
In this NetApp training tutorial, you’ll learn about ALUA and SLM, which stand for Asymmetric Logical Unit Access and Selective LUN Mapping respectively. These are used to control what paths are going to be advertised to the client to access its SAN storage. Scroll down for the video and also text tutorials.
NetApp ALUA and SLM Video Tutorial

Matthew Roberts

I have been watching your videos for the past year now and last week I took and passed my NCDA exam. I just wanted to drop you a quick email to thank you. Your videos were a tremendous help!
ALUA Asymmetric Logical Unit Access
ALUA stands for Asymmetric logical unit access. It's an industry-standard protocol used to identify optimized paths between a storage system and a host initiator. It enables the initiator to query the target, that's your storage system, about path attributes and the target, to communicate events back to the initiator.

Direct paths to the node owning the LUN are marked as optimized paths. When you configure a LUN, you're going to specify the volume or qtree that is in. The volume is going to be on physical discs, which are grouped into an aggregate.
The node which owns that aggregate is going to be the preferred path. ALUA will signal back to the initiator that those paths which terminate on the node which owns the LUN, are the optimized paths. Other paths that are reported to the initiator are marked as non-optimized paths.
If all of the optimized paths fail, the DSM will automatically switch to the non-optimized paths which maintain the host access to the storage. The host is going to prefer to use the paths that terminate on the node which owns the LUN. If that node fails, it will failover to the HA partner.
Then, the host can still access the LUN because ALUA is going to tell it the paths that it can use. Because this failover is controlled by ALUA, it is required that the hosts which are using the SAN storage do have ALUA support.

Number of Paths
Now, let's talk about the number of paths that should be reported to the initiators. At a minimum, the node that owns the volume containing the LUN and its high availability partner should present paths to the initiator.
You can advertise more than that if you want to. More paths do give more redundancy, which is a good thing. At a certain point, that extra redundancy that all those extra paths give is not worth the extra complexity that they bring.
You're going to have loads of different WWPNs to include in your zones if you're using fibre channel, or if you're using iSCI, then that's going to mean lots of iSCI sessions that you have to configure and manage.

Having redundancy is a good thing. Obviously, we don't want to have a single point of failure, but we don't want to have too much redundancy because that would just add administrative overhead for no real added value.
Client operating systems may have an upper limit of paths that they can support as well. You don't want to report more than that to the host. Best practice is that there should be a maximum of eight paths for SAN clients.
Selective LUN Mapping
SLM or Selective LUN mapping reduces the number of paths from the host to the LUN. For example, you’ve got an eight-node cluster and all of the nodes are connected to two separate switches, Fabric A and Fabric B, that would end up with 16 paths being reported back to the host.
As we just said, you don't report more than eight paths. A way that we can limit the number of paths that will be reported is with SLM. SLM automatically sets ALUA reporting-nodes to the LUN owner node and it's HA partner node.
Reporting nodes means that the nodes tell the initiator, "Hey, you can reach your LUN through me." If it's a non-reporting node, then it doesn't signify back to the host that it can be used to reach the LUN. SLM is enabled by default from Clustered Data ONTAP 8.3.

