
In this NetApp tutorial, you’ll learn about VMware VVols, that’s Virtual Volumes, with ONTAP storage. Scroll down for the video and also text tutorials.
NetApp VVols on ONTAP Video Tutorial

Alejandro Carmona Ligeon

This is one of my favorite courses that I have done in a long time. I have always worked as a storage administrator, but I had no experience in Netapp. After finishing this course, even co-workers with more experience started asking me questions about how to set up or fix things in Netapp.
Traditional Datastores
A good way to explain and understand VVols is by comparing and contrasting them with traditional datastores. So I'll summarise some of the characteristics of traditional datastores first. Traditional datastores each use one volume if it's NFS or one LUN in one volume if you're using a SAN protocol on the storage system.

You can also have datastore clusters. A datastore cluster is a collection of similar datastores that are aggregated into a single unit of consumption from vSphere's perspective.
So a datastore cluster is where you group multiple traditional datastores together into one larger storage space, but the traditional datastores that make up that datastore cluster are still made up of one volume or one LUN.
When we're talking about traditional datastores, it’s one volume or one LUN always that makes up that datastore. ESXI clients use NFS or a SAN protocol, Fibre Channel, FCoE, or iSCSI to access the datastore.
With a traditional SAN datastore, vSphere formats a LUN with the VMFS file system and its vSphere that manages the data in the LUN. vSphere manages the file system, so ONTAP has no visibility of the individual virtual machines under files inside that LUN.
With a traditional NFS datastore, ONTAP does have visibility of the virtual machines VMDK, that's virtual disk files. Because with NFS, it's ONTAP that is managing the file system so ONTAP can see the files. But with a SAN protocol, it's vSphere that is managing the file system so ONTAP cannot see the files.

With NFS, a QoS policy within ONTAP can be applied to the entire volume or to individual VMDK files within it because ONTAP can see them. But with SAN protocols and VMFS, an ONTAP QoS policy can be applied to the entire volume or individual LUNs, but not to the files.
QoS policies cannot be applied to individual VMDK files because ONTAP has no awareness of the files inside the VMFS file system. So your QoS policies can be more granular if you're using NFS with vSphere, than if you're using a SAN protocol, and that is where the big benefit and the idea behind VVols come in.

VVol Datastores
VVols is integration between vSphere and the storage system and management framework between vSphere and the storage system. It provides granular virtual machine and virtual disk level management to the storage system with both SAN and NFS protocols.
So you get that if you're using NFS, but you don't get it normally with traditional datastores if you're using a SAN protocol. It also enables policy-based management and compliance monitoring.
With the traditional datastore, there is policy-based management using the Storage Capability Profiles and VM storage policies. But with traditional datastores, that policy-based management is at the volume level if you're using a SAN protocol. It's not at the virtual machine and virtual disk level.
With VVol datastores, you get that policy-based management at the more granular level down to the virtual disks that make up the virtual machines. It minimizes manual handoffs between VM and storage admins, so it makes administration easier. Currently, it's VVols version 2.0, which is supported by ONTAP.

In fact, VVols have famously had a very slow uptake, but a big reason for that is that VVols came out with vSphere version 6. The vSphere version before that, vSphere version 5.5, was a very long-standing, very stable, and reliable version.
So when version 6 came out, a lot of VMware customers stuck with vSphere version 5.5, which did not support VVols. Because it didn't support it, obviously, they could not deploy VVols. So that's one of the big reasons that VVols is not really in a huge amount of use today.
Having said that, vSphere version 5.5 has now gone end of life. So customers are now moving over to supported versions of vSphere. Also, if you have a look at the technical reports and other documentation that is coming out from NetApp right now, NetApp are pushing VVols quite strongly because you do get the enhanced policy-based management, you do get the extra granularity.
Another thing is that there's enhanced offload over and above what you get with VAAI for traditional datastores as well. So VVols do have good benefits. Yes, there's not a huge uptake of them as I'm recording this right now, but that might change going forward. I wouldn't be surprised if you see VVols becoming a lot more popular.
NetApp VASA Provider
vSphere and the storage system establish a two-way-out-or-band communication to manage VVols. The VASA provider translates between NetApp and vSphere APIs. So the VASA provider has to be enabled for VVols to be available with your ONTAP storage.
When you install VSC, the Virtual Storage Console, VVols provider is enabled in the latest release of that by default anyway. A VVol datastore is a logical storage container construct made up of one or multiple volumes in an SVM on the storage system, so that's a difference between VVol datastores and traditional datastores.

