
In this NetApp tutorial, I’ll give you an overview of the different ONTAP data protection technologies and how they all fit together. Scroll down for the video and also text tutorial.
NetApp Data Protection Overview Video Tutorial

Rohit Kumar

Thanks to your courses I have cracked multiple job interviews on NetApp. I was previously working as a Technical Support Engineer for NetApp and I’m a NetApp Administrator at Capgemini now. Thank you for the awesome tutorials!
ONTAP Data Protection
Data protection ensures that your data remains available in the case of failure of part or all of the storage system, hardware, or software. For the failure of a part, an example would be the failure of one controller in the cluster. All of the system failing, for example, would be the entire cluster failing.
Other things that can happen would be the failure of the entire physical site. You could have a failure of a single hardware component in the cluster, or perhaps the ONTAP operating system failed somehow, or even the entire site went down because of a flood, fire, or a complete power outage.
ONTAP does have the protection solutions for all those incidents occurring. Other things that could happen are data corruption or accidental deletion. If either one of those things happens, you want to be able to get the data back in the good state it was in before that happened.

ONTAP Hardware Redundancy
Starting off with hardware redundancy, an ONTAP storage system can, and usually is implemented with no hardware single points of failure. Redundant components are used to ensure that the system can withstand a failure of any single instance of a hardware component type.
It protects against a single point of failure. For example, if a single disk, a single disk shelf, or a single controller failed, then the cluster can carry on operating.

Now, if you have a failure of two components of the same type, then it's not guaranteed to protect against that. Sometimes students bring this up with me and see that as being a problem. The thing is you could design the system to have no dual points of failure. But then I could say, well what if two things fail? Oh, we'll need three. What if three things fail? We'll need four.
Obviously, the chance of two hardware components of the same type coincidentally failing at the same time is very unlikely. It's very rare for any hardware component to fail. For two of them to fail at the same time is highly unlikely.
If that highly unlikely event did somehow occur, there are still other features that can be used such as MetroCluster and SnapMirror, in conjunction with the hardware redundancy that do protect against that.
Redundant Hardware Components
Let's look at the redundant hardware components. We've got the controllers, the disk shelves, the disk shelf cables, and the disks. The two main components in the cluster are the controllers and the disk shelf. We also have the connections between them and the disks in the shelves. We have got redundant hardware for all of those different components.

Disk Redundancy
I'll start off the bottom level with the disks. The way that redundancy is provided for disks failing is with RAID. RAID 4 protects against failure of a single disk in a RAID group. RAID-DP for your dual protection, protects against failure of two disks in a RAID group. Finally, RAID-TEC, which is a Triple Erasure Coding, protects against failure of three disks in a RAID group.

Disk Shelf Redundancy
With RAID, it will protect for up to three disk failures in a single RAID group, but obviously, our disk shelves have got more than three disks in them. So, what if the entire shelf fails? That is where SyncMirror comes in. SyncMirror protects against failure of a disk shelf by mirroring data across two separate shelves.
In our example, we've got Disk Shelf 1 which has got Aggregate 1 in it. It is made up of a couple of different RAID groups. If that disk shelf fails, to protect against a failure what we do is mirror the same data across two different shelves.
You can see in Aggregate 1, we have RAID Group 0 and RAID Group 1, and again, RAID Group 0 and RAID Group 1 with the same data on the different disk shelves.
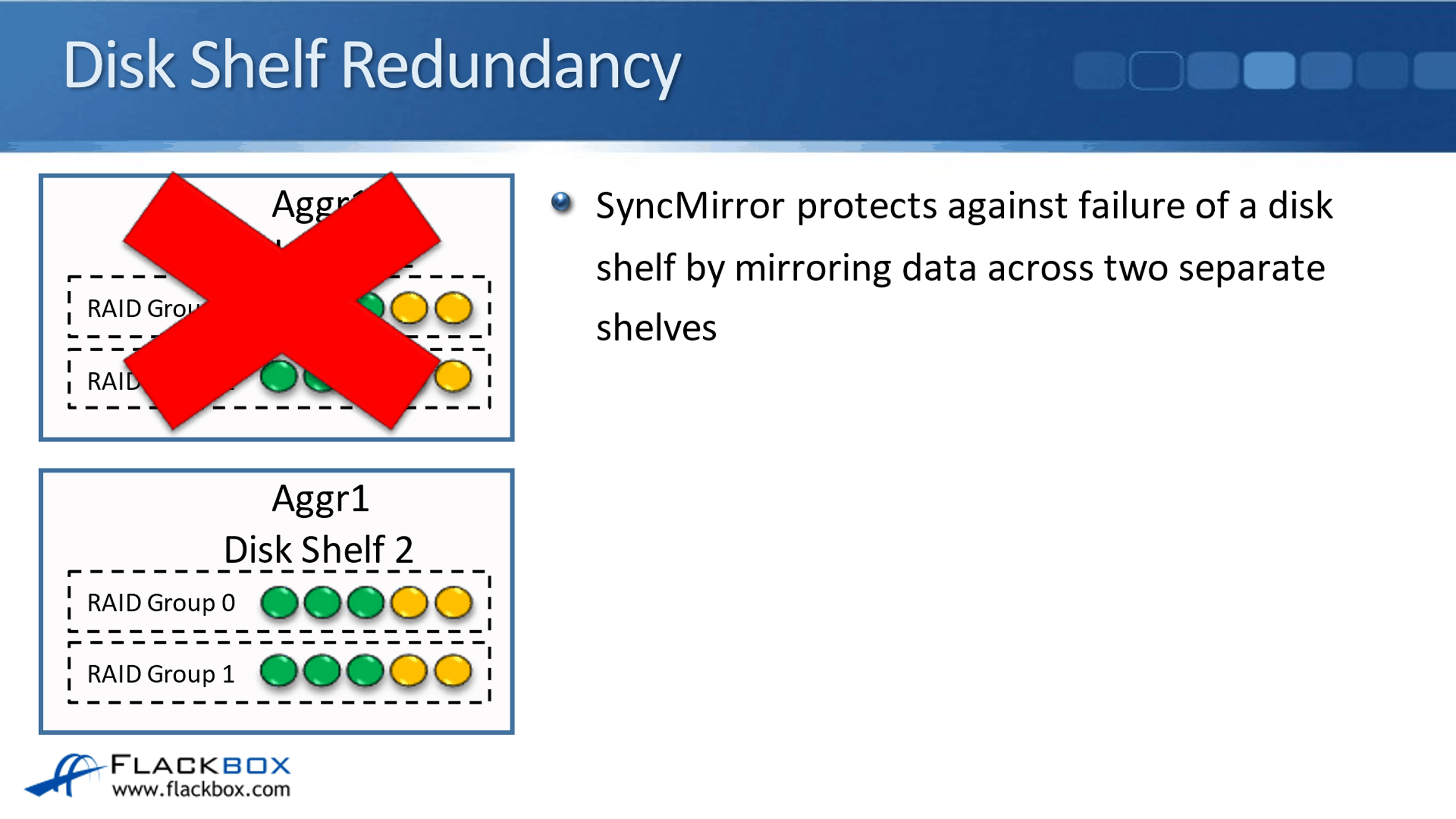
With SyncMirror, if one of the disk shelves fails and the data is still on the other, we've got the other copy of it so the data is still accessible. Because it is stored in two sets of disks, twice as many disks are required with SyncMirror though.
Because of this, SyncMirror is optional. RAID is not optional. Whenever you configure your Aggregates, you have to use either RAID 4, RAID-DP, or RAID-Tec. Since SyncMirror doubles the number of disks which is going to add to the cost of the system, SyncMirror is optional if you want to have that configured or not.

