Have you ever wondered how virtual machines get access to the physical processor cores in the server? Ever wonder why one or two VMs run slow sporadically? The topic today is Virtual Processor Scheduling. There are no good books to read on this subject, trust me I’ve looked. Maybe in 10 years as a look back at the history of virtual computing, but not today. So let’s try to shed some light on the subject for today’s article.
First things first. It is fairly simple to schedule against physical processors when the virtual machines each have a single virtual processor and there are plenty of physical cores to go around. VMware and Microsoft can send the workload to the first physical core that is available, easy. There are algorithms for figuring out the best processor core to send the workload too, but I will not go into advanced crazy algorithm mathematics today.
Now the trick/challenge/opportunity/problem (hey whatever you want to call it) that really comes into play when you have multiple virtual CPUs inside the virtual machines. The original architecture of operating systems made a perfectly good assumption that basically says “Ok I see 4 CPUs, I own all 4, period. I mean who else is close by to use them? No one. I’m lonely, but all powerful.” Isn’t that nearly always the case? Take Lord Voldemort for example, sure he had resources, but no one really wanted to be near him. <voice from overhead> Virtual processing is the subject. </voice from overhead> Oh right, sorry folks, continue on.
So when VMware re-introduced virtualization into the market, handling the single CPU wasn’t a big issue. However, bigger workloads call for more processors and therefore in order to scale, a new way to schedule CPU cycles against any given processor core was necessary. This is where Gang Scheduling comes into play. VMware, drawing upon the methods generated by the older Unix technology, uses a Gang Scheduler approach. What this means in basic terms is this: When a multi-vCPU machine requires processor time, all of the vCPUs are “ganged” together and scheduled to perform work against the physical cores. This is done in order to streamline the process, and attempt to keep the processing synchronized. In other words, like networking, we don’t like a lot of packets arriving out of turn on a load balanced network, the same stance is assumed in the VMware CPU scheduling process.
Hyper-V does things a bit differently. Virtual processors ask for time on the physical cores and Hyper-V performs ultrafast calculations to determine which core is ready and available. There is no need to group the processor calls together since the guest OSes no longer require this type of synchronicity. In order to appreciate this simpler method of scheduling we need to evaluate how things are done elsewhere.
Microsoft decided to address the challenge/opportunity/problem more directly inside the guest operating system. Basically the guest operating system should understand that it is residing inside a virtual machine and therefore the Windows kernel team redesigned the Server OS to schedule processes independently versus all at the same time. The requirement to have processor calls running in lock step with one another no longer exists starting with Server 2008. In other words, all of the gang scheduling work on VMware’s part is unnecessary to a large degree when dealing with these latest operating systems. Hyper-V understands the CPU calls are coming independently, so oversubscription of the CPU cores is not as big of a deal until all of the processors are simply topped out, which would be the case for either Hypervisor. The Hyper-V method has much less overhead than previous versions of the hypervisor as well as competition hypervisors.
If you worked with me on a VMware implementation in the past 5 years you will most likely remember that I stressed the importance of setting up the guest operating systems with the least amount of virtual processors as possible. So many administrators will listen to the software vendor or champion about the requirements for the virtual machine, and allocate multiple virtual CPUs even when the workload is a consistent 10% trickle for weeks and weeks and years. If you continue to run on VMware, you still need to heed my words here. However in a Hyper-V environment this is much less of an issue, in fact you may never see a performance hit at all when multiple CPUs are assigned in each guest.
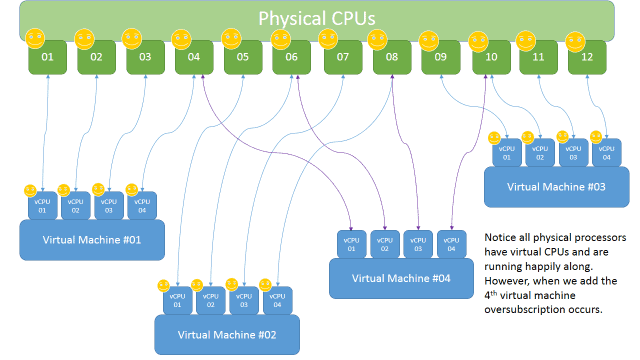
If you are a VMware administrator then you probably have some level of knowledge for troubleshooting CPU performance, and for those new to the ball game, these are the metrics to get familiar with: CPU Ready, Costop, Wait, and Wait Idle. At the very minimum get to know the CPU Ready and Costop metrics. CPU Ready is described as the amount of time in which a virtual machine waits in the queue with a ready-to-run state before it can be scheduled to a CPU (core). Costop is defined as the amount of time waiting for cycles due to CPU Ready, the value will be higher as CPU ready percentage goes up. So basically, you want low values on both of these metrics if you care anything at all about performance.
