
In this NetApp training tutorial, we will focus on NetApp storage architecture. The NetApp storage architecture is organised into disks, aggregates, RAID groups, volumes, Qtrees and LUNs. Scroll down for the video and also text tutorial.
The NetApp Storage Architecture – Video Tutorial

Matthew Roberts

I have been watching your videos for the past year now and last week I took and passed my NCDA exam. I just wanted to drop you a quick email to thank you. Your videos were a tremendous help!
Disks and Aggregates
At the bottom level of the storage architecture we have our physical disks - our hard drives. Our disks get grouped into aggregates, so an aggregate is a set of physical disks. One of the attributes of our aggregates is the RAID group which defines the RAID configuration.
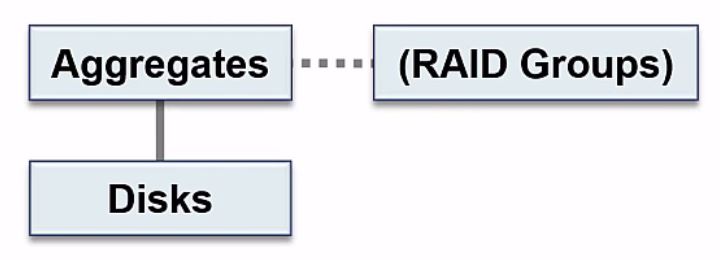
NetApp Storage Architecture - Disks, Aggregates and RAID Groups
If you look in the System Manager GUI, you will see that there is a page for disks where you can view all of your disks, and there's a page for aggregates, where you can view and configure your aggregates. There's not a page for RAID groups however. The reason for that is your RAID groups are an attribute of your aggregates, so your RAID groups are configured on the aggregate page.
Volumes
The next level we have moving up is our volumes. You could have multiple volumes in the same aggregate, or maybe just one volume in the aggregate. Volumes are the lowest level that clients can access data at, so you will always have disks, aggregates and volumes on a NetApp ONTAP system. You can share (for Windows) or export (for UNIX/Linux) a volume and then clients can access it.
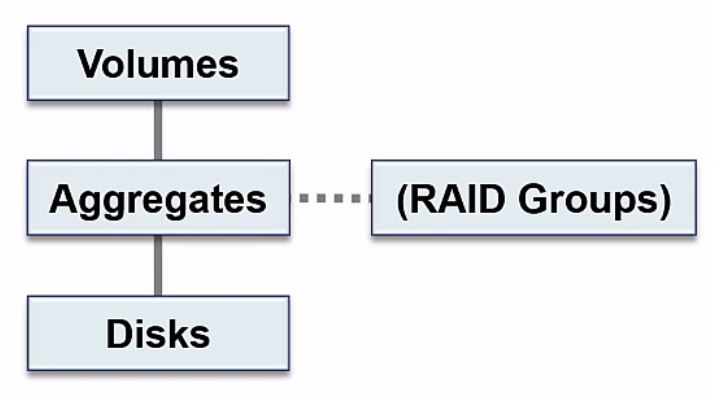
Your disks and your aggregates are classified by NetApp as physical resources, and volumes are classified as logical resources.
Qtrees
Moving up the next level above volumes, we have our Qtrees which go in volumes. Qtrees are an optional component. If the containing volume is being accessed by a NAS client, it will see the Qtree as a directory in the volume. Qtrees can also be shared or exported directly themselves.
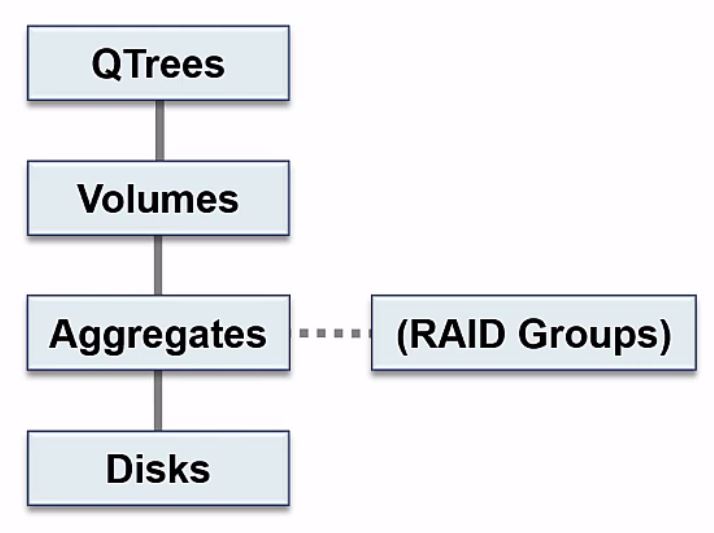
They’re called Qtrees because one of their main functions is for quotas. You can limit the total size that the Qtree itself can grow to, or limit the amount of space that a user or group can use in the Qtree.
