In this NetApp tutorial, you’ll learn about the difference between synchronous and asynchronous replication and the implications of that in ONTAP. Scroll down for the video and also text tutorials.
NetApp SnapMirror Synchronous and Asynchronous Video Tutorial

Atul Mishra

Your course on NetApp is undoubtedly the best, it is an eye opener and game changer. I passed the NCDA exam after taking it. Though I have taken NetApp instructor led training classes also, the actual learning and detailed understanding happened with the help of your course. I built the simulated lab also as advised by you which helped a great deal. Your course gave me the knowledge and confidence and made NetApp training very easy to understand. Thank you so much.
Synchronous vs. Asynchronous Replication
The diagram below shows the difference between synchronous and asynchronous replication. When the replication is synchronous, the source host sends a write request to the source storage system, which is the source of the replication. Then, the source storage system sends a replication request, and it also sends the write to the destination storage system.
The target destination storage sends an acknowledgement back to the source storage, and the source storage sends the acknowledgement back to the client. With synchronous replication, the data is written to the source and target storages before an acknowledgement is sent back to the client. Therefore, you can't have too much delay in the data being written to both locations.
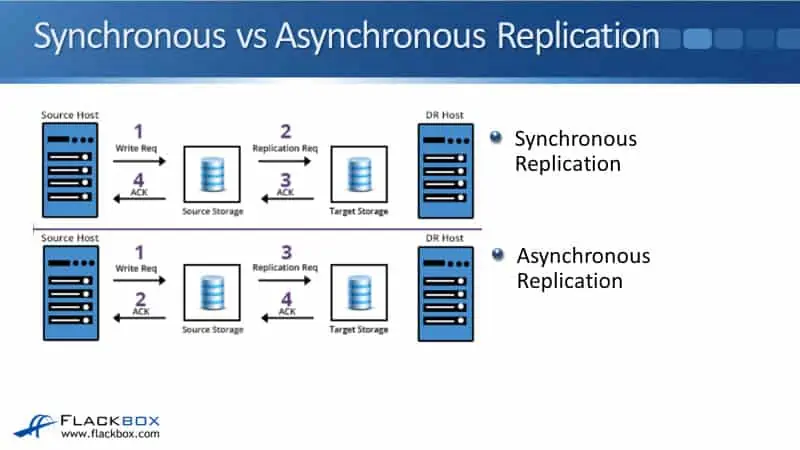
If it takes too long to write the data from the source to the target storage, then the acknowledgement to come back from there, and then the acknowledgement to go back to the client again, there will be too much delay, so it's going to time out.
The application on the source host and things are going to be broken. They're not going to work. With synchronous replication, it means that you always have two copies of the most current data in both locations, but there is going to be a time and distance limitation on whether this is going to work or not.
When you use asynchronous replication, the source host sends in a write request to its source storage system, and the source storage system immediately returns an acknowledgement to the client.
Then, based on a predetermined schedule that you decide, for example, once every 10 minutes, the source sends all of the data written to it in the previous 10 minutes to the target storage. The target storage then sends an acknowledgement back to the source storage system.
The asynchronous replication breaks it down into two separate operations. With synchronous, the write goes to both the source and the target storage before the acknowledgement returns. With asynchronous replication, the write comes into the source storage and immediately sends the acknowledgement back to the client.
Later on, on the schedule in a separate operation, all of the writes will be written to the target storage, and the target storage will return an acknowledgement.
With asynchronous replication, the source storage sends an acknowledgement immediately back to the client host system, so there's no time and distance limitation. The application will not time out in the source because the acknowledgement is sent back immediately.
Depending on the schedule, there will be a little time and distance limitation here. For example, you were trying to replicate every 30 seconds. The source storage system was in London, and the target storage system was in Sydney, and there were a lot of writes coming into the source storage system. Obviously, that wouldn't work, either.
It would be best if you had a reasonable schedule and a reasonable delay between the source and the target storage system. There should be enough delay, allowing all of the data to be written into the target and the acknowledgement to come back before sending data again.
Every time you design this kind of solution, you should have a reasonable delay between the source and the target storage system so that it will not cause a problem. If you have a reasonable delay there, it's perfectly feasible.
Even if the source storage system could be in London and the target storage system could be completely on the other side of the world in Sydney, that will work just fine. You still have your data in the two different locations, but you'll have a bit of a delay between getting to the source system and the target system. Whereas with the synchronous, there's no delay between the two.
Now, looking at how this affects things in ONTAP. Data Protection Mirror copies can be updated either synchronously or asynchronously. You choose when you set up the mirror relationship. SnapVault copies will always be asynchronous.

