
In this NetApp tutorial, you’ll learn about the Replicated Database (RDB), quorum, and epsilon. Scroll down for the video and also text tutorial.
NetApp Replicated Database, Quorum, and Epsilon Video Tutorial

Abhishek Khulbe

I just cleared my NCDA in 1st attempt and all thanks to Neil’s amazing content on Flackbox, his training material, and guidance. His hands-on approach to coaching, detailed explanation with diagrams has won my respect. I am hopeful he will deliver even more in NetApp storage world.
Vol0
Vol0 contains system data for managing the node and cluster and it's used for the RDB databases and log files. RDB stands for the Replicated Database and it includes system information. It's called the Replicated Database because it's replicated between all of the nodes in the cluster.

Vol0 is included on every node in the cluster and it does not contain any client data. It's just used for system information. Because it is on every node in the cluster, if we somehow lose Vol0, that can be recreated from the identical Vol0s which are on the different nodes.
Vol0 contains the system information, but it's not to be confused with the SVM root volumes. For the SVM root volumes, we have an SVM root volume created whenever we create an SVM, and that functions as the root of the namespace of that SVM.
The Replicated Database RDB
Vol0 is where the replicated database lives. That is where we have our system information. There are four RDB units namely, Volume Location Database (VLDB), the Management Gateway, the Virtual Interface Manager (VifMgr), and the Blocks Configuration and Operations Manager (BCOM).

Volume Location Database (VLDB)
The VLDB contains an index of which node owns each aggregate and which aggregate contains each volume. As the system administrator, it's possible for you to move volumes between different aggregates.
The system needs to keep track of where each volume is located, and it's the VLDB that does that. It's cached in the memory to speed up the lookup process during client data access. When the system boots up, it will be read from Vol0 on disk into system memory.

Management Gateway
Next up, we have the Management Gateway. This provides the Command Line Interface. The Management Gateway enables the management of the cluster from any node. You've seen that when you SSH into the command line, usually, you'll go to the cluster management address.
You can manage any node in the cluster but you could actually SSH to the node management address of any of the individual nodes. From there, you would still be able to manage the entire cluster.

Virtual Interface Manager (VifMgr)
Next, we have the Virtual Interface Manager. That, as you would guess from its name, stores and monitors the logical interfaces and the LIF failover configuration for your IP addresses.

Blocks Configuration and Operations Manager (BCOM)
Finally, we have BCOM which is the Blocks Configuration and Operations Manager. This stores and monitors SAN information, including your LUN map definitions and your Initiator Groups (iGroups).

RDB Replication
The Replicated Database does have to be replicated between all the nodes in the cluster. Each node needs to know that system information. Each RDB unit, each of the four units, has its own separate replication ring. For each unit, one node. One controller in your cluster is the master, and the other nodes are secondaries for each unit.

Master nodes can be different for each unit. Typically, when it's first set up, your first node in your cluster is going to be the master for each unit. But if you have any nodes being rebooted, then that can cause things to move around. Rights for an RDB unit go to its master and are then propagated to the secondaries through the cluster interconnect.
Whenever you make a change to the system information, that is going to be written to the master of the relevant RDB unit, and it's then going to be replicated out to all the other nodes over to cluster interconnect.
Quorum
A healthy RDB unit is in quorum. That means that a majority of nodes are communicating with each other. For example, if you had an eight node cluster and five of your nodes are able to communicate with each other, well, that's a majority of the nodes so the cluster would be in quorum.
If a master has communication issues over the cluster interconnect with the other nodes, then a new master will be elected by the members of the unit automatically. All this stuff with the RDB and with quorum and epsilon coming up, it's all managed by this system itself under the hood. You don't need to configure anything here. One new node has a tie-breaking ability, epsilon, for all RDB units.

Quorum exists to prevent an inconsistent system configuration in case of a split brain cluster. For example, let's say that we've got an eight node cluster and five of the nodes can communicate with each other over the cluster interconnect, and the other three can communicate with each other. But between those two sets of nodes, the five and the three, the two sets do not have communication with each other.
In that case, system changes can only be written to the set of five nodes. We did have five nodes up, then the cluster is quorum, we can still make changes. The reason that we have this is if you did have a split brain, half the nodes in your cluster were split off from the other half of your nodes, you wouldn't want to be able to make system changes to both of those sets. If you did that, then they would have inconsistent system information.

If some of the rights are going to one set and the other rights are going to the other set, then if the connectivity was restored, you could have conflicting information. How would they know which was the correct set of information and how would they recover from that?
So, we need to make sure that that never happens. Having the concept of quorum, that makes sure that you can never be writing two different sets of configuration to do two different sets of nodes at the same time.
Epsilon
What if you don't have a majority of nodes but you've got exactly half of the nodes that have got communication with each other? For example, in our eight node cluster, rather than having a set of five and a set of three, we've got two sets of four nodes that can communicate with each other instead?

When exactly half of the nodes in the cluster are isolated from the other half, no majority exists. You'd have a four and a four with our eight node example. In this case, one node has a weighted vote as a tiebreaker. That is the epsilon node.
One epsilon node is epsilon for the entire cluster. It's not like the RDB units where you've got a separate primary for each unit. With epsilon, it is one node per the entire cluster.