Disk Shelf Cable Redundancy
The next thing that we have is redundancy for our disk shelf cables and that comes from Multi-Path High Availability (MPHA). MPHA uses redundant cable paths to each stack of disk shelves.
In our example below, we've got the controller at the top and we've got a stack of disk shelves under there. We don't have a separate cable going to each one of the disk shelves though.
We can have up to 10 disk shelves in a stack but we don't want to have to use 10 different ports in the back of our controller and have 10 different cables going to the disk shelves. That wouldn't be manageable.

What we do is, from the controller we have a single cable that goes to the top shelf in the stack, and then they're daisy-chained down from there. But as you can see, that gives us a problem in that if any one of those cables fails, then we're going to lose connectivity to the disk shelves.
To stop losing connectivity, what we do is we have multi-path HA where from a second port on the controller we connect that to the bottom shelf in a stack. If any of the cables goes down, we've still got connectivity to all of the different disk shelves. MPHA, just like RAID, should also always be used.
Controller Redundancy
Next, we have redundancy for is our controllers. Our ONTAP controllers are arranged in High Availability (HA) pairs. The controllers in an HA pair are connected to each other's disk shelves so that in case one of the controllers goes down, the other one can still serve its data. If a controller fails, the other controller and that HA pair will take ownership of failed controllers Aggregates.

If both controllers in an HA pair fail, the Aggregates owned by those controllers will not be available. With the hardware redundancy, it protects against a single point of failure. If two controllers in an HA pair fail, that it's not a single failure, that is two different failures. Again, super highly unlikely that that would ever happen.

