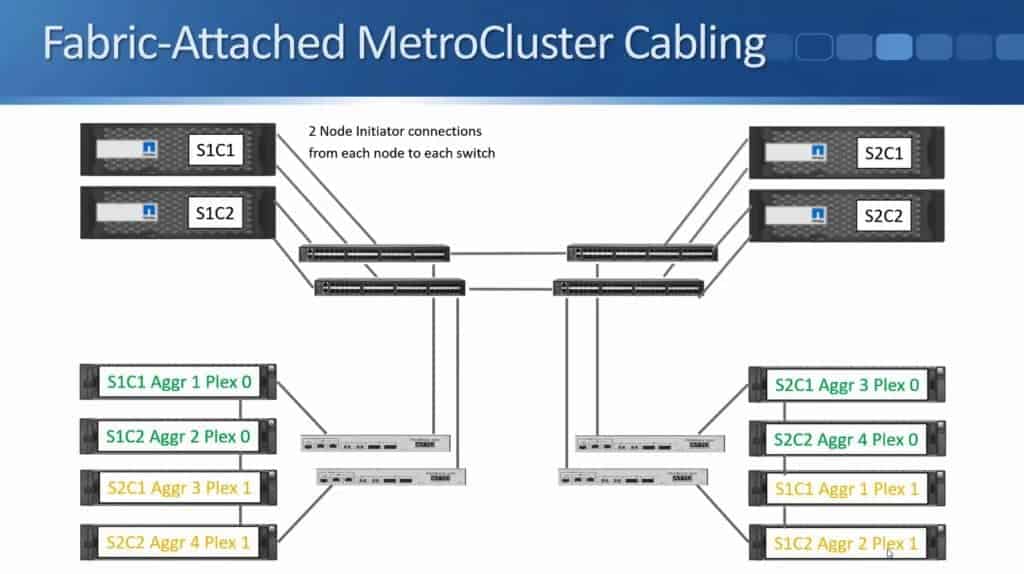
Again, I'm just showing one connection there, but you can actually have up to four connections between each pair of switches bundled into a port channel. If you have a look at the diagram, you'll see there's no single points of failure. I've got two controllers in each site, which are configured as an HA pair for each other. I've got two Fibre Channel switches in each site, two Fibre Bridges in both sites, and my aggregates are SyncMirrored across both sites as well.
FC-VI Fibre Channel Virtual Interfaces
We're not quite done with the cabling yet, though. The cabling in the previous diagram showed the Node Initiator connections from the controllers to the disk shelves in both sites for reading and writing to disk during Consistency Points.