LUNs – Logical Unit Numbers
The last component we have in the storage architecture is our LUNs, our Logical Unit Numbers. A LUN is specific to SAN protocols, and is the storage container that SAN clients use for their storage. The LUNs can either go in a Qtree or a volume. Best practice is to have a dedicated volume or Qtree for each LUN (do not put multiple LUNs in the same volume or Qtree).
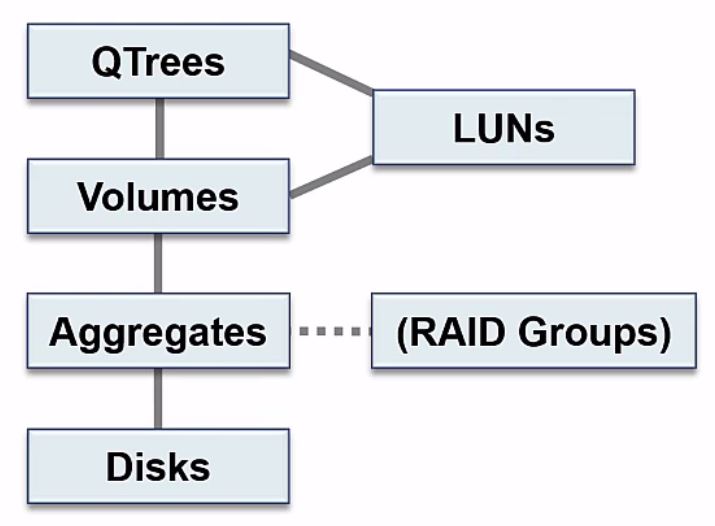
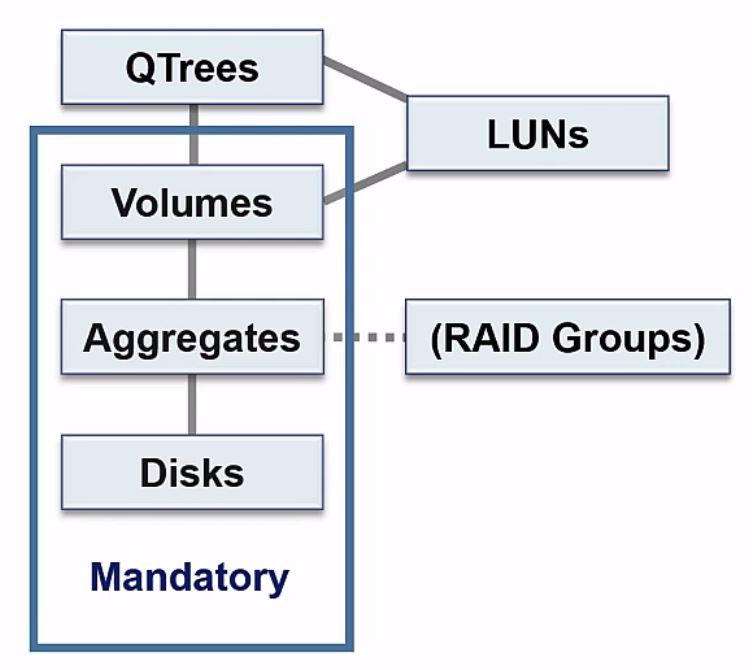
NetApp Storage Architecture Organisation
You can see the different components build on top of each other. We need to have our physical disks. Our disks get grouped into aggregates. For our clients to be able to access data we configure our volumes, which go in our aggregates, and optionally we can configure Qtrees which go in our volumes and appear as a directory to NAS clients.
Lastly, if we're using SAN protocols we'll need to configure LUNs. Our LUNs either go into a Qtree or into a volume.
The mandatory components are the disks, aggregates, and volumes. Qtrees are optional, and LUNs are for SAN Protocols only - you wouldn't have LUNs if you were using only NAS protocols.
