
In this NetApp training tutorial, I will discuss NetApp High Availability on FAS controllers. Your storage system is almost certainly going to be a mission critical component in your environment so you don’t want to have any single points of failure. Controller redundancy is provided by the High Availability HA feature. Scroll down for the video and also text tutorial.
NetApp High Availability Video Tutorial

Ben Lilley

I just passed my NCDA and I owe many thanks to your in-depth, straight forward and enthusiastic content. Being able to see you teach all the features and functionality and then test them out myself was fantastic and helped the info sink in. The ability to come back to the content whenever I need a refresher on something complicated is extremely valuable. Whenever I hear of a new engineer looking to get their NCDA I always point them in your direction first.
NetApp ONTAP High Availability Architecture
The controllers in a NetApp ONTAP cluster are arranged in High Availability pairs. If we had a 6 node cluster for example, nodes 1 and 2 would be an HA pair, nodes 3 and 4 would be another HA pair, and nodes 5 and 6 would be our final HA pair. See my previous post for a full description of the NetApp ONTAP architecture.
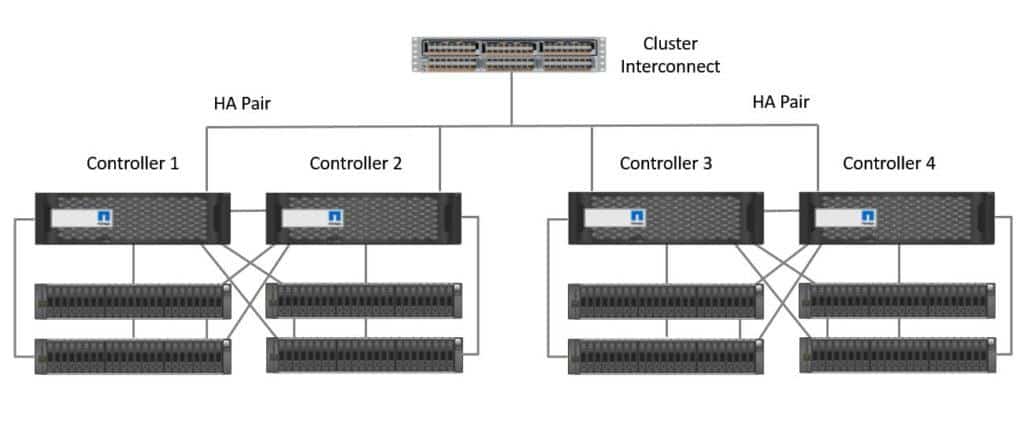
NetApp ONTAP clustered architecture
In our example below, Controller 1 and Controller 2 are High Availability peers for each other. Aggregate 1 is owned by Controller 1 and Aggregate 2 is owned by Controller 2. If you give clients connectivity to Logical Interfaces on both controllers, then they can access either aggregate through either controller. Traffic will go over the cluster interconnect if a client connects to an interface on a controller which does not own the aggregate.
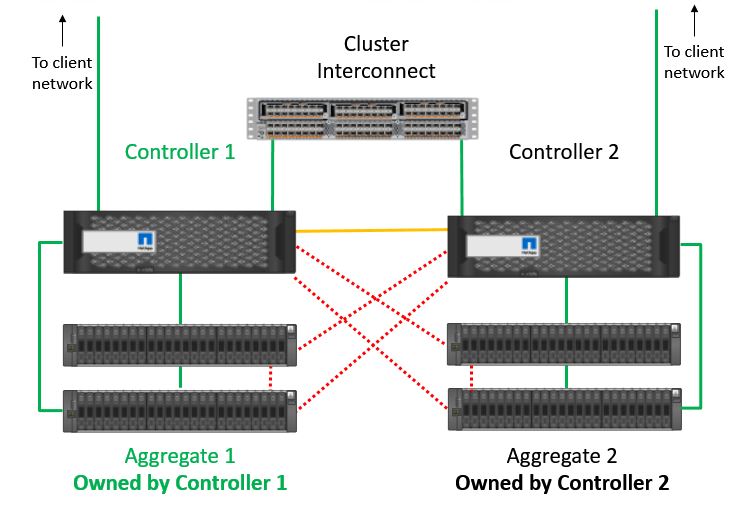
NetApp High Availability Architecture
The aggregate itself is always owned by only one controller. Both controllers are connected to their own and to their HA peer’s disks through SAS cables. The SAS cables are active-standby. We don’t load balance incoming connections over the SAS disk shelf cables, only over the cluster interconnect.