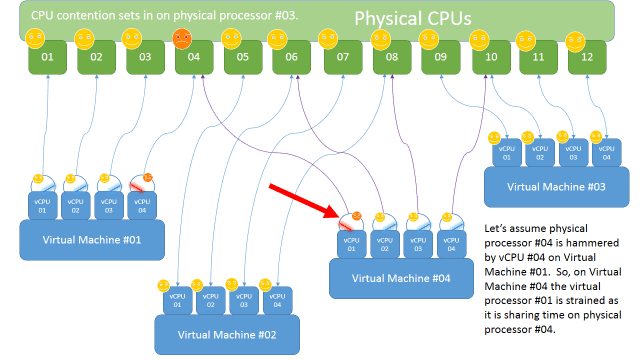
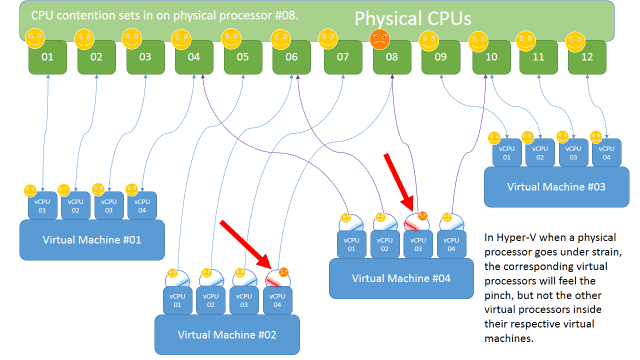
Ok, so here is where Gang Scheduling has yet to be perfected. Ask anyone who knows deep details about Gang Scheduling and they will tell you that no one has come up with a near perfect method for maintaining high performance. Consider this scenario, you have a virtual machine with four vCPUs and this machine starts hammering away on some sort of database processing. The 1st vCPU for Virtual Machine #04 will become impacted by other virtual machines on the same host, contention for the core occurs, and therefore CPU Ready then Costop numbers begin to climb.
So guess what, because vCPU #01 is having a tough time, the scheduler will automatically slow down the other vCPUs in the gang in order to maintain an appearance of synchronicity inside the guest OS. Bottom line, slower processing ensues.
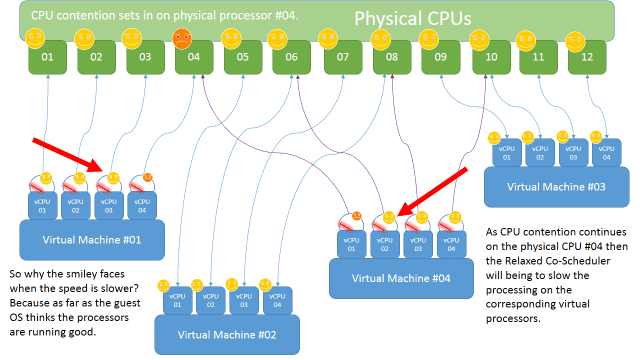
VMware has been touting for a few years the term Relaxed Co-scheduling. What does this mean in a nutshell? Straight from the VMware whitepaper: “With relaxed co-scheduling, ESXi achieves high CPU utilization by flexibly scheduling the vCPUs of multiprocessor virtual machines in a consolidated environment. To achieve the best performance for a given situation, ESXi tries to schedule as many sibling vCPUs together as possible. If there are enough available pCPUs, relaxed co-scheduling performs as well as strict co-scheduling.” Couple of things to point out here, there are some major assumptive type words in here. “If” and “tries” jump right out at me.
So you might say well what about Linux workloads, since Microsoft doesn’t own that operating system how does Hyper-V freely schedule Linux workloads across multiple processors? Lucky for Microsoft, the more recent versions of the Linux kernel allow for out-of-step processing to occur. Possibly this comes from the open source development of Xen Server, though I haven’t done extensive research into the history of Linux processor scheduling, so some of these assertions are assumptions on my part. My guess is that when the Linux developers took a look at virtualization as they were trying to tackle it, they too found that ineffective gang scheduling was not the right way to go for now, as they had already seen the roadblocks this presented via VMware and old style Unix virtualization technology. So in short, they tuned the Linux OS kernel to handle independent workloads and therefore created a hypervisor with this in mind.
Who knows, maybe at a VMWorld in the future we will hear about an all new perfect gang scheduler approach, either built in-house or most likely through an acquisition. For now, we work with what we have, and continue to re-configure and tweak those types of environments as often as it takes to keep performance in line.
At the bare minimum, I hope this article sheds some light on the differences between CPU scheduling mechanisms with ESX and Hyper-V.
Reference: The CPU Scheduler in VMware vSphere 5.1: https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/vmware-vsphere-cpu-sched-performance-white-paper.pdf
VMware is the hypervisor used in my NetApp Lab Guide, which is used extensively in my NetApp course.
You can also check my Cisco CCNA Lab Guide and Cisco CCNA course.
Article by Tommy Patterson of VirtuallyCloud9.