Writes still work in the same way as usual though, where they are written to NVRAM before being written to disk. NVRAM mirroring also takes place over the Fibre Channel network between both sites. Separate 16-Gbps Fibre Channel Virtual Interface (FCVI) connections from the controllers are used.
These get connected into the Fibre Channel switches again:
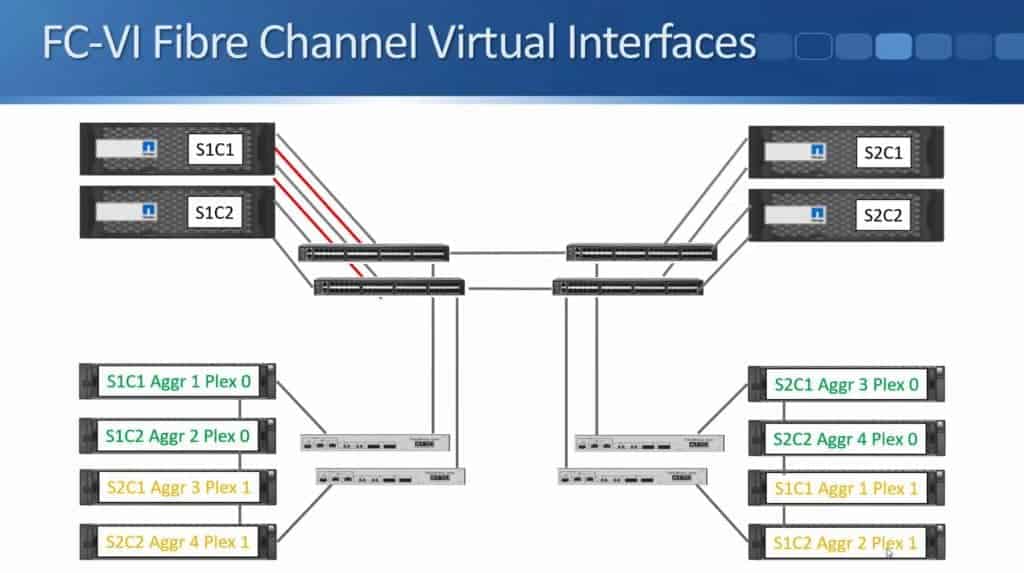
At this point, I have an FCVI connection from each controller going to both Fibre Channel switches on the same site. Those are the connections for Site 1 Controller 1. I do the same for Site 1 Controller 2:
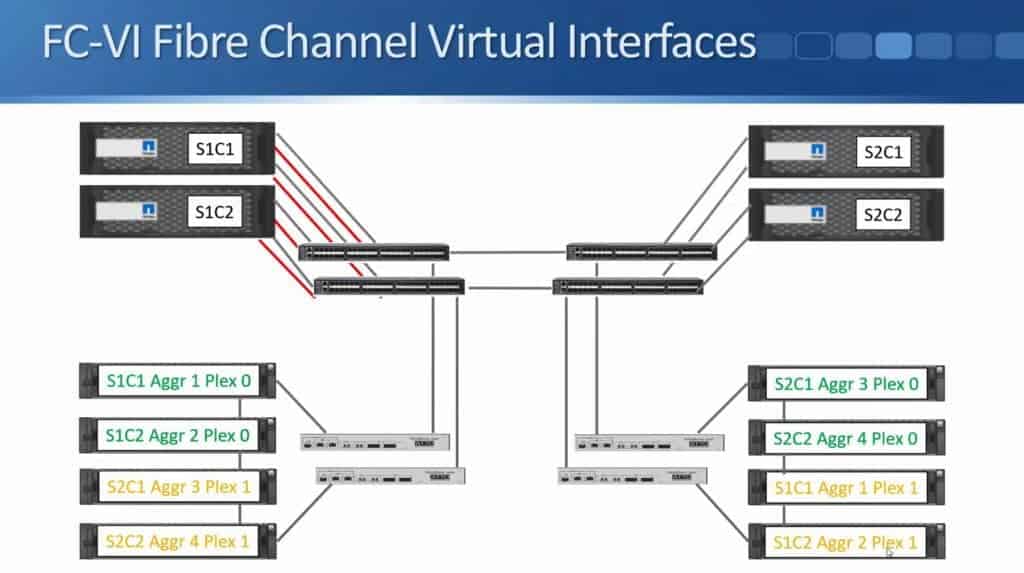
… as well as for the two controllers in Site 2.
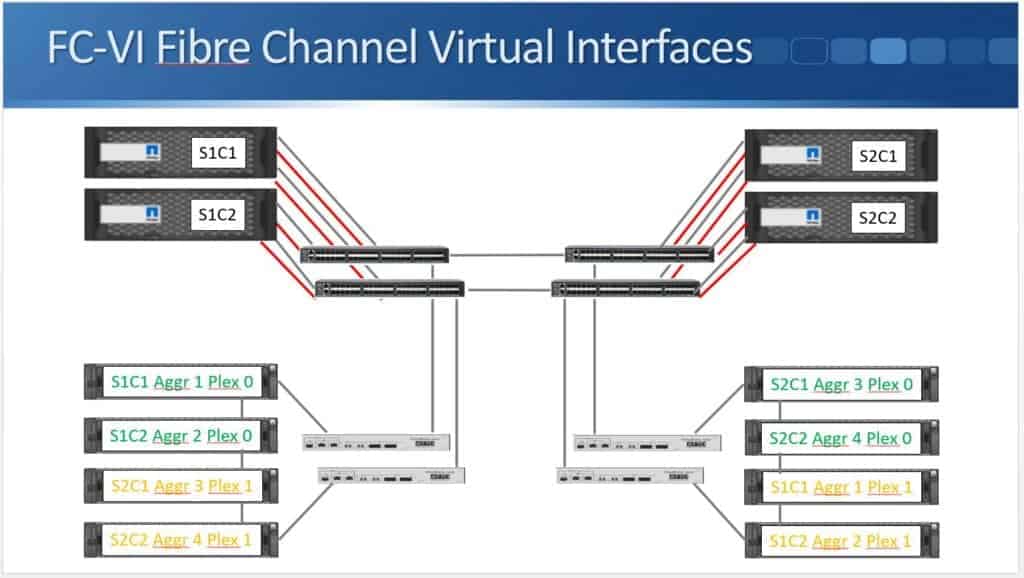
For the Node Initiator connections (for our reads from disk and for our writes during Consistency Points) we've got two Node Initiator connections from each node to each switch.
