
In this NetApp training tutorial, I will cover the 7-Mode Hardware Architecture. ONTAP 7-Mode was deprecated after version 8.2 of the operating system, but it’s much easier to understand the clustered hardware architecture of Clustered ONTAP and ONTAP 9 if you see the 7-Mode architecture first.
I’ll cover the clustered architecture in the next post, which will also explain how it overcomes the scalability limitations of 7-Mode. Scroll down for the video and also text tutorial.
NetApp 7-Mode Hardware Architecture – Video Tutorial

Rohit Kumar

Thanks to your courses I have cracked multiple job interviews on NetApp. I was previously working as a Technical Support Engineer for NetApp and I’m a NetApp Administrator at Capgemini now. Thank you for the awesome tutorials!
NetApp 7-Mode Hardware Architecture
The controller is the brains of the storage system. It's where the CPU, memory and operating system live. It also contains the ports which provide connectivity to clients and disk shelves.
Our disk shelves are connected in stacks. You can have up to 10 shelves in a stack with the current models of SAS shelves. You can have multiple stacks connected to the same controller depending on how many available SAS ports it has.
The controller is not connected to every individual shelf as that would require an unreasonable number of ports on the controller. A SAS port in the controller is cabled to the top shelf in the stack, and we then daisy chain cables from disk shelf to disk shelf all the way down to the bottom shelf in the stack.

Controller to Disk Shelf SAS connections
We would have a problem if one of the ports or cables in the daisy chain failed. We'd lose connectivity from our controller to all the disks that were below that point in the chain.
For that reason, we put in a second SAS connection that goes from another port in the controller down to the bottom shelf in the stack. This gives us Multi-Path High Availability (MPHA). Now if we lose one of the cables or ports in the chain, we can still reach all of our disk shelves.
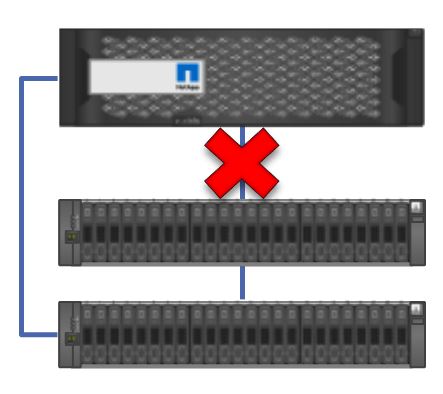
Multi-Path High Availability (MPHA)
MPHA is plug-and-play active-active and the controller will automatically use the shortest of the two paths whenever it needs to reach a disk.
In the example above we just have a single controller, but in the vast majority of deployments your storage is going to be mission critical and you're not going to want to have any single points of failure. For that reason, we're going to put in a second controller. As well as providing redundancy, we want to use the CPU, memory and throughput of both controllers in an active-active configuration, so the second controller is also going to have its own disk shelves.