Port Sets
Before SLM was available, port sets were used to reduce the number of paths and port sets are still available now in ONTAP. We don't use them now to reduce the number of paths reported back to the initiator though.
We use port sets now to dedicate certain ports to a particular set of hosts. If you want to have some ports that are dedicated to some hosts for performance reasons, then you can use port sets for that.
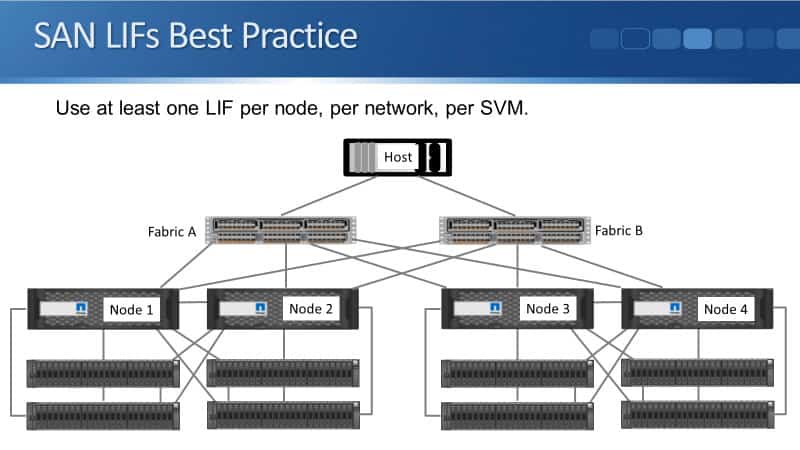
SAN LIFs Best Practice
First off, best practice is to use at least one LIF per node, per network, per SVM. In our example here, we have got a four-node cluster and all of the different nodes are going to be hosting LUNS. So in that case, you want to have one LIF per node.
You can see in the diagram that we have four nodes. Each of the nodes is attached to Fabric A and Fabric B. Therefore, it means that we would have eight LIFs, one on each of the physical ports.
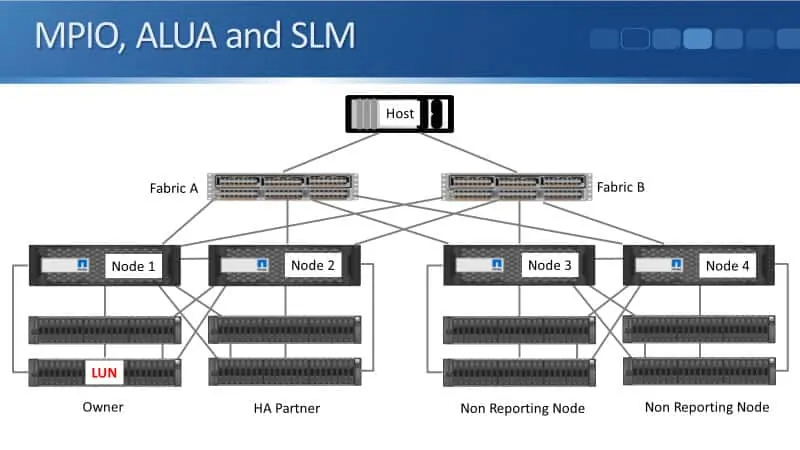
MPIO, ALUA, and SLM
We're going to be using SLM as well. In this example, our LUN is on an aggregate which is owned by node one. In this case, Node 1 is the owner, and Node 2 is going to be an HA partner.
Node 3 and Node 4 are going to be non-reporting nodes, meaning they do not tell the host that it can reach the LUN through them.
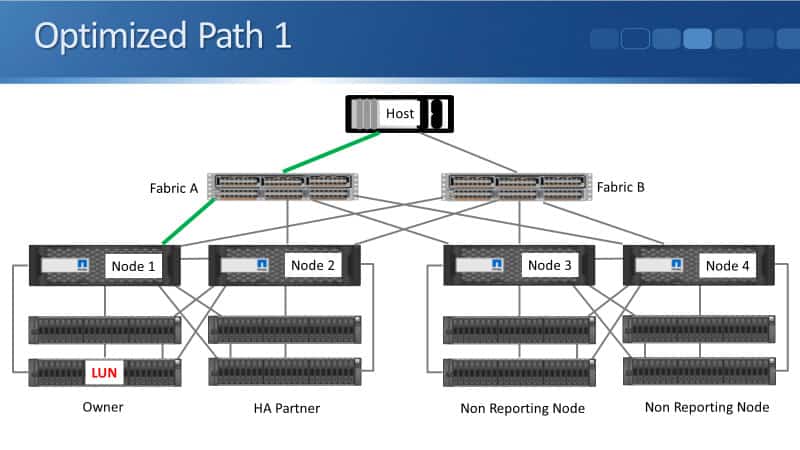
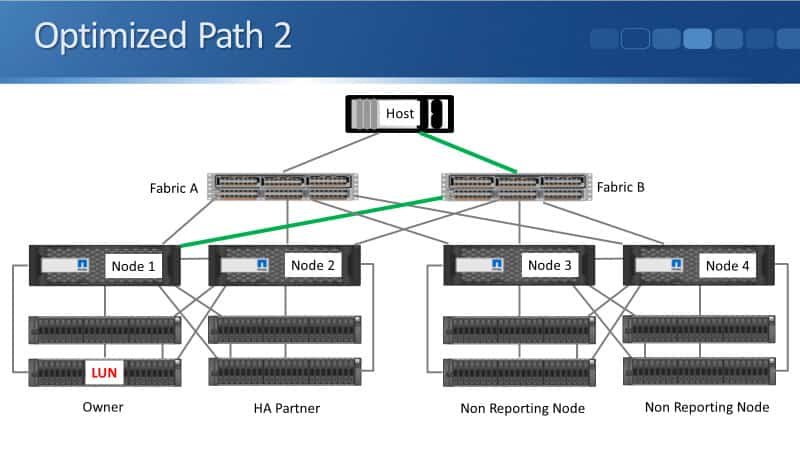