Say you've got a four-node cluster and you've got Controllers 1 and 2 that are an HA pair, and Controllers 3 and 4 are another HA pair. If Controller 1 and Controller 3 go down, the other HA partner is still up, so you'll still have access to all of the data.
If Controller 1 and Controller 2 go down, then you will lose access to the data that was hosted on Controllers 1 or 2. You would still have access to the data that was hosted on Controllers 3 and 4.
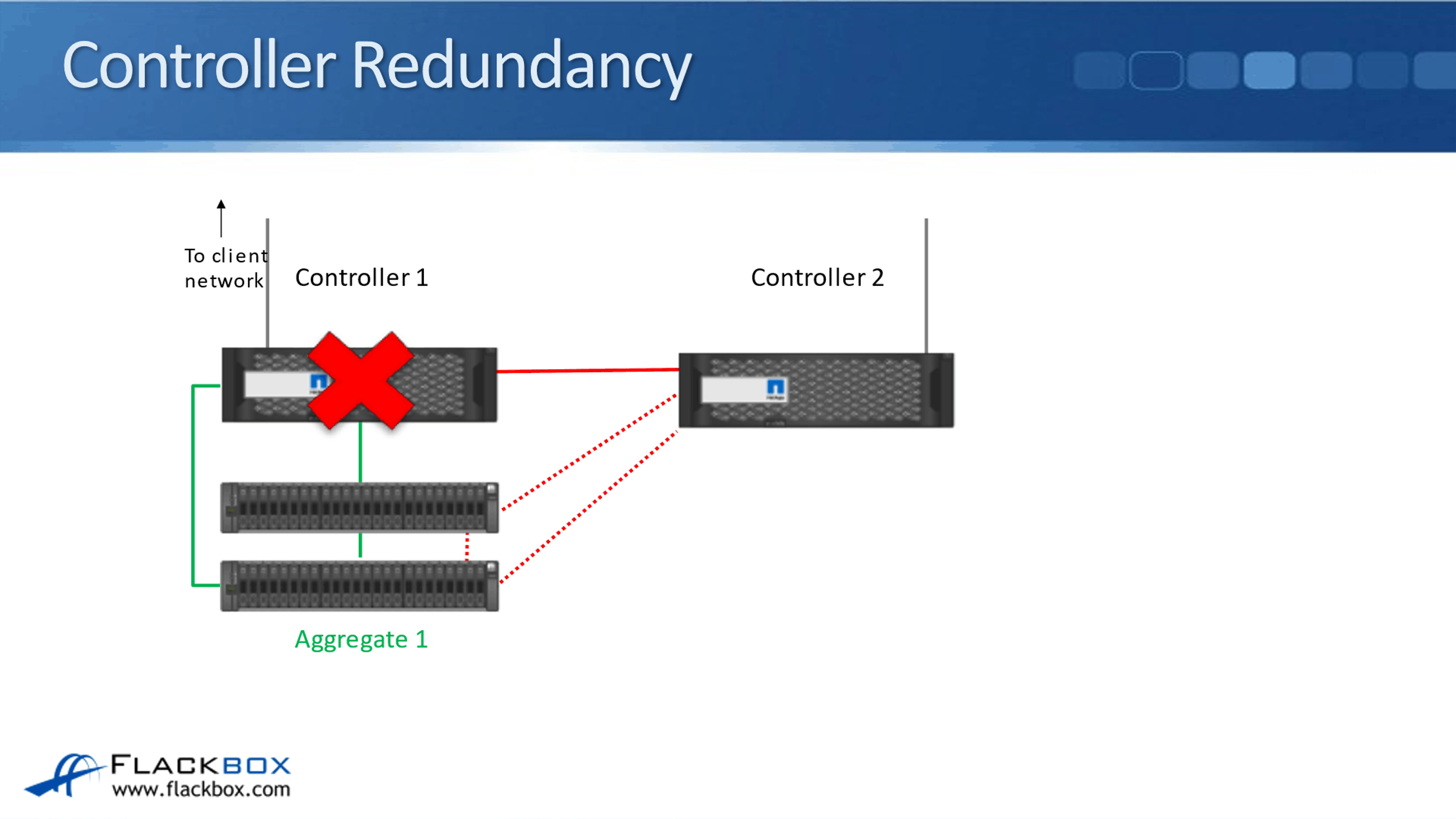
Looking at how HA works, you can see here that we have got a controller that's connected to the client network, and it's connected to its disk shelves. Now, it is possible that you can have a single controller configuration if you want.
However, that is not commonly used because it does have a single point of failure. To make sure that that controller is not a single point of failure, we put a second controller in, and then that Controller 2 is connected to Controller 1's disk shelves.
We also have a high availability connection between the two controllers. That's used for the NVRAM mirroring, and also keep-alives between the controllers. So, they can detect if the other controller goes down. If Controller 1 does go down because Controller 2 is connected to its disk shelves, Controller 2 will take ownership of those disks and it's still able to serve the data.
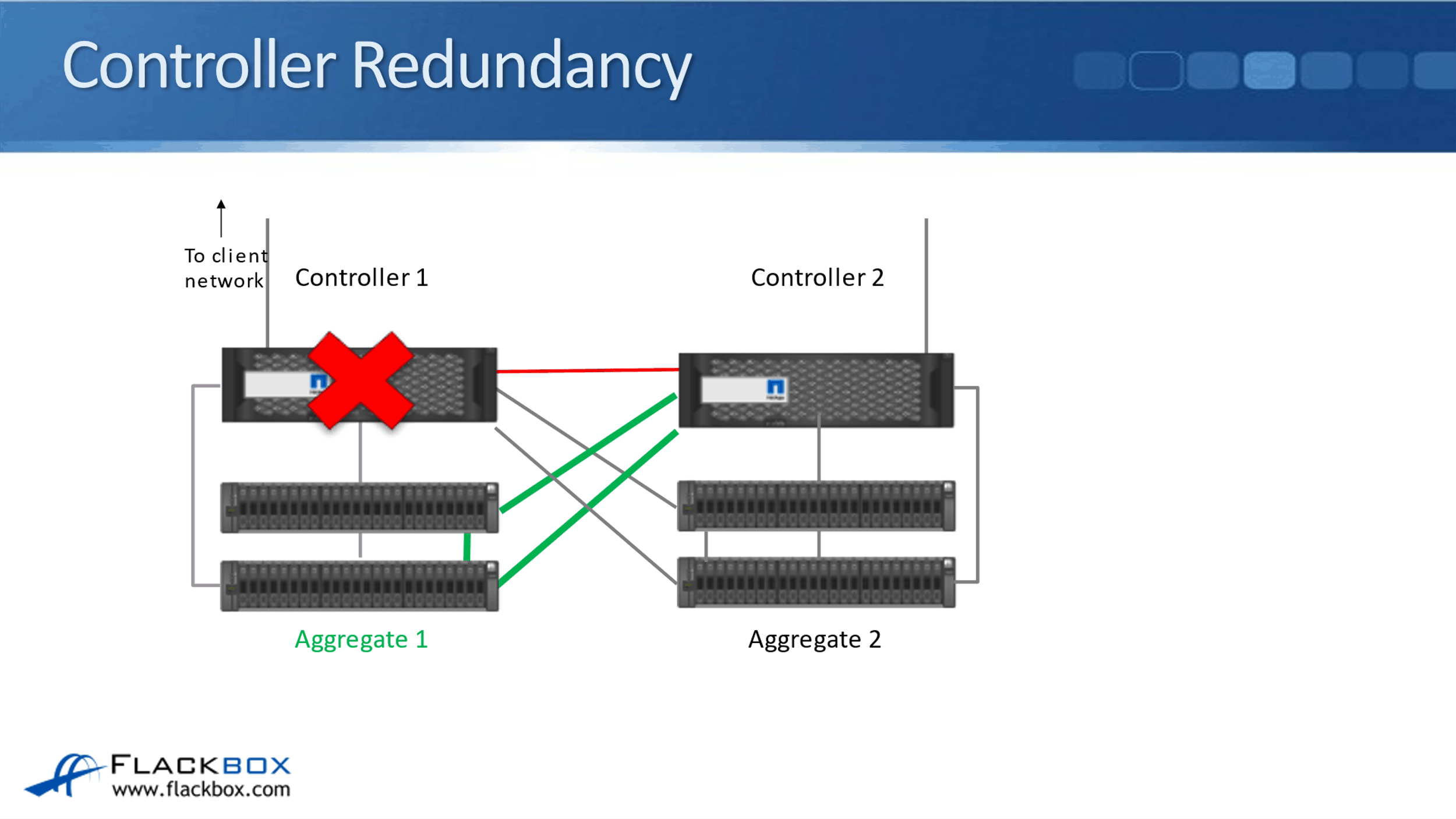
In the diagram here, this would be an active standby configuration because Controller 1 is normally active. In that case, Controller 2 is just a standby. We don't want that to be the case. We want to make maximum use of our resources.
Because of that, we're going to have Active-Active. Controller 2 is also going to own its Aggregates as well. For redundancy on Controller 2's Aggregates, Controller 1 will be connected to Controller 2's disk shelves.
Physical Site Redundancy
Hardware component redundancy does ensure an ONTAP system remains available, should any single instance of a hardware component type fail.
But what if multiple instances of a hardware component type fail? Highly unlikely. Or a bit more likely, the entire physical site goes offline because you have a flood, fire, or a complete electrical failure.