NetApp High Availability Walkthrough
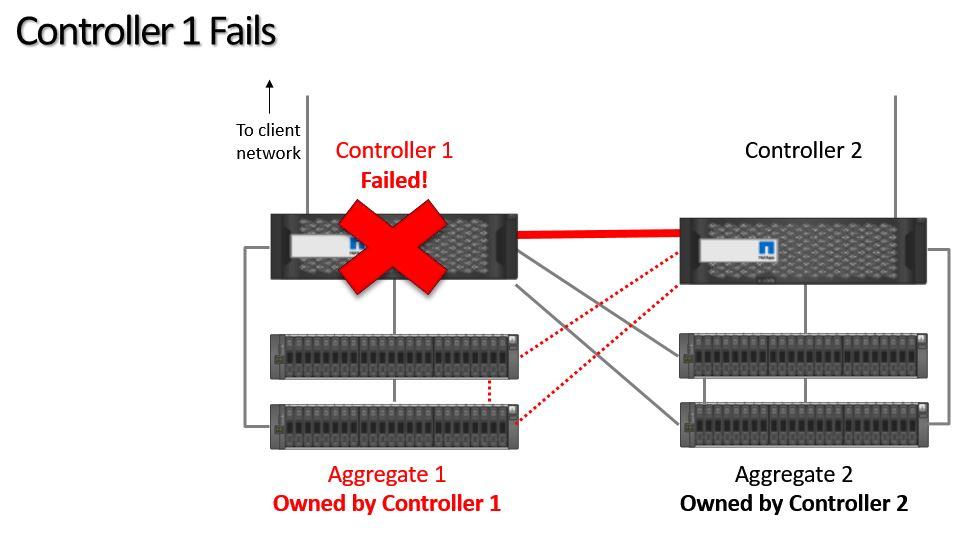
If Controller 1 fails, then Controller 2 will take temporary ownership of its aggregates.
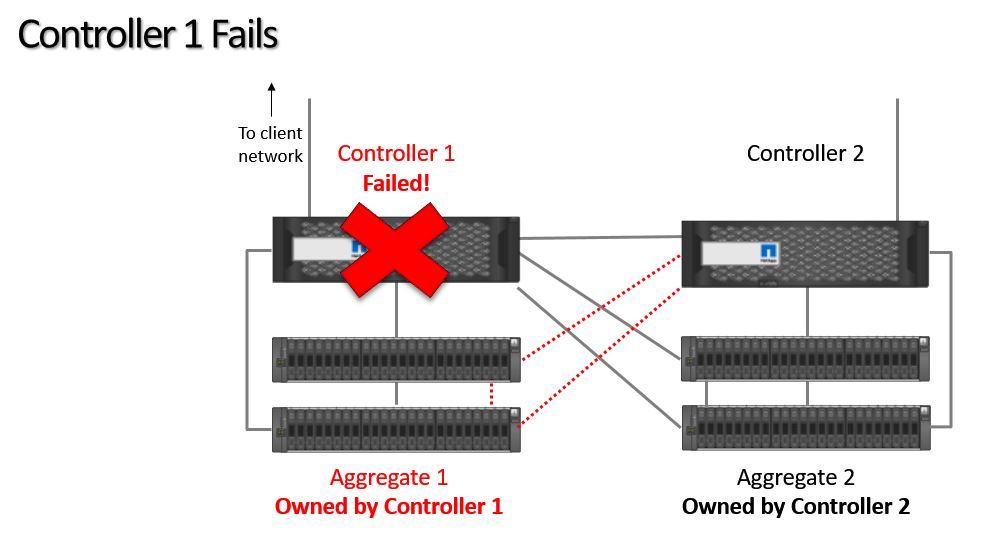
Controller 1 Fails
Controller 2 will take ownership of all of Controller 1's disks. All aggregates are owned by Controller 2 until Controller 1 is recovered and we can perform a giveback.