With Data Protection Mirror copies, we want to have two copies of the data, which we want to have as current as possible because, typically, that's being used as a disaster recovery solution. If the source side fails, we can fail over to the disaster recovery site if the source goes down for any reason. So we want to have the same copy of the data over there.
SnapVault is used for backups going back over time. If data gets corrupted or accidentally deleted on the source side, we can back up from an earlier copy on the destination side. So, with SnapVault, there would be no reason to have the replication synchronous because it's for backups going back in time. We're always going to be using asynchronous replication there.
SnapMirror Synchronous (SM-S)
SnapMirror Synchronous is available from ONTAP 9.5. In previous versions of cluster data ONTAP, we still had SnapMirror, but only asynchronous was supported. Synchronous has been available since 9.5. The way this works is that following an initial baseline transfer, writes from the clients are written to both volumes before an acknowledgement is sent back.
So if you set up a SnapMirror relationship between a source and a destination volume, and if there's already data in the source volume, you need to replicate all that data across to the destination volume first. That's your initial baseline transfer.
Once done, any writes that come into the source volume will be immediately replicated over the destination volume before an acknowledgement is sent back to the client.

With SnapMirror Synchronous, we have that time and distance limitation. If there's too much time and distance between the two sites, it will break the client applications. SnapMirror Synchronous is targeted for distances up to 150 kilometers with less than 10 milliseconds roundtrip time.
The roundtrip time is the time it takes for packets to get from the source system to the destination system and an acknowledgement to return. So, it's a two-way traffic.

ONTAP 9.5 supports fibre channel, ISCSI, and NFSv3. Support for SMB 2.0+, NFSv4.0, and 4.1 was added in ONTAP 9.6. SnapMirror Synchronous is also supported in all FAS and AFF platforms with at least 16 gigabytes of memory and on all ONTAP Select platforms.
The source and destination can be different ONTAP platforms. So, you could replicate, for example, from an AFF system to an ONTAP Select system. Each node in the source cluster must have a capacity-based SnapMirror Synchronous license in addition to the standard SnapMirror license.
So if you're using just asynchronous SnapMirror, you just need the SnapMirror license. But if you're using Synchronous, you need the SnapMirror license and the SM-S license.
Asynchronous SnapMirror relationships can be converted to Synchronous. SnapMirror Synchronous did come out comparatively recently. So if you had a system installed when ONTAP 9.1 was out and had SnapMirror Asynchronous relationship set up, you could easily convert those to SnapMirror Synchronous.
SnapMirror Synchronous does use the SnapMirror engine, which replicates at the volume level. Therefore, you can replicate from multiple source to destination volumes. AFF supports up to 40 concurrent operations per node. FAS supports up to 20, and ONTAP Select supports up to 10.

SnapMirror Synchronous Modes
SnapMirror Synchronous has got two different modes: Sync and Strict Sync. Which one to use depends on which is more important to you. Do you want to be always able to write to the volume even if the replication is possibly gone down? Or do you want the DR site always to have a synchronized copy of the data for zero RPO?

SnapMirror Synchronous - Sync
With SnapMirror Synchronous with Sync mode, if the write to the secondary storage does not complete, the application can continue writing to the primary storage. However, the replication is just not going to be happening while that is going on. That would be if what is most important to you is always being able to write to the volume.
With SnapMirror Sync, the Recovery Point Objective (RPO) will be zero under normal conditions, and the RTO, the time to actually recover, can be very low. However, if a secondary replication failure does occur, then the RPO and the RTO will become indeterminate.