VVol Datastores
A traditional datastore is always a single volume or a LUN in a volume if you're using a SAN protocol. With a VVol datastore, it can be a single volume or it can be made up of multiple volumes.
Those volumes are, however, always part of the same SVM in the ONTAP storage. So it can span multiple volumes. Those volumes can also be spanned across multiple nodes in the cluster as well, but they do all have to be in the same SVM for the same VVol datastore.
When you create a VVol datastore, you specify whether to use SAN or NFSv3 as the access protocol. NFSv4.1 is not currently supported as I'm recording this. All volumes in the same VVol datastore must use the same access protocol. For example, if you're using iSCSI for the datastore, all of the volumes in that VVol datastore are going to be accessed by iSCSI.

The different ONTAP volumes that make up the VVol datastore must be in the same SVM and use the same access protocol, but they can have different characteristics. For example, one volume in the same VVol datastore could have deduplication enabled, another volume could have deduplication disabled.
VSC Storage Capability Profiles define the characteristics of each volume. So when you create your VVol datastore, you're going to specify how many volumes make up the datastore.
You're going to specify the size of each volume as well. You're going to specify the access protocol and for each of the different volumes in there, you can specify different characteristics for the different volumes by using different Storage Capability Profiles on them.

Your VVol datastores are created in the VSC, Virtual Storage Console, and when you create a VVol datastore, you specify the SVM and access protocol. You also specify how many ONTAP volumes will make up that VVol datastore and the Storage Capability Profile for each one of those volumes and volumes can be added or removed later.
If you wanted to, you could have multiple VVol datastores in the same cluster. That is supported.

VVol Datastores and Adaptive QoS
When you provision a traditional datastore with VSC, you can assign a minimum and maximum traditional QoS IOPS value. Minimum is only supported on AFF, maximum is supported on your FAS systems and AFF as well.
Adaptive QoS is not supported when you provision a traditional datastore with VSC, but both traditional min/max and adaptive QoS are supported when you provision a VVol datastore with VSC. So that is another benefit of VVol datastores over your traditional datastores.

VVols and Virtual Machines
You can place a virtual machine in a VVol datastore when the VM is first deployed. You can also migrate a virtual machine from a traditional datastore. So if you've already got a traditional datastore environment, you've got your virtual machines in there, it is easy to just create new VVol datastores, and then you can then migrate your virtual machines across.

VVol Objects
Talking about the VVol objects now, so your virtual disks, the VMDK files, that make up your virtual machines, also the virtual machine configuration files, and other VM files, are VVol objects when they are placed on a VVol datastore. So when we're talking about VVols, there were really two components there.
There's the VVol datastore, which is made up of volumes on your ONTAP storage and then there's the VVol objects that go into those datastores. The VVol objects are the files for your virtual machines. They reside directly on the storage system without using a file system.