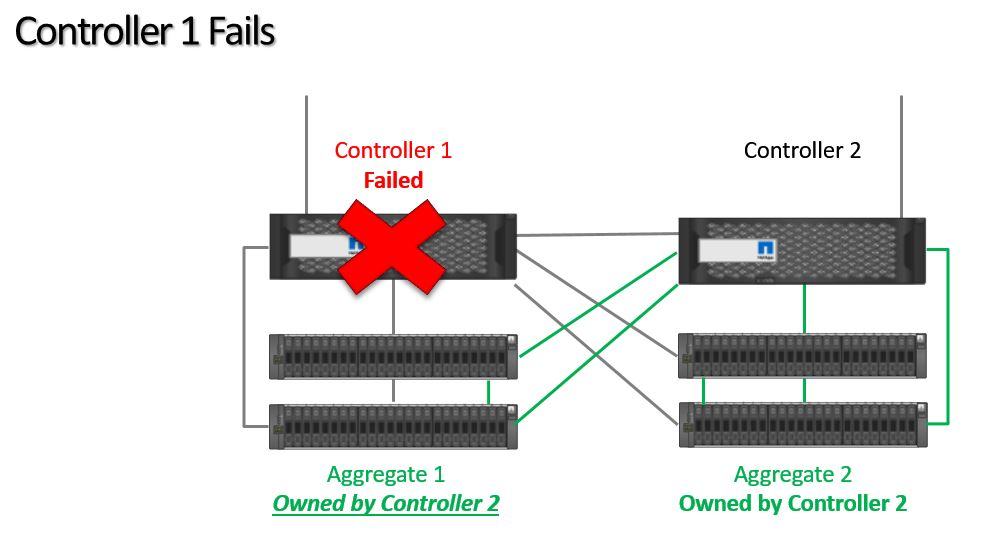
High Availability Takeover
There's a couple of different ways that Controller 2 can learn that it has to take ownership. The first is if it stops receiving keepalives over the HA connection:
Missed keepalives over HA connection
The second way is with Hardware Assisted Failover:
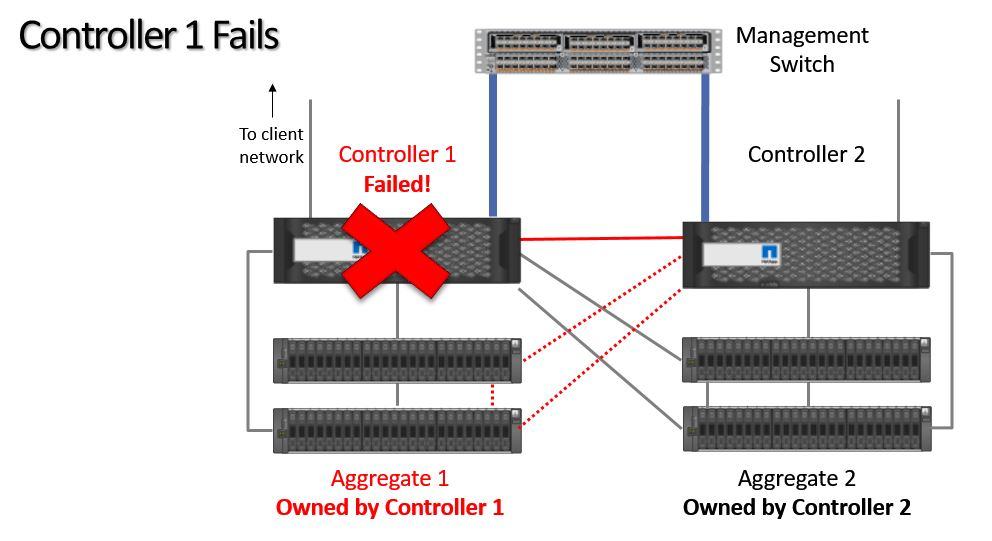
Hardware Assisted Failover
Hardware Assisted Failover
Hardware Assisted Failover is available when we configure the Service Processors on both controllers with an IP address. If Controller 1 fails but still has at least one power supply operable then the Service Processor will stay up. If it then sees that ONTAP has crashed, it will immediately signal across to Controller 2 telling it to take ownership of its disks. This is a quicker way to achieve failover because we don't have to wait for Controller 2 to detect missed keepalives.
Benefits of High Availability
High Availability provides the following benefits:
- Fault tolerance.
- Non-disruptive maintenance.
- Non-disruptive upgrades.
Fault tolerance: When one node fails or becomes impaired and a takeover occurs, the partner node will serve the failed node's data.
Non-disruptive maintenance: You can perform a graceful storage failover of a node that you want to perform hardware maintenance on and then power it off. The partner node will continue to serve data for both nodes while you perform the upgrade or maintenance.
When the upgrade or maintenance is finished, you perform a storage failover giveback to gracefully return the data service to the original node.
Non-disruptive ONTAP upgrades: When upgrading the ONTAP software version, nodes in an HA pair are gracefully upgraded and rebooted one after the other. The normal upgrade process automatically takes care of this for you. The partner node will continue to serve data for both nodes while the other node is being upgraded.
Aggregate ownership can be non-disruptively transferred between nodes in an HA pair with no need for takeover or giveback.
Sizing
When there is a takeover, the surviving node owns and serves the data for not only its own disks, but for both nodes in the HA pair. It is recommended to run a node at a maximum of 50% of its performance capacity under normal conditions. This way it ensures that clients will not experience a performance degradation during takeover events.
If we're only running up to 50% during normal operations when we failover and now we're serving the data for both nodes, we're still going to be under 100% of the capability so we'll still have acceptable performance.
Takeover Triggers
Takeovers occur under the following conditions:
- An administrator manually initiates a takeover with the command storage failover takeover
- An administrator shuts down or reboots a node
- A node undergoes a software or system failure that leads to a panic
- A node undergoes a system failure such as power failure and cannot reboot
CIFS Clients
We need to consider how a takeover is going to affect our CIFS or SMB clients. SMB is a connection oriented protocol so takeover is disruptive to these clients and some data loss could occur, because the takeover breaks the connection. Takeover will not be disruptive to Microsoft Hyper-V SMB v3 clients if the Continuous Availability property is set.