Optimized Paths
Looking at the different paths, we've got two optimized paths. Both of our optimized paths terminate on the node which owns the LUN which is Node 1.
We've got optimized path one, which is through Fabric A and terminating on Node 1. We have optimized path two, which is terminating on Node 1 and that is going through Fabric B.
These are going to be reported back to the hosts as the preferred paths they can use. The host can then either use active/standby, but it uses one path and will failover to the other if that path fails, or it can use active/active, in which case it will use both paths. If one of the paths fails, it will just use the other one.
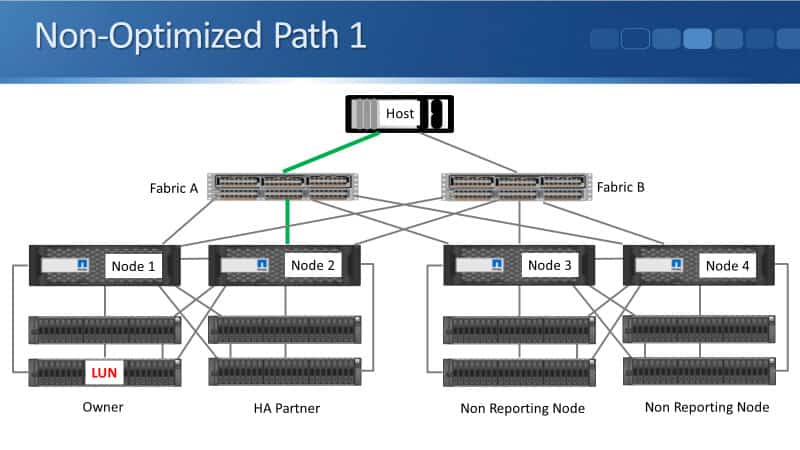
Non-Optimized Paths
We've also got a couple of non-optimized paths that is from the HA partner. We’ve got Node 2 via Fabric A and Node 2 via Fabric B as well.
If Node 1 fails, or if the Fabric A switch fails, or anything on the path to Node 1 fails, and if traffic is not available through the optimized paths, then the host can go through the non-optimized paths.
If the fails, it will failover to Node 2. That's a good thing because that is the node that will then be servicing the LUN.
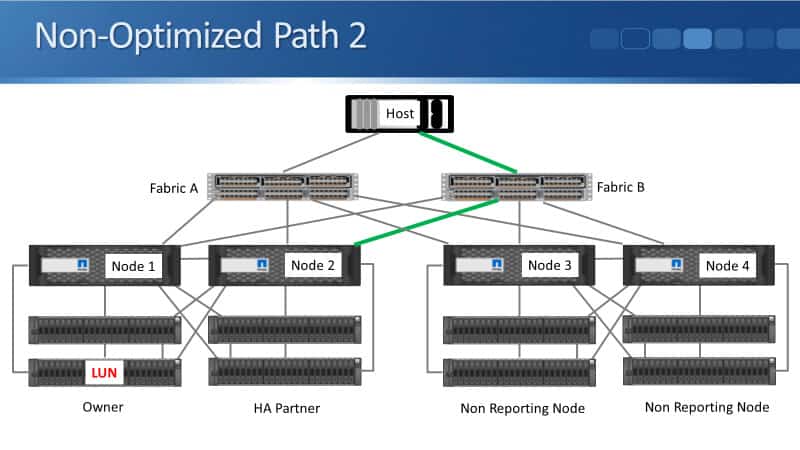
We might also have a LUN or Node 3 as well. So if you're wondering, "Well, why have we even got LIFs or Node 3 and Node 4?" If we've got a LUN on Node 3, it will have the optimized paths.
Node 4 will be the HA partner. It will have the non-optimized paths, and Node 1 and Node 2 will be non-reporting nodes in that instance.
NetApp DSM Load Balancing
So, that is how the paths are going to be signaled back to the host and how it knows which are the preferred paths to use. Is it going to use active/standby, or is it going to use active/active? What's it going to do for its load balancing?
There are some different options in the host operating system. Looking at Windows, for example, and we're using the NetApp DSM. There are six load balancing policies that are available with the NetApp DSM, whether you're using fiber channel or iSCSI.
The first one is the Least Queue Depth, and that is the default policy. With Least Queue Depth, I/Os send active/active and it's on the optimized path with the smallest current outstanding queue.
It works as active/standby if the LUN is 2TB or larger. So, if you do have a LUN which is 2TB or larger, you're probably going to want to change that.
The next available option is the Least Weighted Paths. Here, you the administrator, define the weight on the available paths. The I/O is sent active/standby on the optimized path with the lowest weight value. Therefore, you can choose which is the active path by setting the best weight on it.