VVols and Virtual Machines
Let's look at the different VVol objects that are going to be created and exist when you deploy a virtual machine onto a VVol datastore. Separate VVol objects are created for each separate virtual machine and they're stored as files if you're using NAS, or LUNs if you're using SAN.
So again, the way that we access our traditional datastores using NFS or a SAN protocol is exactly the same way that you access the VVol datastores, again, you're going to use NFS or a SAN protocol.
If your ESXi hosts are connecting to the VVol datastore using NFS, then the VVol objects will be stored as files. If they're connecting with a SAN protocol, then each of the objects will be stored as a separate LUN.
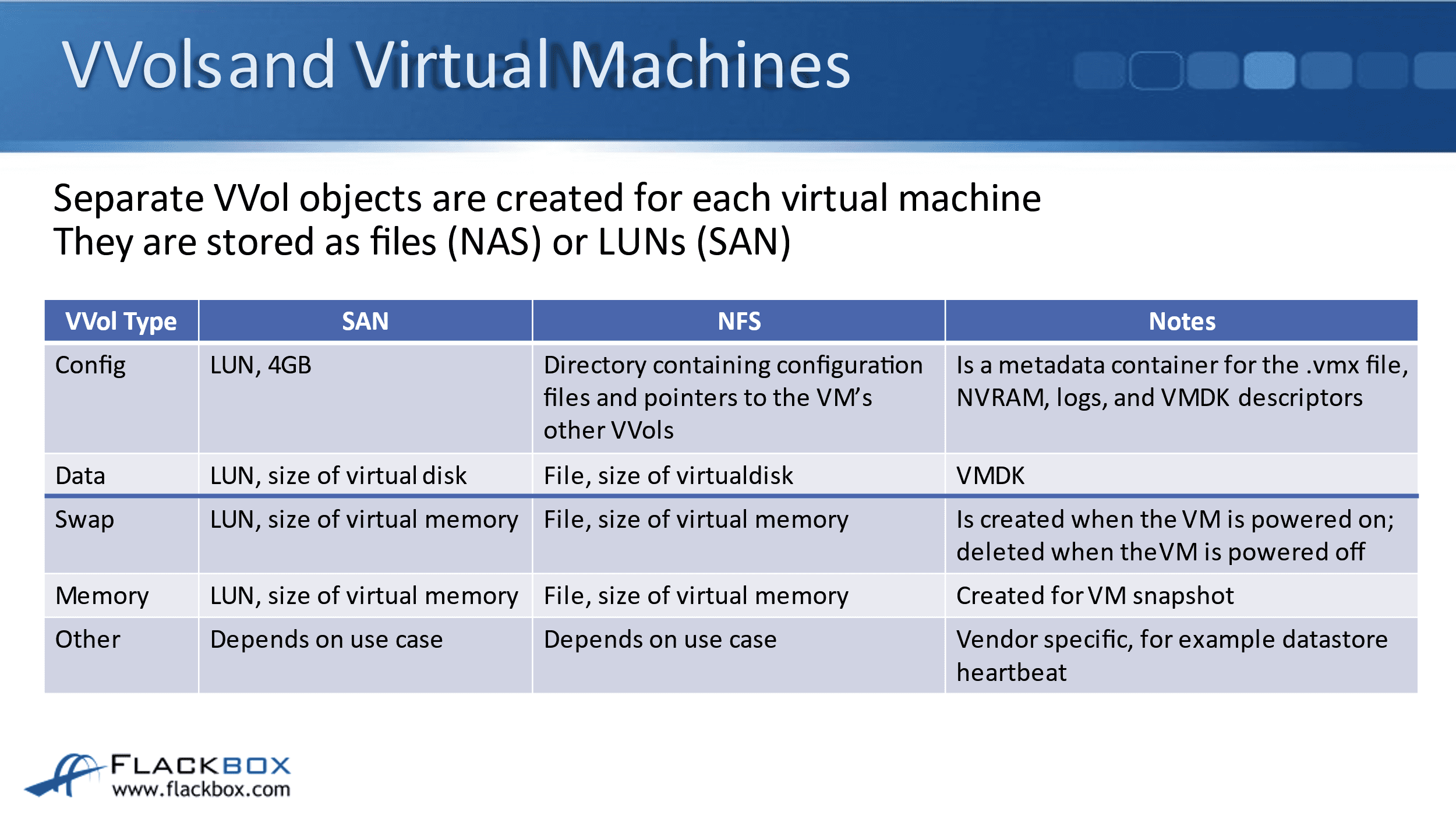
Let’s look at the different objects. Again, each different virtual machine is going to have these same VVol objects making up that virtual machine. The first VVol object is the Config VVol. If you're using a SAN protocol, that will be a LUN and it will be 4 GB in size.
It is a metadata container for the .vmx file, NVRAM, logs, and VMDK descriptors. So the Config file contains configuration information about that particular virtual machine.
If you're using NFS to access the datastore, then it's a directory containing configuration files and pointers to the VM’s other VVols. So the Config VVol, it’s the same thing wherever you're using SAN or NAS. If you're using SAN, it will be a LUN. If you're using NFS, it's going to be a directory.
The next type of VVol object is the Data VVol and that is the virtual machine’s virtual disk, the VMDK file. If you're using SAN, it will be a separate LUN, so a different LUN to the Config VVol, and it's going to be the size of the virtual disk. If you're using NFS, then it'll be a file, which is the size of the virtual disk.
If you have got, say, three VMDK files making up a particular virtual machine, then that is going to be three separate data VVols. So if, for example, it was a Windows virtual machine, and you've got a C, a D, and an E drive, those are going to be three separate VMDK files, which are going to have three separate VVol objects.
I put a line there on the slide because when you create a virtual machine and you deploy it on a VVol datastore, you're always going to have the Config and the Data VVol. The VVols below the line are optional or depending on the actual state of the virtual machine.
So, the first one is the Swap VVol and that's created when the VM is powered on, deleted when the VM is powered off. That is the virtual memory, so it's this Swap file, basically. If you're using a SAN protocol, it will be a LUN which is the size of virtual memory. If you're using NFS, it will be a file, which is the size of virtual memory.
The next VVol type is Memory, and that is created for a virtual machine snapshot. So if you don't have a snapshot, that won't exist. If you do create a snapshot, then that is going to create the Memory VVol. In SAN, again, the same as the Swap and the Data VVols.
For SAN, it'll be a LUN, the size of the virtual memory. For NFS, it’ll be a file, the size of virtual memory. You can also have other vendor-specific VVols as well, for example, for datastore heartbeats.
The different VVol objects can be assigned different VM storage policies, which are mapped to different Storage Capability Profiles. VSC is used to provision the traditional datastores on the ONTAP storage and the VSC Storage Capability Profiles is used to specify the characteristics, such as is thin provisioning enabled or not on the volumes that were backing the datastores.
The vSphere VM storage policies are then used when deploying the virtual machines to say what storage characteristics we wanted those virtual machines to get. The VM storage policies were mapped to the Storage Capability Profiles with a one-to-one relationship. So that works exactly the same in VVol datastores, as it does for traditional datastores.

