
In this NetApp training tutorial, I will cover the NetApp Infinite Volumes. Scroll down for the video and also text tutorial.
NetApp Infinite Volumes and Storage Classes Video Tutorial

Rohit Kumar

Thanks to your courses I have cracked multiple job interviews on NetApp. I was previously working as a Technical Support Engineer for NetApp and I’m a NetApp Administrator at Capgemini now. Thank you for the awesome tutorials!
Flexible Volumes and the NetApp Storage Architecture
(Read my NetApp storage architecture post for an overview of volumes and aggregates.)
First, let’s recap on the other and more typically used type of NetApp volume - Flexible Volumes. FlexVols are always contained in one and only one aggregate, and aggregates and their disks are always owned by one and only one node (a node is a member controller in the cluster). FlexVols cannot span aggregates or nodes.
The maximum size of aggregates and FlexVols is dependent on the model of controller dependent, for example on a FAS 8080EX the maximum aggregate size is 400 terabytes and the maximum FlexVol size is 100 terabytes.
So with this example FlexVols are limited to a maximum size of 100 terabytes.
NetApp Infinite Volumes
This is where NetApp Infinite Volumes come in. Infinite Volumes allow us to have volumes with a larger size because they can span multiple aggregates and nodes.
An Infinite Volume is a single scalable volume that can store up to two billion files and up to 20 petabytes of data. Infinite Volumes can span between two and 10 nodes. They are designed for workloads which require a single huge flat namespace, where clients see a single junction path and namespace for the entire volume.
By using thin provisioning, the logical size of the Infinite Volume can be larger than the available physical size and it can be expanded non-disruptively.
A NetApp Infinite Volume is placed in its own dedicated SVM and it can only support NAS protocols. You can have FlexVol SVMs and Infinite Volume SVMs on the same cluster and they can share aggregates.
You should not create SVMs with Infinite Volumes if the cluster contains SVMs with a SAN configuration. It is recommended for that case to use separate clusters.
NetApp Infinite Volume Constituents
Infinite Volumes are made up of constituents: data constituents, a namespace constituent and namespace mirror constituents.
When a client wants to access a file in an Infinite Volume, the namespace constituent is responsible for finding which member aggregate the file is on. Each Infinite Volume has a single namespace constituent that maps directory information and file names to the file's physical data location within the Infinite Volume.
The actual data is stored in data constituents. There will typically be multiple data constituents spread over multiple nodes.
A namespace mirror constituent is a Data Protection mirror copy of the namespace constituent. It is always located within the same cluster as the original data. The namespace constituent is critical to be able to find files so the namespace mirror constituent provides a backup copy to avoids having a single point of failure.
The constituents are completely transparent to clients. The clients interact with the Infinite Volume as if it was a single normal directory on a single storage system.
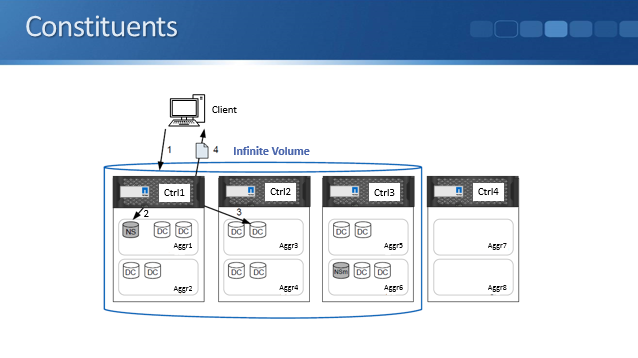
In the diagram above we have a client that sends in a read request for a file in an Infinite Volume. The read request goes to the namespace constituent which is in charge of finding on what aggregate that file is on. It will locate the particular data constituent and it will be served to the client from there.
NetApp Infinite Volume Size
You can specify the aggregates you want to use and the size of Infinite Volume when you create it. New data constituents of an Infinite Volume are balanced equally across nodes, meaning all of the data constituents in an Infinite Volume are all going to be the same size. The node with the smallest available space determines how much space is used on each node and limits the size of the Infinite Volume that you can create or expand.
For example, if you try to create a 6 petabyte, six node Infinite Volume, but one of the nodes used by the Infinite Volume only has half a petabyte of available space, then each node can hold only a half petabyte of data constituents. In this example, it will limit the total size of the Infinite Volume to 3 petabytes.
NetApp Infinite Volume Storage Classes
An optional feature of Infinite Volumes is Storage Classes. These allow you to provide multiple tiers of storage. Multiple tiers mean that we could have aggregates that are made up of SATA drives and other aggregates that are made up of SAS drives, for example, in the same Infinite Volume.
We could put our important data onto the SAS drives and our less important data onto our SATA drives, with this being transparent to our clients who see the Infinite Volume as being a single flat namespace. You can use Storage Classes to optimize your storage by grouping it into Storage Classes that correspond to specific goals.
All data is written to that single file system by the clients and then an administrator defined data policy automatically filters data for the files into different Storage Classes. Incoming files will be placed into the appropriate class according to the rules that you configure based on filename, file path, or the file owner.
You can define the following characteristics for a Storage Class: the aggregate characteristics such as the type of disks to use, and volume settings such as whether thin provisioning, compression and de-duplication will be enabled.
You can't currently configure Storage Classes with the normal command line or System Manager GUI, you have to use the OnCommand WorkFlow Automation (WFA) and OnCommand Unified Manager packages. These are optional software packages that run on servers outside the NetApp cluster.
Let's have a look at an example of using Storage Classes.
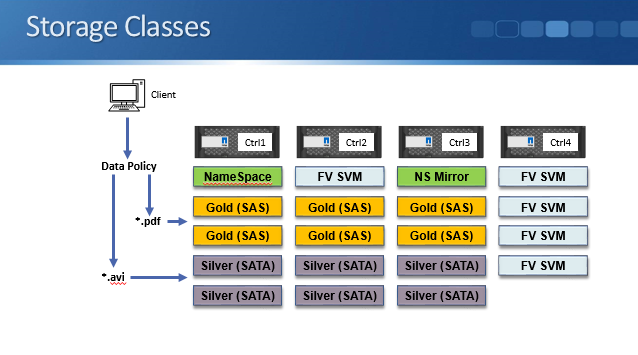
In the example above we have an Infinite Volume on a four node cluster, with the namespace constituent on an aggregate on node one, and the namespace mirror on an aggregate on controller three.
We have six aggregates made up of SAS drives which are spread over nodes one, two, and three. These are used as the ‘Gold’ Storage Class.
We also have six aggregates made up of SATA drives which are also spread over nodes one, two, and three. These make up the ‘Silver’ Storage Class.
Notice that we’re using node four for our Infinite Volume. We've got a separate SVM made up of Flexible Volumes which is using nodes two and four.
In our example PDF files are critical data which require higher performance, and AVI media files are not so important and can go on the comparatively slower performance disks.
We configure a Data Policy for our Storage Classes which sends PDF’s to the ‘Gold’ class aggregates and AVI files to the ‘Silver’ class aggregates.
Additional Resources
Understanding Infinite Volumes
Managing your Infinite Volume with storage classes and data policies
Want to practice NetApp Infinite Volumes on your laptop? Download my free step-by-step guide 'How to Build a NetApp ONTAP Lab for Free'
Click Here to get my 'NetApp ONTAP 9 Storage Complete' training course.