Well, we've got solutions to help with that too. Disaster Recovery (DR) options replicate data between two physical sites. So if one site goes down, you've still got the data in another site and you can access it on that other site as well. Our options for this are MetroCluster and SnapMirror.

High Availability
The problem with high availability is that if the entire site goes down. You can see here we've got our two controllers in an HA pair. If Controller 1 goes down, Controller 2 is still connected to its disk shelves so it can serve the data in Aggregate 1.
But what if Controller 1 and Controller 2 were in two different buildings, and building one goes down?
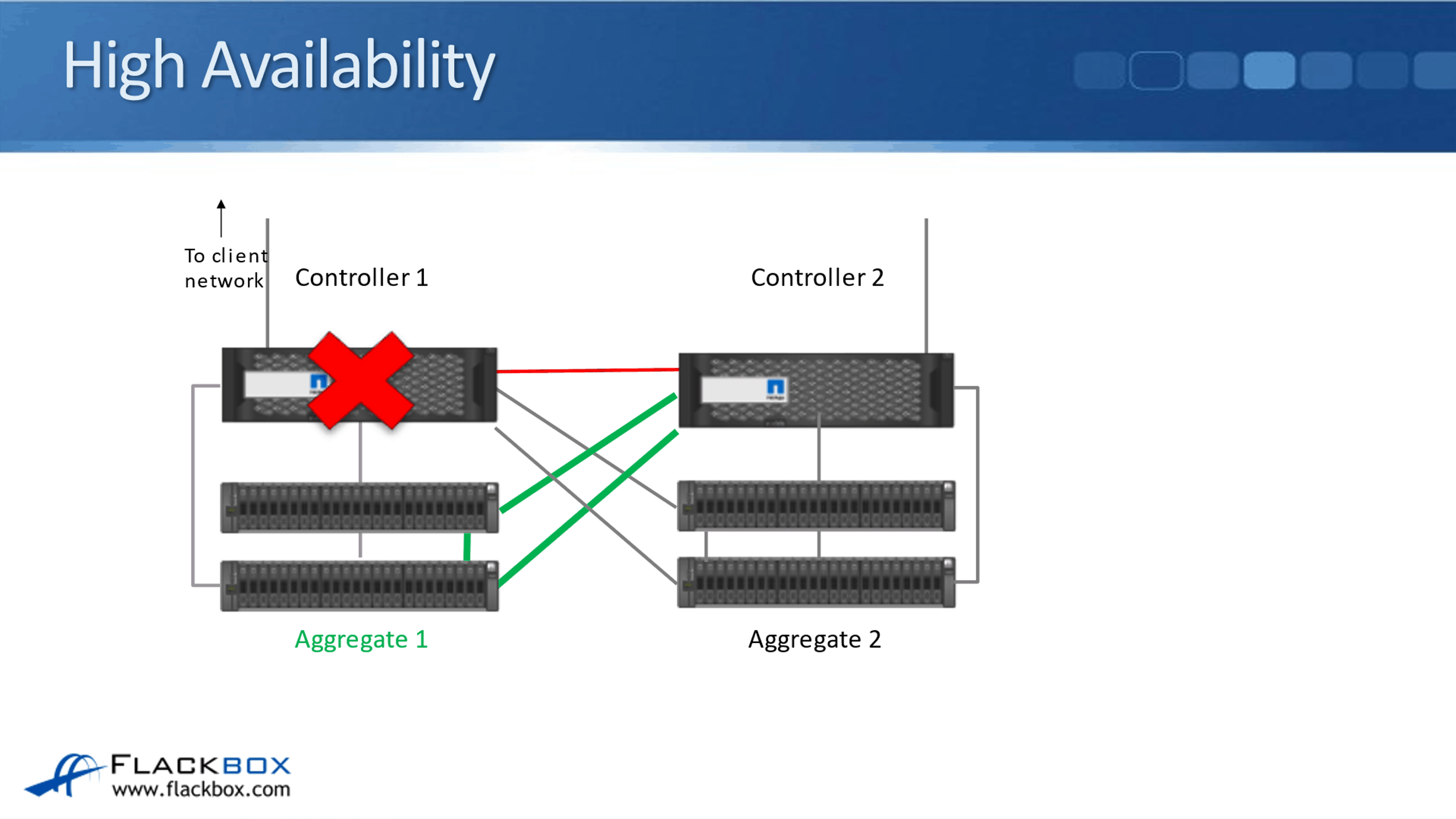
Now, the entire building is going down. In that case we've lost not just the controller, but the disk shelves as well. It doesn't help that Controller 2 is connected to Controller 1's disk shelves because the disk shelves are down. We've lost access to Aggregate 1.
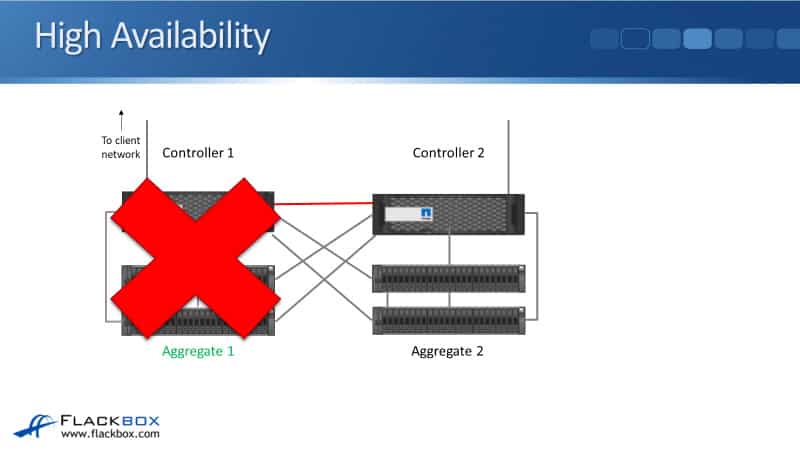
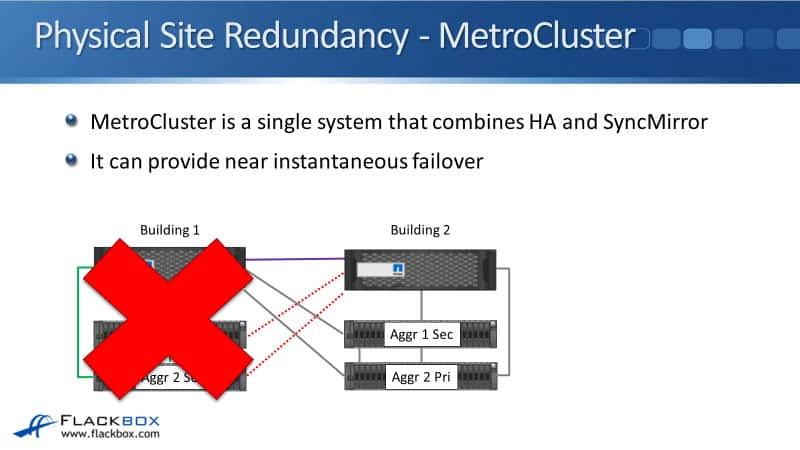
This is where MetroCluster comes in. MetroCluster is a single system that combines HA and SyncMirror as well. It combines the HA for the controller redundancy with SyncMirror for the disk shelf redundancy.