The difference is that these policies are not applying at the level of the volume, they apply at the level of the VVol objects. So it's more granular when you use VVols than when you use traditional datastores. Different virtual machines and their files in the same VVol datastore can be assigned different service levels.
So for example, maybe you deploy a virtual machine that is being used as a database server, and that database server has got two different virtual disks, two different VMDK files. You could give one of the VMDK files, which is a VVol object, a high-performance QoS policy. You could give the other one, a lower performance QoS policy.
You've got a lot of granularity with your VVols datastore where different virtual disks and virtual machines can be assigned different QoS policies and also other characteristics as well, such as whether they're thin or thick provisioned within the same datastore. Not possible to do that with traditional datastores.
When you create a VVol datastore, you specify the default Storage Capability Profile. This is when you've got multiple volumes making up that VVol datastore. Because different volumes can have different Storage Capability Profiles, you're going to specify a default one. The default SCP is used when you create a virtual machine if you do not specify another SCP.
So for example, maybe we create a VVol datastore which is made up of two volumes. One is high performance, and one is low performance. You would specify the low performance as the default SCP. It's also used for Swap VVols as they do not require high performance. So set the lowest performance SCP as default.

I'll summarise that again, let's say that we've got a VVol datastore which is made up of two volumes. One is high performance, and one is low performance. When you provision that VVol datastore, you also specify which is the default SCP. You're going to make that the low performance one.
Then when you provision a virtual machine and you put it in that VVol datastore, the Swap VVol is going to get the low performance. If you don't specify, explicitly say for the virtual machine that you want its VMDK file to have higher performance, it will get the lower performance as well.

Next, let's look at what happens when you provision a virtual machine. So when you create a virtual machine its Config and Data VVols are created at that time. They are both created in volumes in the VVol datastore, which you select, which are compatible with the Storage Capability Profile, which you also select.
If the virtual machine has multiple VMDK files, a separate Data VVol will be created for each one and different Data VVols can be assigned different Storage Capability Profiles.

The QoS policy from the selected Storage Capability Profile is applied to each data VVol. No QoS policy is applied to the Config VVol, and this makes sense if you think about it.
It's the VMDK file, the virtual disk, which is really being used by the virtual machine. That's when you've got all the I/O going to. The Config VVol is just got metadata in there, so performance is not really a consideration for it.

When you power on the virtual machine, a Swap VVol is created. So when you first create the virtual machine, you've got the Config VVol created, and also a Data VVol for each VMDK. When you've powered it on, that's when the Swap VVol is created.
It's created in a volume in the VVol datastore, which is compatible with the VVol datastore's default Storage Capability Profile. Again, no QoS policy is applied because performance is not a big consideration here.

Protocol Endpoints
The next thing to talk about is Protocol Endpoints. ESXi hosts do not have direct access to VVols. A logical I/O proxy is used instead, which is called a Protocol Endpoint. ESXi hosts use the Protocol Endpoints to establish a data path on demand from virtual machines to those virtual machines’ VVols.
This provides more scalability because Protocol Endpoints can service many VVols simultaneously. It overcomes the maximum 256 LUN limitation of the vSphere. If you've got, say, a hundred virtual machines on a VVol datastore, then you're going to very quickly reach the maximum 256 LUN limitation.
If they were each accessing their LUNs individually, because each of those VVol objects when you're using SAN uses a separate LUN, so if for each virtual machine, it's maybe going to have four different VVol objects that are going to be four different LUNs. You can see that you would very quickly reach the maximum 256 LUN limitation.