For the FCVI connections, which are used for the initial NVRAM mirroring between the two sites, we've got a single connection from each controller going to both switches in the same site. The Node Initiator connections can use a standard Fibre channel port on the controller. The FCVI connection has to use a dedicated 16 G connection.
Configuration Replication Service
SVM, LIF, volume, and LUN configuration information is replicated between the two sites using CRS, the Configuration Replication Service. CRS replicates over a standard IP network, using cluster peering and inter-cluster Logical Interfaces (LIFs), just like our SnapMirror traffic.
We've got three different types of connections on our controllers. We've got the Node Initiators for connectivity to our disks going over Fibre Channel. We've got the FCVI for the NVRAM mirroring, which also goes over the same Fibre Channel network. Finally we've got the CRS connectivity, which uses Inter-cluster LIFs going over an IP network.
Client Connectivity
Cluster identity is preserved during a switchover from one site to another. If a site fails, clients connect to the same IP addresses or WWPN's they were using before at the original site. The client data network must therefore span both sites.
Due to the fact that clients connect to the same IP address, the same layer 3 subnet has to be available on both sites. You can use dark Fibre, an MPLS layer 2 VPN service, or a proprietary solution such as Cisco Overlay Transport Virtualization for client protocols running over IP, like NAS or iSCSI, or a SAN fabric that spans both sites for Fibre Channel.
NetApp MetroCluster in ONTAP 8.3.1
As previously mentioned, NetApp MetroCluster for Clustered ONTAP came out in version 8.3.0. It only supported four node clusters in that original implementation. When ONTAP 8.3.1 came out, it added support for two node MetroCluster.
With two node NetApp MetroCluster, both sites host an independent single node cluster and, of course, the sites can switch over in case of a failure. There are three different supported two node configurations. We've got Stretch MetroCluster, Stretch MetroCluster with SAS Bridges, and Fabric MetroCluster. We're going to look at each of those in turn.
Stretch MetroCluster
First up there’s Stretch MetroCluster. In two node Stretch MetroCluster, the controllers are cabled directly to the disk shelves with NetApp proprietary long reach SAS cables. Fibre Channel switches and ATTO Fibre Bridges, like the ones we used in Fabric MetroCluster, are not used or required. The maximum distance here, due to the use of SAS cables, is not as long as Fibre Channel. It's only up to 500 metres.
Looking at the diagram below, you'll see it's very similar to a standard High Availability setup.