We can configure it so that it will not be disruptive to our Hyper-V servers but to our normal Windows clients running earlier versions of SMB without the Continuous Availability property available, it can be disruptive to them.
For NFS, there will still be an outage during the takeover but the client does not maintain a connection to be broken by the takeover event.
Giveback Implications
There will be a brief outage during a takeover. There will be a second brief outage during the giveback, so there's some implications with this.
Giveback occurs automatically after a node recovers from a panic or reboot and in all cases when the cluster is a two-node cluster. In those cases giveback is going to occur as soon as possible. During the outage all the load will be on one controller of the HA pair, but as soon as the failed node recovers the disk ownership will be given back. The load will be spread back across both nodes as soon as possible, however there will be a second brief outage during the giveback.
For all other cases an administrator manually initiates giveback with the command 'storage failover giveback'. The benefit we get from this is that we can plan when to do the giveback, so we can schedule it for a maintenance window to minimise disruption to our clients. The downside is that we will have all of the load on the surviving node until the giveback occurs.
Logical Interface (LIF) Failover and Giveback
The High Availability configuration ensures that your aggregates remain available in the case of a node failure. We also need to fail over the logical interfaces from the failed node so that clients can maintain connectivity to the NAS IP addresses during a takeover event.
The controller failover configuration and the interface failover configuration work hand-in-hand, but they're configured separately so you need to make sure you've got a working configuration for both.
High Availability Configuration
To configure High Availability, enter the commands below:
storage failover modify -mode ha -node nodename
storage failover modify -enabled true -node nodename
Switchless Two Node Cluster Configuration
There's a few extra commands that we need to configure if we're using a switchless two-node cluster:
cluster ha modify -configured true
set -privilege advanced
network options switchless-cluster modify true
The reason we have to do this is because of the concept of quorum. The quorum rule states that to make changes to the configuration in our cluster, we need to have more than half of the nodes available. This prevents configuration conflicts if we lose connectivity between the nodes in our cluster.
Quorum and Epsilon
For example, let's say we've got an eight-node cluster and nodes 1 to 6 lose connectivity with nodes 7 and 8. If we try to make changes on the side with nodes 1 to 6, this will be allowed because more than half the nodes in the cluster are available. We wouldn't be allowed to make changes to the configuration on nodes 7 and 8 however because they see less than half the nodes available. It's impossible to have more than half of the nodes available on two different sides at the same time. This makes sure that we can't create a conflict by creating two different configurations.
One of the nodes in the cluster is automatically elected the ‘Epsilon’ node to provide a tie-breaker for cases where we've got an exact half and half split. Let's use the 8 node cluster as an example again but this time nodes 1 to 4 have lost connectivity with nodes 5 to 8. If node 1 was our Epsilon node, then we could make changes on the side with nodes 1 t0 4, but not on the side with nodes 5 to 8.
This gives us a problem with two-node clusters because if we have an outage of one of our controllers, then we're down to half of the nodes being available. If the surviving node was not the Epsilon node then we wouldn't be able to make any configuration changes.
Quorum and Epsilon is automatically handled as a special case for two-node clusters. In that case the system will manage this under the hood and allow configuration changes even if one of the nodes is down, but we need to tell the system that it is a two-node cluster with the commands below:
cluster ha modify -configured true
set -privilege advanced
network options switchless-cluster modify true
High Availability Verification
To verify Storage Failover High Availability, the command is 'storage failover show'.
We have a four node cluster in the example output below. The first two nodes are our first HA pair and the second two nodes are our second HA pair. 'Takeover possible true' for all of them tells us that our High Availability configuration is good.
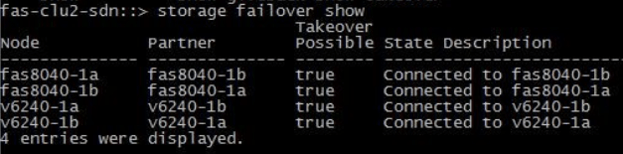
Storage Failover Show
We can also use the System Manager GUI to do this, on the High Availability page under the Cluster section. We can check the health status of our High Availability pairs and also initiate manual takeovers and givebacks.
Addtional Resources
High-Availability Pairs: https://docs.netapp.com/us-en/ontap/concepts/high-availability-pairs-concept.html
What an HA Pair is: https://library.netapp.com/ecmdocs/ECMP1552961/html/GUID-14E3CE93-AD0F-4F35-B959-282EEA15E597.html
Click Here to get my 'NetApp ONTAP 9 Storage Complete' training course.