The next option is Round Robin. With Round Robin, all optimized paths to the storage system are used active/active when they are available.
We also have Round Robin with subset where you, the administrator, define a subset of available paths. An I/O is Round Robin load balanced between them. This is used for LUNs which are 2TB or larger.
Round Robin with subset can use non-optimized paths here but it's not recommended to do that. It's recommended to just use the optimized paths. We want the host to be sending the traffic active/active over both of those. So, this is the recommended load balancing algorithm to use when you've got a LUN 2TB or larger.

Next is Failover Only, which is active/passive. Here, you, the administrator, define the active path. This can also use non-optimized paths. Again, that's not recommended.
The last one is Auto Assigned. Here, for each LUN, only one path is chosen at a time. It's active/standby. Those were the available load bouncing options if you've installed the NetApp DSM on Windows.

Windows Native DSM Load Balancing
If you're using the Windows Native DSM and you haven't installed the ONTAP DSM, then the load balancing options here are very similar. We got the Least Blocks here which is a different option. With the Least Blocks, I/O is sent down the path with the fewest data blocks that are currently being processed.
The other ones are equivalent to the same options that we had with the NetApp DSM, that's Failover, Round Robin, Round Robin with a subset of paths, Dynamic Least Queue Depth, and Weighted Path.

LUN Move
You saw that the system knows which node the LUN is on and it knows which is the HA partner. ALUA will report back the paths that terminate on the node which owns the LUN as the optimized paths. The paths that terminate on the HA partner are reported back as the non-optimized paths. Now, what if you move the LUN?
Using our topology as an example, what if you had a LUN on Node 1, and then you now move that LUN to Node 3? The reason that you would want to do this would be if the aggregate that the LUN is currently on is getting full and you need to move it to do some rebalancing.
Another reason would be if the performance requirement changes. You want to move it to a different aggregate, which is made up of a different disc type. It is possible to do that.
You can move a LUN to another volume within the same SVM by using the volume move command, which will move the entire volume and everything in it, or you can use the LUN Move command.
The command syntax for this is:
lun move start -vserver vs1 -source-path /vol1/lun1 -destination-path /vol2/lun1

The LUN Move command works differently than the volume move command. When you do a volume move command, all the data is moved from one volume to the other volume. When all the data has finished moving, a cutover then occurs to the new location.
With the LUN Move, the data is copied over the cluster interconnect. That's the same as with the volume move. But with the LUN Move, the new location is used almost immediately. It doesn't wait for all the data to move and then do a cutover.
So, the way that this works is that, read requests for data that is not in the new location yet. They are fetched over the cluster interconnect.
Any new writes go to the new location immediately and after a little while, the data will have all have moved over the cluster interconnect to the new location.
You can do a LUN Move, LUN Copy is available as well. A LUN Move moves it from one location to another. A Lun Copy copies it and it keeps it in both locations.

LUN Move Operation
Let's look at how the operation of this works because it doesn't actually update ALUA automatically for you. You need to be careful about how you do this when you do move a LUN.
The first thing that you should do is change the LUN mapping to add the new reporting nodes using the lun mapping add-reporting-nodes command.
With SLM, say that the LUN was on Node 1, then it is going to be reported as the optimized paths. Node 2 will be the non-optimized paths. Node 3 and Node 4 are not going to advertise at all.
If you're moving the LUN to Node 3, you need Node 3 and Node 4, which is its HA partner, to report back to the host that it can reach the LUN through them. So, you would add Node 3 and Node 4 as reporting nodes using the lun mapping add-reporting-nodes command.
The next thing that you need to do is for the host to be updated with that information. Therefore, you would perform a SCSI bus rescan on the hosts to discover the new paths. The hosts now see that the LUN is available through Nodes 1, 2, 3, and 4.
Once that is done, you can now move the LUN. That happens non-disruptively. ALUA signals a path status change to the host and the host begins moving I/O down the new direct paths.
When the LUN moves to the new location, ALUA tells the host, "Don't use Node 1 and 2 now. Use Node 3 as your optimized path and use Node 4 as your non-optimized path." Again, when you do a LUN move, it's available immediately in the new location.

Next, you can now change the LUN mapping to remove the old reporting nodes using the lun mapping remove-reporting-nodes command. Once the LUN has moved to Node 3 for example, you can see that everything is working fine on the host and everything is stable.
Lastly, you want to make sure everything is stable and finished moving before you do this. You can then remove Node 1 and 2 from reporting to the host with the lun mapping remove-reporting-nodes command. Once you've done that, do a SCSI bus rescan on the host again so that it will update and remove Node 1 and Node 2.
Additional Resources
Enabling ALUA: https://library.netapp.com/ecmdocs/ECMP1196995/html/GUID-EB9DBAE9-1E88-4421-9D02-FD820589515D.html
ALUA Configurations: https://library.netapp.com/ecmdocs/ECMP1518989/html/GUID-8E42DF1D-A835-48D5-8D95-DF09B9E71F66.html
Asymmetric Logical Unit Access (ALUA) support on NetApp Storage: https://kb.netapp.com/Advice_and_Troubleshooting/Data_Storage_Software/ONTAP_OS/Asymmetric_Logical_Unit_Access_(ALUA)_support_on_NetApp_Storage_-_Frequently_Asked_Questions
Click Here to get my 'NetApp ONTAP 9 Storage Complete' training course.
Libby Teofilo

Text by Libby Teofilo, Technical Writer at www.flackbox.com
Libby’s passion for technology drives her to constantly learn and share her insights. When she’s not immersed in the tech world, she’s either lost in a good book with a cup of coffee or out exploring on her next adventure. Always curious, always inspired.