SVM Storage Virtual Machines
The other storage architecture component to tell you about is Storage Virtual Machines (SVMs). These used to be known as Vservers, but they were renamed to SVMs in a more recent version of ONTAP. ‘Storage Virtual Machine’ and ‘Vserver’ both mean exactly the same thing.
If you're working in the System Manager GUI, you'll see they're listed under Storage Virtual Machines. If you're doing your configuration in the CLI the commands still use the ‘vserver’ syntax.
SMV Use Cases - Multitenancy
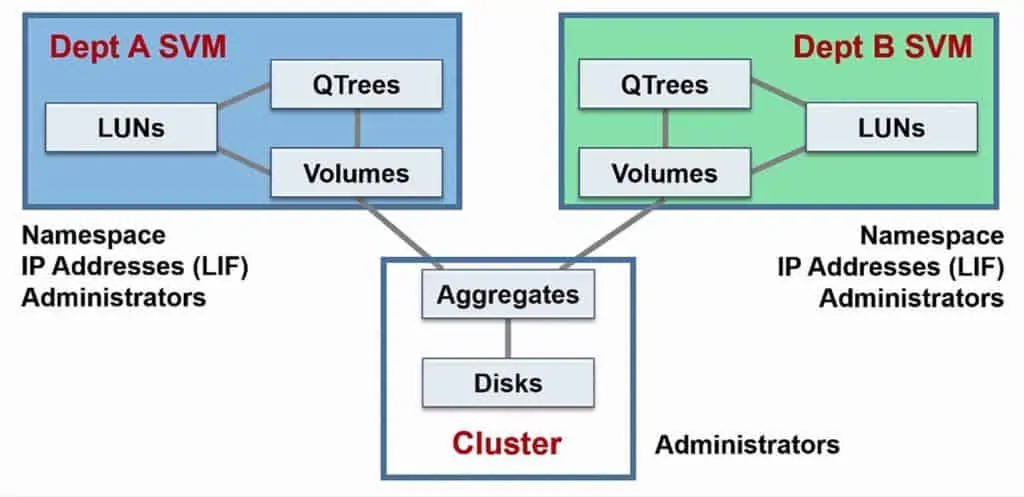
Say that you've got two different departments - Department A and Department B. They want to have their own separate secure storage. In the old days, what you would have to do is buy two completely separate storage systems, and you would require separate supporting network infrastructure for them as well. This would be pretty expensive.
What you can do with NetApp ONTAP and Storage Virtual Machines now, is you can have one physical storage system, but you can virtualize it into separate logical storage systems, which are kept secure and separate from each other. Each SVM appears as a separate storage system to clients.
The physical resources of our disks and our aggregates are shared throughout the entire cluster, they’re not dedicated to individual SVMs. The reason for this is if we had dedicated aggregates, maybe the aggregate for department A is pretty empty, and the aggregate for department B is getting really full.
If the aggregates were dedicated at the SVM level, you would have to go and buy more disks for department B, even though you've got spare disks on Department A. Aggregates are a shared resource to ensure we get the most efficient use of our capacity.
Volumes are dedicated to and belong to a particular SVM. If department A has got volume A, it's owned by department A, and department B cannot see it. Other resources that are dedicated to and owned by particular SVMs are its name space (the directory structure of the SVM), its Logical Interfaces (LIFs, which are where our IP addresses live).
The SVMs can have their own separate SVM level dedicated administrators with different usernames and passwords. SVM level administrators have no visibility of the other SVM, they can’t even see it exists. Global cluster level administrators can administer both SVMs.
In our example the Department A SVM will have its namespace, volumes, Logical Interfaces and administrators, and the Department B SVM will have its own separate namespace, volumes, Logical Interfaces and administrators.
SMV Use Cases – Multiple Client Access Protocols and Cloud Environments
Another common reason for configuring separate SVMs is for ease of administration of multiple client access protocols. You could run NFS, CIFS and iSCSI for example all in the same SVM. In this case it will appear to all clients that they are accessing the same storage system. Or you could configure separate SVMs for each protocol, in which case they will appear as separate storage systems. Both configurations are supported.
SVMs are also very useful in a cloud environment, where we can have separate SVMs for different customers.
If you don't need to configure separate logical Storage Virtual Machines in your enterprise, you’ll still have at least one SVM. SVMs are an integral part of the NetApp storage architecture, they house our volumes and LIFs so they are a mandatory component for client data access.
Additional Resources
ONTAP storage architecture overview from NetApp
Click Here to get my 'NetApp ONTAP 9 Storage Complete' training course.