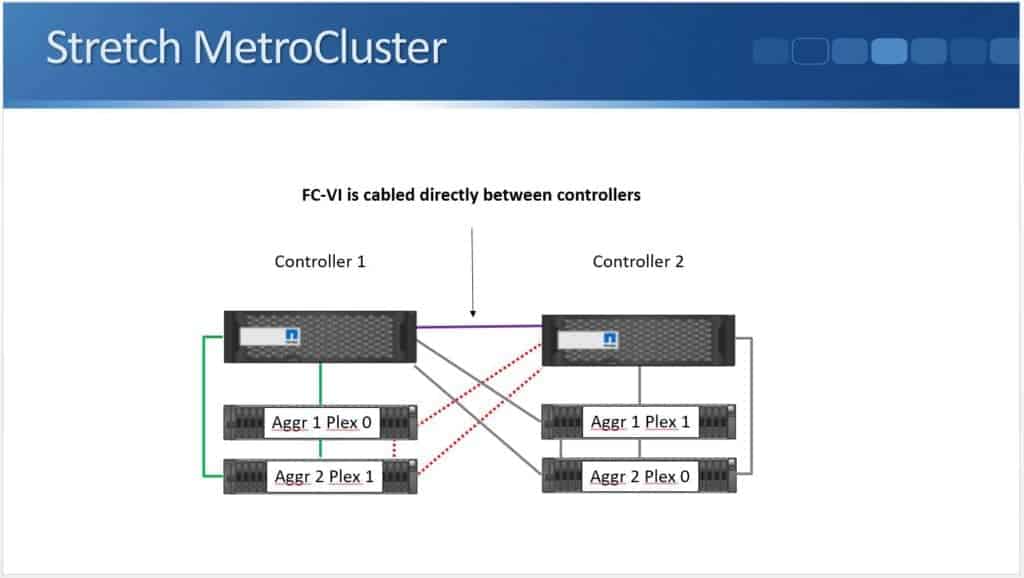
The controllers are connected to the disk shelves using SAS cables. The difference being rather than using the standard HA connection for the NVRAM mirroring, we have a Fibre Channel VI connection. It's cabled directly between Fibre Channel ports on the controllers.
Stretch MetroCluster with SAS Bridges
The next type of two node NetApp MetroCluster that's available is Stretch MetroCluster with SAS Bridges. Here, the controllers are not cabled directly to the disk shelves, but rather via ATTO Fibre Bridges. The controller to Fibre Bridge connection uses Fibre Channel. Fibre Channel switches are not used here, as they are in Fabric MetroCluster. Again, given we don't have those Fibre Channel switches, the maximum distance is 500 metres.
In the diagram below, you can see that the controllers have a single Fibre Channel connection to the ATTO Fibre Bridge in both sites and the ATTO Fibre Bridge then has a SAS connection going to the disk shelf.
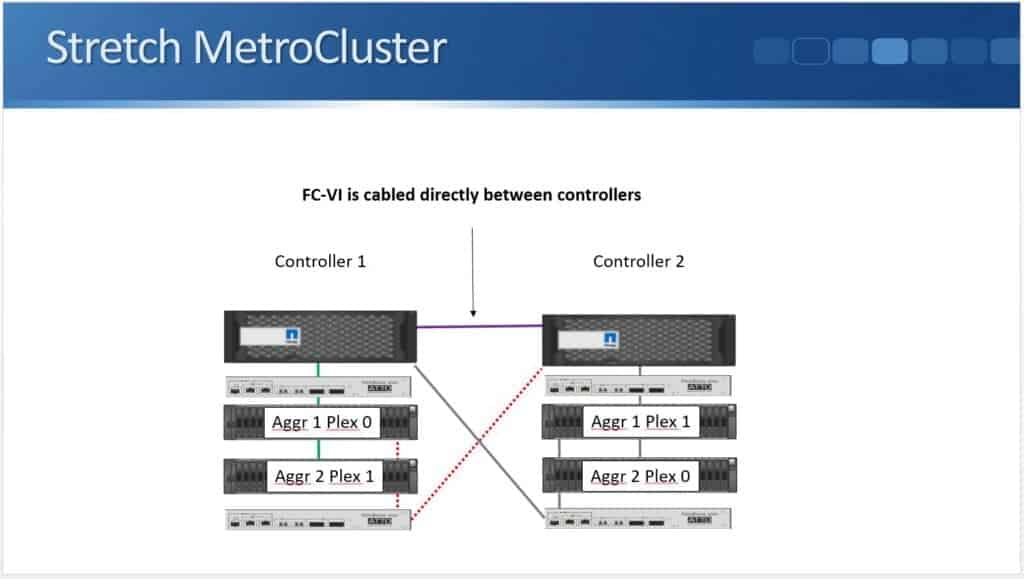
Those SAS connections are then daisy-chained down through the stack. Again, we have the FCVI connection for the NVRAM mirroring between the two controllers.
Two Node Fabric MetroCluster
The last type of two node NetApp MetroCluster we have is two node Fabric MetroCluster. The system is cabled the same way as the four node Fabric MetroCluster which was supported on 8.3.0, so it's very similar. The maximum distance here, though, is increased to 300 km rather than the 200 km limit.