As you can see here, now we have got our controllers in two separate buildings. In Aggregate 1, the data is located in Building 1 and in Building 2 as well.
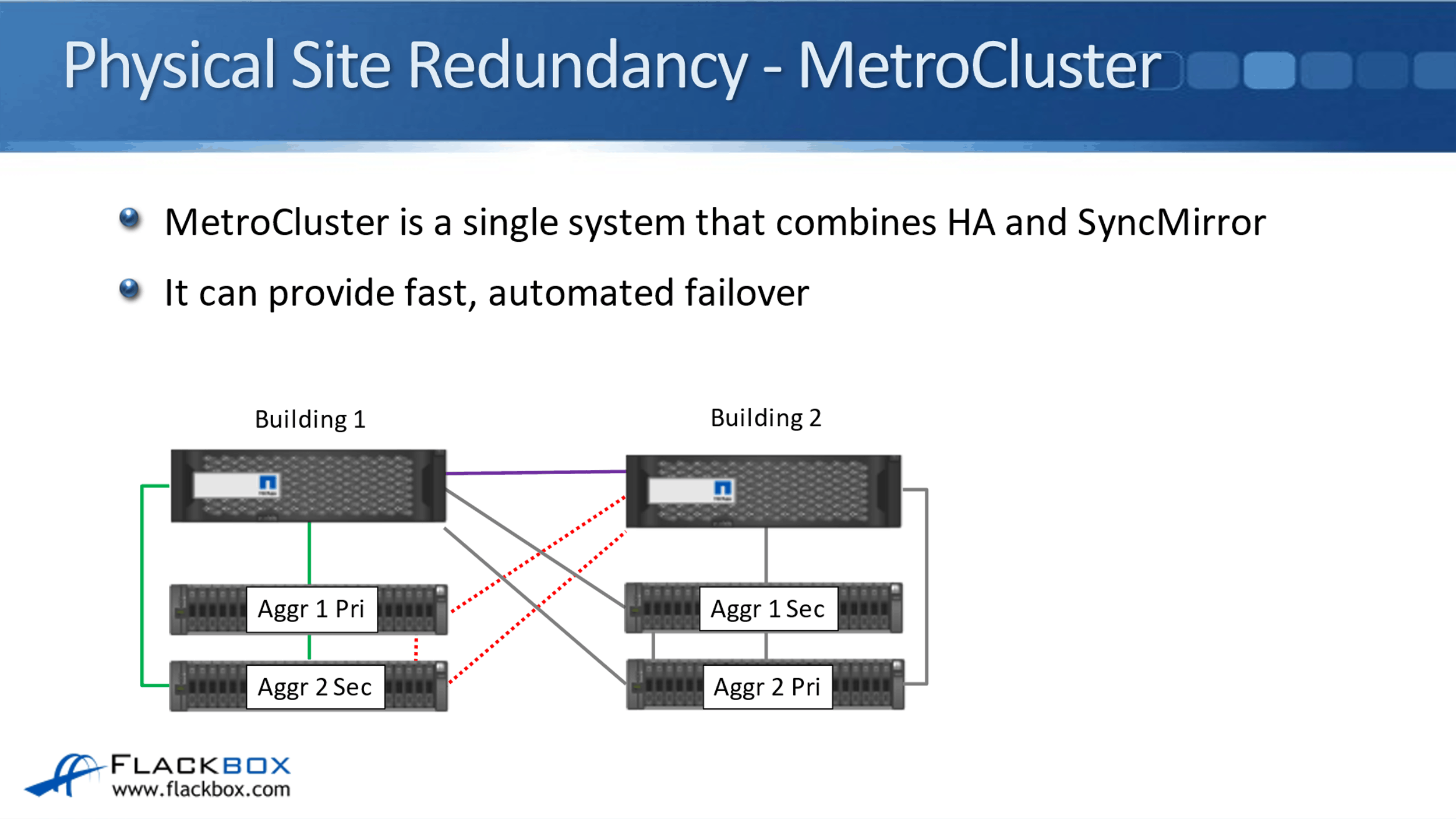
We use SyncMirror to have it duplicated across the two different disk shelves. We do that for Aggregate 2 as well. If we do have that complete building failure again, Building 1 goes down, Building 2 still has access to both Aggregate 1 and Aggregate 2. We've still got access to all of the data.
Physical Site Redundancy – SnapMirror
SnapMirror replicates volumes from one NetApp system to another. So just like with MetroCluster where it has your data in the two different sites and we keep them in sync with each other, SnapMirror does a very similar thing. It can also replicate volumes within the same cluster, but by far the most common use case is going to be between different clusters.
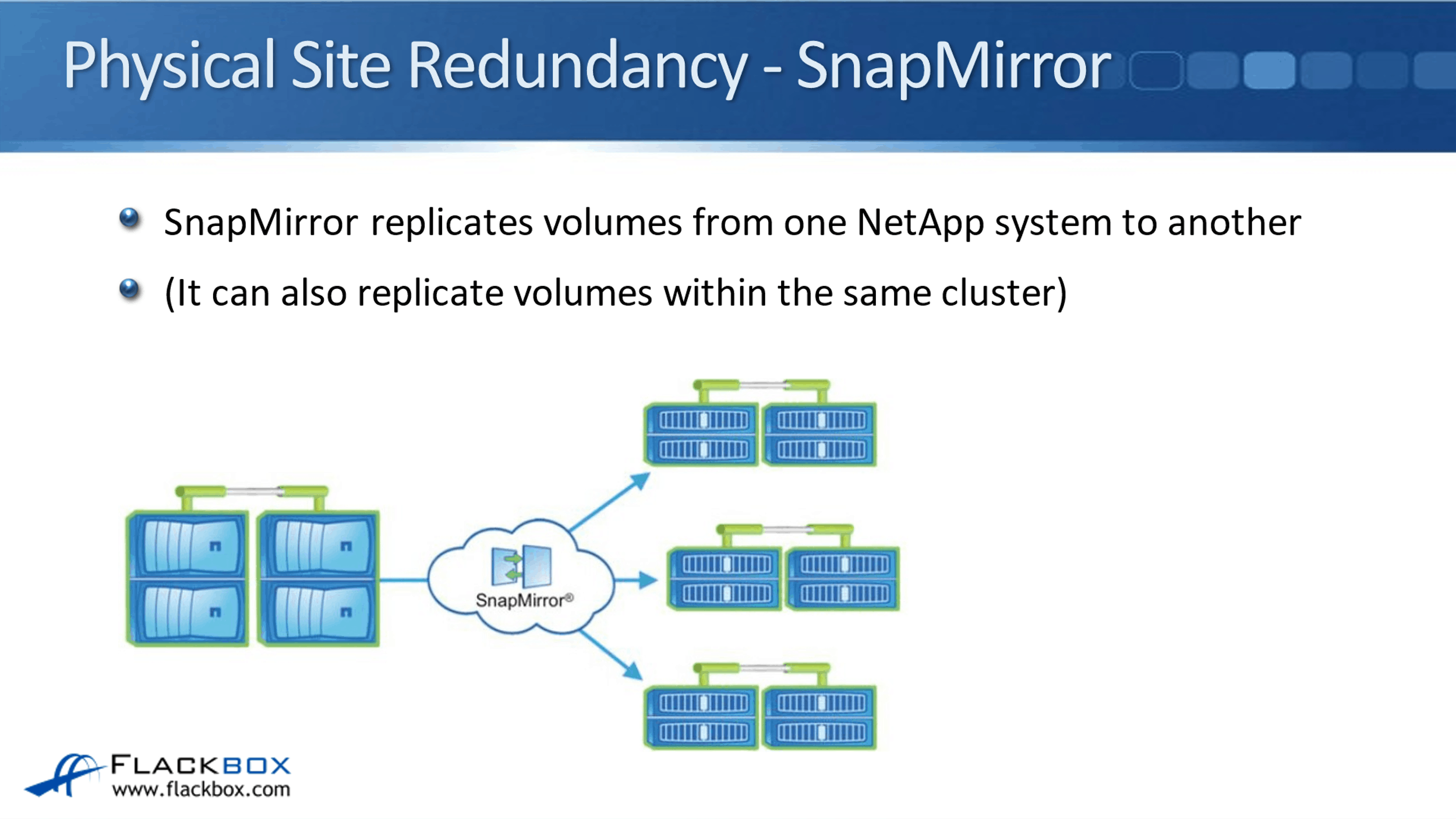
In the diagram above, we've got the source cluster here and we're replicating its data to another physical site. We can actually replicate it to more than one physical site if we wanted to, just like in our example, it's going through three different physical sites.
Now you're maybe wondering, that sounds like MetroCluster and SnapMirror do a very similar thing. Why have we got with two different technologies? Let's explain that next.
RPO and RTO
First off, I need to give you some terminology, which is RPO and RTO. Recovery Point Objective (RPO), is how much data can be lost following failover to the DR site in the worst-case scenario. This is directly related to how often you are replicating.
For example, we've got our main site and our disaster recovery site and we replicate the data once every 10 minutes. Well, if we had done the last replication 10 minutes ago, and then 9 minutes and 59 seconds later, so just before we were about to do the next application, we lose the main site.
In that case, we've lost 9 minutes and 59 seconds of data. The last 10 minutes that was written has not been replicated to the DR site, and if the main site is gone forever, then we've lost that 10 minutes’ worth of data.
The RPO is worst-case scenario, how much data could be lost if you have to failover to the DR site. It basically equals how often you are replicating the data.