With the eight node cluster example where we had two sets of four nodes and four nodes, system changes can only be written to the set of nodes which includes the epsilon node. If the epsilon node is up, then the cluster is still in quorum and we can still write changes.
Out of Quorum
When an RDB unit goes out of quorum, reads from the RDB unit can still occur, but changes to the RDB unit cannot. For example, if the VLDB goes out of quorum, there would be less than half of the nodes that have good connectivity to each other, the cluster is now out of quorum.

For the VLDB, in that case, no volumes could be created, deleted, or moved. You can't write any new system information, but you can still do reads. So access to the volumes from clients is not affected. Now, it's important for me to say here that a cluster going out of quorum, it's not like this is a daily event. This is a very tedious and very rare event to happen.
For a cluster to go out of quorum, more than half of your nodes need to be unable to communicate with each other over the cluster interconnect. If your cluster ever does go out of quorum, obviously it's very important that you recover and you fix that as soon as possible.
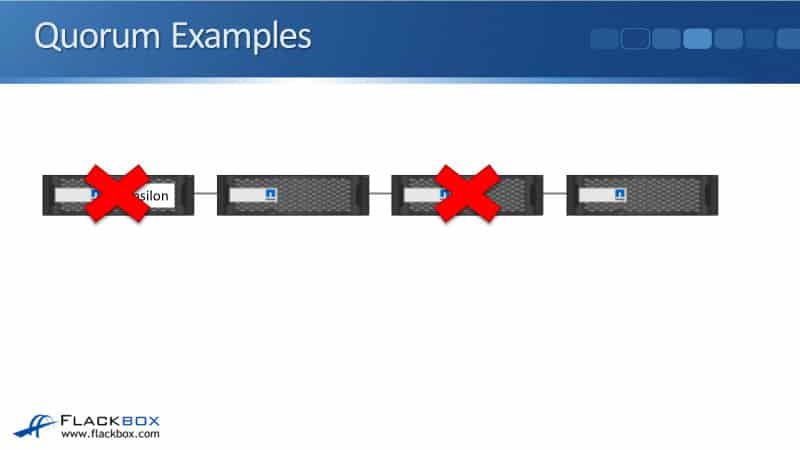
Quorum Examples
Let's look at some examples of when our cluster would be in or not in quorum. Let’s say we've got a four node cluster. Over here on the left, our first node is the Epsilon node. I just put a line between them here just to show that they've got connectivity to each other. The connectivity would actually be going through the cluster interconnect.
Our fourth node here fails connectivity with the other three nodes. In that case, we've still got connectivity between three nodes out of four, there's a majority there. Therefore, the cluster is still in quorum.
Then, the third node’s connectivity fails. Now, in this case, we've got a four node cluster and we've got that equal halfway split now. Two of the nodes do not have connectivity, the other two do. Well, one of those nodes is epsilon. Because we've got that 50/50 split, the epsilon is available. That acts as a tie breaker and the cluster is still in quorum. We can still write system information changes.
The second node then loses connectivity. In this case, we've only got one node available out of four, that's less than half. So even though it's the epsilon node, the cluster is now out of quorum.

Next, let's say that it is the epsilon node that loses connectivity with the other three nodes. Well, in that case, even though it's the epsilon node, we've still got three nodes that have connectivity out of four. That's a majority, so we are in quorum.
Then, if the third node loses connectivity, we've got that equal 50/50 split now. But because we don't have the epsilon node, the cluster is now out of quorum.
Two Node Clusters
Two-node clusters are a special case because if one of the nodes goes down, we've now got that equal 50/50 split. Having epsilon there wouldn't work because if node one is epsilon, and if node two goes down, then that's fine, we can still write changes. But if node one goes down, we can't because we've got a 50/50 split and we don't have epsilon.
For two-node clusters, that normal way of doing things is really just not going to work. We've got a special case here because no majority exists if either node is unavailable. And it wouldn't work having one of the controllers having epsilon. So in that case, the RDB is going to manage things under the hood. This is all going to work internally in the system.

Again, you don't need to worry about this. It's going to just work anyway, but you do need to tell the system that it is a two-node cluster. The way you do that is with the command:
cluster ha modify -configured true
There's a high availability command to let the cluster know that if one of the nodes does fail, and you have that high availability event, don't take the cluster out of quorum because it's a two-node cluster. We've still got one controller available.
Additional Resources
Learn About the Replication Service: https://docs.netapp.com/us-en/cloud-manager-replication/concept-replication.html
What is Cluster HA and How is Epsilon Utilized to Maintain RDB Quorum?: https://kb.netapp.com/Advice_and_Troubleshooting/Data_Storage_Software/ONTAP_OS/What_is_Cluster_HA_and_how_is_Epsilon_utilized_to_maintain_RDB_Quorum
About Quorum and Epsilon: https://docs.netapp.com/us-en/ontap/system-admin/quorum-epsilon-concept.html
Libby Teofilo

Text by Libby Teofilo, Technical Writer at www.flackbox.com
Libby’s passion for technology drives her to constantly learn and share her insights. When she’s not immersed in the tech world, she’s either lost in a good book with a cup of coffee or out exploring on her next adventure. Always curious, always inspired.