Looking at the diagram below, you'll see it's nearly exactly the same as it was for the four node Fabric MetroCluster, but we only have one node in each site.
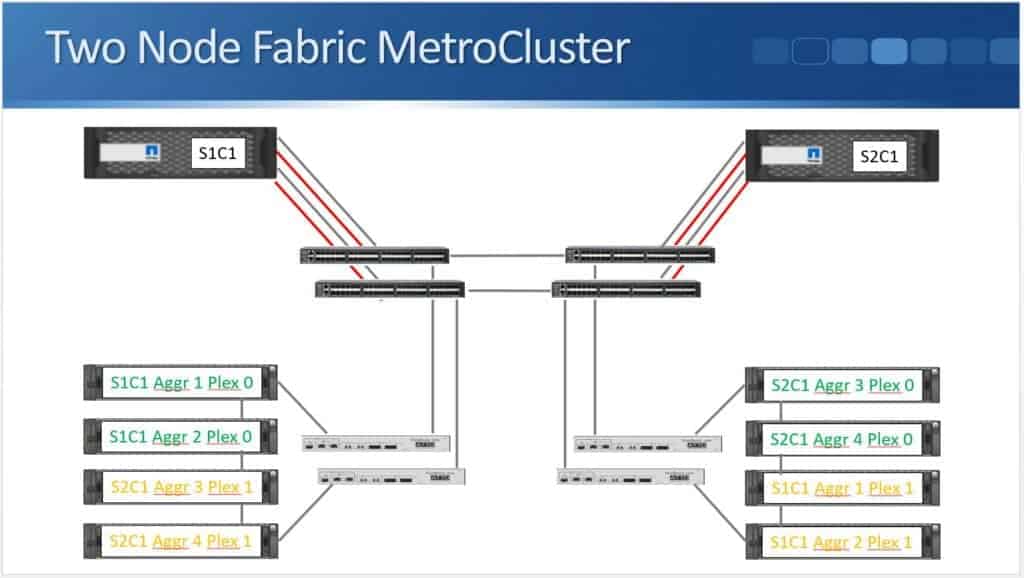
NetApp MetroCluster in ONTAP 9
We also had another improvement when ONTAP 9 came out. ONTAP 9 supports eight node Fabric MetroCluster. With the eight node configuration, we have two HA pairs located in both sites. Each HA pair is replicated to its secondary HA pair at the other site. The maximum distance is 200 km over Fibre Channel, but we can go up to 300 km if we use the new option of Fibre Channel over IP (FCIP).
Switchover
Let's now look at what we would do if we actually lost a site. If a node undergoes a panic in a two node NetApp MetroCluster, then automatic switchover will occur. We would definitely want a switchover in that situation, which is why it happens automatically.
In other cases, switchover occurs manually or through the use of MetroCluster Tiebreaker software. This is to prevent a split brain scenario, where both sites lose connectivity with each other and assume the primary role for all aggregates.
We need to avoid this split brain scenario at all costs, because it would lead to different data being written to the Plexes for the same aggregate in both sites. Clients in Site 1 would be writing to Aggregate 1 in their site. Clients in Site 2 would be writing to their Plex for Aggregate 1 in Site 2. As a result, we would have two different, inconsistent copies of the data in the same aggregate. We need to make sure that doesn't happen.
Split Brain
The situation that would lead to a split brain would be where both sites are up, but they lose connectivity to each other.