The other important piece of terminology as far as DR is concerned is the Recovery Time Objective (RTO). That is how long it takes to failover to the DR site. It's not as easy to calculate this one by just looking at a metric like how often you're replicating the RTO.
It really depends on your company's processes of what they do in the case of having to failover to the DR site. The way that you find out what your RTO is by testing. Do a test failover and see how long it takes you to get up and running and everybody able to access the data in the DR site. Obviously, you want to get this as low as possible.
MetroCluster vs SnapMirror
MetroCluster is capable of zero RPO. MetroCluster uses synchronous replication, so there is no gap at all between the data being written to the two sites.
It has an RTO of 120 seconds or less. With MetroCluster, the failover can be automated, it gives you a very quick failover. You can either automate it or actually do it yourself manually. It's basically just a single command to do that. That’s zero RPO and very fast RTO with MetroCluster.
With SnapMirror, you can either do it synchronous or asynchronous. You can have the two sites where they're constantly synchronized with each other. There's no delay there, or you can do it as asynchronous, where you're going to replicate based on a schedule.

With SnapMirror Synchronous, obviously, the RPO is going to be zero because they're kept completely in sync all the time. With SnapMirror Synchronous, the RTO can be low, but failover does require manual intervention, unlike with MetroCluster.
The last one we've got is SnapMirror Asynchronous. The most frequently that you can replicate with SnapMirror Asynchronous is once every minute. Typically, you'll be doing it less frequently than that. The failover requires manual intervention because it's using the same SnapMirror engine as SnapMirror Synchronous.
Looking at that, you're maybe thinking, "Well, I'm not going to use SnapMirror then. I'm always going to use MetroCluster. But MetroCluster has some limitations on the supported hardware and software configuration. In your environment, it might just not be doable to use MetroCluster.
There's also a limit on the physical distance between sites as well. Since it is using synchronous replication, if it takes too long to get the data from one site to the other and back again, and then back to the clients, the client applications can time out. That's going to break those client applications.