For the RPO to be zero, that means that the data is being synchronous or replicated, so that is going to be the case in normal conditions. But if the replication gets broken, the RPO will not be zero anymore because you will be writing to the source volume but not to the destination volume while the replication is down.
So if the replication goes down, which is a rare event that should not happen in normal operations, then when the replication becomes available again, the volumes will be automatically re-synced without you needing to do anything.
SnapMirror Synchronous - Strict Sync
The other option we've got is Strict Sync, which is used for the second option, where you want to ensure that the DR site always has a synchronized copy of the data for zero RPO. So if writes are happening, it's guaranteed that the RPO will be zero.
With Strict Sync, if the I/O to the secondary storage fails, then the application I/O fails with synchronous replication terminated, ensuring that the primary and the secondary volumes are identical. So, you're guaranteed to have an RPO of zero if you use Strict Sync, but if your application goes down, you will not be able to write any new data until that is repaired.

How Asynchronous Replication Works
For the synchronous replication, we do an initial baseline transfer where we transfer all data from the source to the destination volume. Then after that, any writes that come into the source volume from a client will be replicated to the destination volume, and an acknowledgement will be received back from there before the acknowledgement is sent back to the client.
Asynchronous replication also does an initial baseline transfer, which works exactly the same way. A SnapMirror snapshot copy is created of all data on the source volume. Then, that snapshot copy and all the data blocks it references, and optionally any other non-SnapMirror snapshots that you've taken, just normal snapshots in that source volume, will be transferred to the destination volume.

After that, it is different than synchronous replication. After that initial baseline transfer, updates can be performed manually with asynchronous replication. So you can do a replication at any time, and they can also be done using an automated schedule. Most commonly, you will want an automated schedule that automatically replicates any changes at a specific time you choose.
With the updates, a new SnapMirror snapshot copy is taken and transferred to the destination. Then, the current SnapMirror snapshot copies are compared with the previous ones, and the updated blocks are replicated from the source to the destination.
So, we do that initial baseline transfer where everything is transferred across. After that, it's only incremental updates, only the changes that will be replicated from the source to the destination.

With our SnapMirror DP mirrors on the source side, we'll usually have one SnapMirror snapshot there. On the destination side, we're going to have two SnapMirror snapshots. We're going to have the current snapshot and the previous one.
Whenever we do a new replication, the oldest snapshot will be deleted, and a new one will be created, so we always have the two snapshot copies for SnapMirror on the destination side in normal operations.

The source volume with asynchronous replication does not need to wait for data to be replicated to the destination volume before sending an acknowledgement to the client. Instead, it's going to send it back immediately. Because of that, there's no distance or roundtrip time limitation for asynchronous DP mirrors.
Obviously, if you have a huge distance between the source and the destination volumes, you don't want to replicate too frequently. You must ensure that there's enough time between replications for all data to be replicated.
Tape Seeding
Tape seeding can help with the initial baseline transfer. Incremental updates of snapshot copies from the source to the destination are feasible over a low bandwidth network connection. However, the initial baseline replication can take a long time, especially if you've got a low bandwidth connection between the two sites.
A way you can help with that is with tape seeding. You can perform a local backup of the source volume to a tape and then physically ship it to the destination.

The mirror baseline initialization is performed by restoring from a tape at the destination cluster. So, you back up the tape in the physical source site, then physically ship that tape over to the destination site, and then do a restore from the tape at the destination side to do that initial baseline transfer.
Tape seeding is supported for both DP mirrors and SnapVault. It is optional. If the network bandwidth is not a concern or if, for example, you create the SnapMirror relationship at the same time as you create resource volume, so it's brand new, you don't have anything in it. Obviously, you wouldn't need to do tape seeding in that situation.
Additional Resources
How does Asynchronous Mirroring differ from Synchronous Mirroring?: https://library.netapp.com/ecmdocs/ECMP12404965/html/GUID-B513B031-D524-4E0D-8FB1-3984C9D9FA20.html
SnapMirror Synchronous Disaster Recovery Basics: https://docs.netapp.com/us-en/ontap/data-protection/snapmirror-synchronous-disaster-recovery-basics-concept.html
Asynchronous SnapMirror Disaster Recovery Basics: https://docs.netapp.com/us-en/ontap/data-protection/snapmirror-disaster-recovery-concept.html
Libby Teofilo

Text by Libby Teofilo, Technical Writer at www.flackbox.com
Libby’s passion for technology drives her to constantly learn and share her insights. When she’s not immersed in the tech world, she’s either lost in a good book with a cup of coffee or out exploring on her next adventure. Always curious, always inspired.