It's not like with traditional datastores where it's a single LUN and all the ESXi hosts are connecting in on that single LUN. With the VVol datastores, each separate VVol object is going to have its own LUN when you're using SAN. So a lot of virtual machines would be a lot of LUNs, you would quickly reach the scalability limitation.
So to prevent you from running into that scalability limitation, the ESXi hosts are not connecting in directly to the individual LUNs. There is a Protocol Endpoint in front of there, which is used as an I/O proxy. A single Protocol Endpoint is going to be servicing multiple LUNs behind it.
The VASA provider creates Protocol Endpoints on the ONTAP system when a VVol datastore is created. For NFS, a Protocol Endpoint is created for each NFS LIF in the SVM. For SAN, a Protocol Endpoint LUN, which is 4 MB in size, is created in each volume in the VVol datastore.
When we provision the VVol datastore using a SAN protocol, the 4 MB Protocol Endpoint LUNs are going to show up on the LUNs page in System Manager. The VASA provider controls the data paths and the multipathing.

Enhanced Offload Operations
The next thing is the Enhanced Offload Operations. You've seen that the big benefit of VVols is the additional granularity that you get. Especially with your SAN protocols, it allows you to set characteristics of the storage for your virtual machines at the virtual machine, and even down to the virtual disk level.
Different virtual disks for your virtual machines, even in the same VVol datastore, can have different performance characteristics set on them. So you get that additional granularity.
The other benefit that you get with your VVol datastores is enhanced offload operations. So the VASA provider for VVols provides enhanced offload operations above what's supported by VAAI for traditional datastores. The things that it supports are native ONTAP snapshots when a snapshot is created in vSphere.
With traditional datastores, the snapshots will be offloaded from linked clones, but just standard VMware snapshots are not. But with a VVol datastore, your standard VMware snapshot, that is going to be offloaded to become a NetApp snapshot, which is more efficient.
Also, offloaded NFS storage vMotion while your virtual machines are powered on. That is supported in traditional NFS datastores while VMs are powered off, but not when they're on.
With VVol datastores, you get offloaded storage vMotion when they're powered on as well. Also, continuous access of virtual disks moving or being copied to a new volume. So if you do move a virtual disk in a VVol datastore to a new volume, your clients can still access the disk continuously while that is occurring. Also during restores, you get continuous access there as well.

VASA Dashboard and Reports
Final thing is to tell you about is OnCommand API services. The VASA dashboard and reports provide datastore and virtual machine level capacity and performance information. You must register OnCommand AP services with the VASA provider to enable them.
So to provision a VVol datastore and for your ESXi host to use it, you need to have VSC installed and you need to have the VASA provider enabled. That's just to provision and use the VVol datastores.

You do not need to have OnCommand API services installed to provision your VVol datastores. What you do need to have OnCommand API services installed for is to see the VASA dashboard and reports. So you'll be able to provision VVol datastores without it, but then you won't be able to see the performance and the capacity, information, the dashboard, and reports, etc.
So to see the dashboard and reports, you also need to install OnCommand API services. That is separate downloadable software from a NetApp website, and that gets installed separately on a Linux host, which is probably going to be inside your VMware environment running as a virtual machine.
Additional Resources
Configuring Virtual Volume Datastores: https://library.netapp.com/ecmdocs/ECMLP2836682/html/GUID-74549A9B-2CC0-48AC-885C-4CCC27B7D271.html
Working with VVOLs: https://library.netapp.com/ecmdocs/ECMP12405937/html/GUID-F984730F-9780-4FA5-AD1D-F610C2BBF9D8.html
VVOLs and VASA Provider: https://library.netapp.com/ecmdocs/ECMP12405937/html/GUID-5B810B73-0233-4F3B-80BE-47A415D2F107.html
Libby Teofilo

Text by Libby Teofilo, Technical Writer at www.flackbox.com
Libby’s passion for technology drives her to constantly learn and share her insights. When she’s not immersed in the tech world, she’s either lost in a good book with a cup of coffee or out exploring on her next adventure. Always curious, always inspired.