If you're using synchronous replication, which MetroCluster does, then you need to have the sites close together in the same metro area. That's why it's called MetroCluster. There are also these limitations on the support hardware and software configuration as well, so it's not always possible to use MetroCluster.
The next one we had was SnapMirror Synchronous. That does have a distance limitation as well, again because it's using synchronous replication. It has less configuration limitations than MetroCluster does. It does require manual failover. SnapMirror Asynchronous also has no distance limitation and it supports many configurations.

With SnapMirror Asynchronous, your two sites can be on the other side of the world from each other. You would just need to have a reasonable delay between the synchronizations for that to be working okay.
Moreover, there are very, very few limitations on the support configurations. You can actually use that with other NetApp systems, other than ONTAP. SnapMirror also has use cases other than DR, such as migrating data between two different sites.
With MetroCluster, it's always used as a high availability solution. With SnapMirror, it is most commonly used as a disaster recovery solution, but you can use it for some other use cases as well.
Now, the two features there, MetroCluster and SnapMirror, they're not mutually exclusive, so you could use just MetroCluster, or you could use just SnapMirror, or you could use both features at the same time.
The Need for Backup
DR options keep data in sync across multiple physical sites. Because of this, if data becomes corrupted in your main site, that corruption is going to be replicated to the backup site as well. Therefore, DR is not a one-stop solution.

It provides your disaster recovery and backup and all the data protection you need. Because your data could be corrupted, and that's going to be replicated to all the different sites, you need to have a backup as well.
Backup
Backup is also required to enable the recovery of corrupted or accidentally deleted data. The options for backup are Snapshots, SnapVault, and there are also 3rd party solutions available.

SnapMirror vs SnapVault
SnapMirror and SnapVault both use the SnapMirror engine to replicate data between NetApp storage systems. The way that they work is very similar. The configuration is very similar as well. SnapMirror is primarily a disaster recovery solution, which syncs data to a secondary DR site. The secondary site can be made live, meaning read-write, if the primary system becomes unavailable.
Typically, when you've got your DR site, watch it always, the primary site is going to be a read-write copy, and a DR site will be a read-only copy. You can't have two different sites both being writeable, because if that was the case, if users were able to write the same volumes in two different sites, then it would not be possible to keep the volumes consistent.

Therefore, one site, your main site, is always the writeable copy. The DR site is read-only. With the DR solution, if the main site becomes unavailable, then you can failover to the DR site and it becomes the read-write copy at that point.
SnapMirror is primarily used as a DR solution. Snap Vault is a backup solution. It maintains multiple copies of the data going back over time on the secondary site, which can be stored in the case of data corruption or accidental deletion. SnapMirror just keeps basically one copy of the data in both sites, and keeps them in sync with each other, depending on your replication schedule.

SnapVault has more than one copy on the secondary site. It's going to have multiple copies going back over time, which can be used as a backup. We have Unified Replication available as well. It combines SnapMirror and SnapVault functionality.
If you had a volume and you wanted to have DR for that volume and also a backup for that volume as well if we didn't have Unified Replication, then you could replicate it to one volume in the secondary site for DR. You can also replace it to another separate volume for backup.
That would not be very efficient because it would take up twice the amount of space and it would also take up more network bandwidth as well. With Unified Replication, you just have the one destination volume, which serves as both the DR and as the backup.
Disaster Recovery and Backup
Let's talk about some implications here with our disaster recovery and backup. Storage systems should always be backed up. In the real world, users always lose, accidentally delete data. It happens all the time. So, you need to have backups so you can get it back again. Data can be corrupted as well.
If you've got a NetApp system, enterprise-level storage, absolutely for sure you are going to have a backup solution there.
Disaster recovery is optional. Way back in the day, it used to be expensive to implement a disaster recovery solution. Because if you were with enterprise, you needed to have a disaster recovery building that you would be able to failover to. Having that building was an expensive proposition.

The cost and the ease of implementing disaster recovery have come way down since the prevalence of the cloud. So with ONTAP, ONTAP can run in hardware solutions in your data center. There are also cloud solutions there as well.
With NetApp’s data fabric, you can replicate between different operating systems. Because it was with the data fabric, it makes the disaster recovery much more viable, much more cost-effective. It's much more likely that your organization is going to be having a disaster recovery solution in the present climate.
SnapCenter
The last thing to tell you about here is SnapCenter, which is another software solution from NetApp. It provides central management of your disaster recovery, backup, restore, and clone operations. If you've got 10 different ONTAP clusters, rather than having to manage them individually, with SnapCenter you can manage them all from the single pane of glass.
ONTAP can also integrate with third-party software, such as CommVault, Veeam, Cleondris, and Catalogic.

Additional Resources
Data Protection Overview: https://docs.netapp.com/us-en/ontap/concept_dp_overview.html
Introduction to Data Protection: https://library.netapp.com/ecmdocs/ECMP1196991/html/GUID-0F851C3C-78F2-4C29-AB7D-30D4849850CB.html
Methods of Protecting Data: https://library.netapp.com/ecmdocs/ECMP1196991/html/GUID-CF44CDC1-72FF-470E-8DC4-F17BCED0419E.html
Libby Teofilo

Text by Libby Teofilo, Technical Writer at www.flackbox.com
Libby’s passion for technology drives her to constantly learn and share her insights. When she’s not immersed in the tech world, she’s either lost in a good book with a cup of coffee or out exploring on her next adventure. Always curious, always inspired.