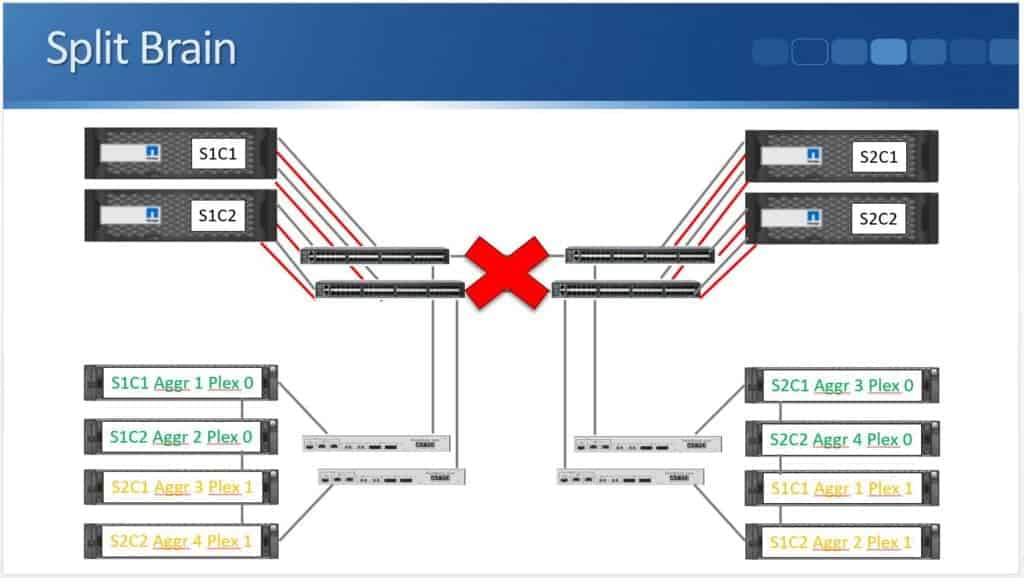
This is why switchover doesn't happen automatically by default. Normally each site wouldn't know if it losing connectivity with the other site was due to the site going down or just the network connection going down.
Manual Switchover
The first way that we can initiate a switchover is by doing it manually. Here, the administrator verifies that a site really has gone down and needs to switch over to the other site. The command to use is “metrocluster switchover”. If we enter the command while both sites are still available, this will perform a graceful, negotiated switchover. You would do this if you wanted to take a site down for maintenance.
The other command we can use is “metrocluster switchover -forced-on-disaster true”. We use that to force a switchover when a site has actually failed. The issue that you might have with doing a manual switchover is that it is going to take some time for the administrator to learn that a site has gone down, to verify it, and then to manually enter this command. You might want to speed things up.
NetApp MetroCluster Tiebreaker
We can automate the switchover by using MCTB; the MetroCluster Tiebreaker. This is a Red Hat Java application that runs in a third site which has got connectivity to both clusters. It's used to independently monitor both sites, and it will send SNMP alerts if issues are detected. It can also be configured to automatically switch over in the case of a site failure. The Recovery Time Objective (RTO) is 120 seconds for automatic switchover when using MCTB.
The way it works is it establishes SSH Secure Shell sessions with each node's node management IP address to verify that they're up. If the SSH session to a node goes down, MCTB will first check the HA status within the site to see if it's just that one node that has gone down and that it's failed over to the HA pair in the same site. If it can't reach either node of an HA pair, then they'll both be declared unreachable.
At this point, how do we know that it's not just the network from the third (MCTB) site to the first MetroCluster site that's gone down? We need to double check it. MCTB will ask the second MetroCluster site via SSH if it has connectivity over the FCIV connection or the inter-cluster IP network to the first site.
If the second MetroCluster site also reports that it’s lost connectivity to the first site, we can be pretty sure that first site is actually down. At this point you can configure MCTB to only send you an alert, or you can also configure a rule which will cause an automatic switchover.
NetApp MetroCluster Interoperability
The last thing to tell you about is MetroCluster Interoperability with the other data protection technologies. It can be used in conjunction with SnapMirror and SnapVault. For example, MetroCluster could be used to provide synchronous replication between two sites within 300 km, and SnapMirror could be used to asynchronously replicate the same data to a third site with no distance limitation.
Let’s say we've got a site in New York and we've also got a site in Philadelphia. They're within a couple of hundred kilometres of each other, so we could use MetroCluster to get synchronous replication between those two sites with an RPO of 0. Maybe we're worried that we're going to have a regional disaster, like flooding affecting the entire East Coast of the U.S. In that case, we could also use SnapMirror to replicate the data asynchronously to London.
As well as SnapMirror, MetroCluster can also integrate with SnapVault, so the data could also be backed up off-site with no distance limitation using SnapVault Backup.
Additional Resources

Text by Alex Papas, Technical Writer at www.flackbox.com
Alex has been working with Data Center technologies for over 20 years. Currently he is the Network Lead for Costa, one of the largest agricultural companies in Australia. When he’s not knee deep in technology you can find Alex performing with his band 2am