Redundant Controllers
For High Availability we need to be able to serve data to clients if either controller fails, so we connect the controllers to each other’s shelves. The cabling is done in the same way again.
From another SAS port on the back of Controller 1, we connect to the top shelf in Controller 2’s stack, and we then daisy chain the connections down to the bottom shelf in the stack. For Multi-Path High Availability we connect another port on Controller 1 to the bottom shelf in Controller 2’s stack.
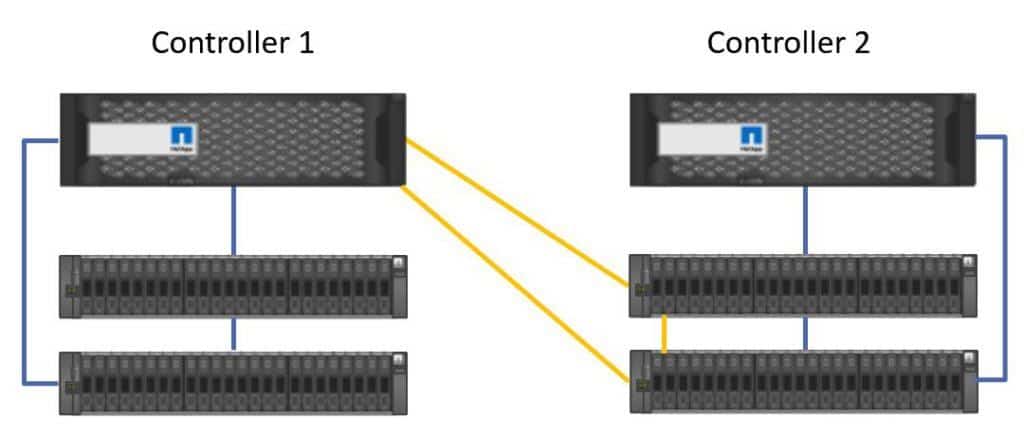
Controller 2 High Availability
This gives Controller 1 connectivity to Controller 2's disks. If Controller 2 fails, Controller 1 will be able to take over and serve the data.
We also need to provide protection for Controller 1, so Controller 2 is also connected to Controller 1's disk shelves in the same way.
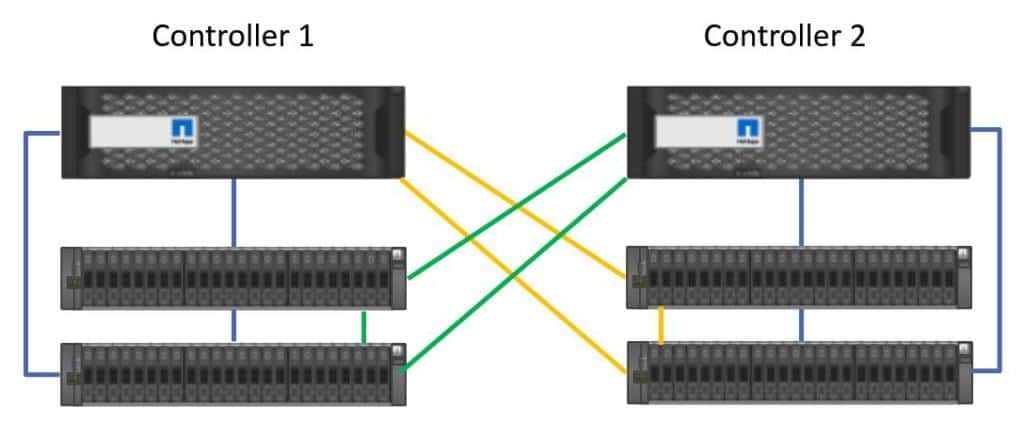
High Availability SAS connections
Finally we have the High Availability connection. The two controllers send each other keepalives over the HA cable. If keepalives are not received, the controller will realise the other controller has gone down and initiate a takeover.
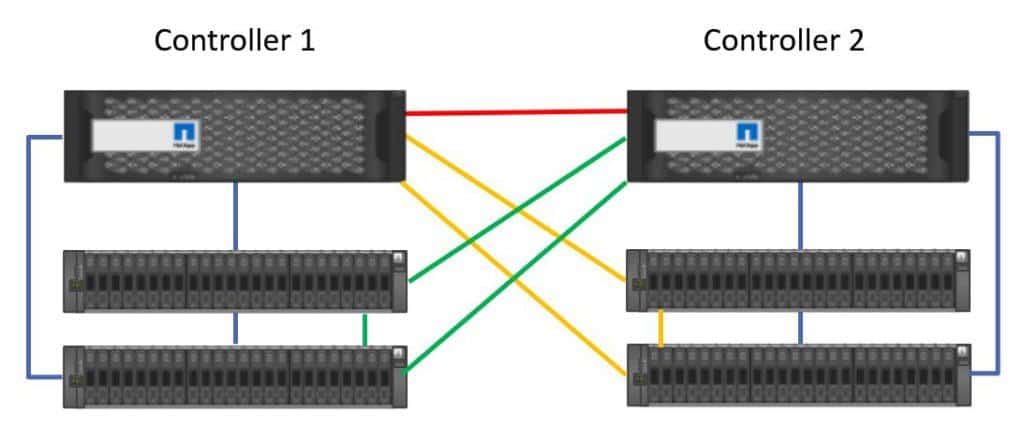
High Availability connection
IMPORTANT: With ONTAP, disks are always owned by one, and only one controller. This is true in both 7-Mode and Clustered ONTAP.
In the example below we have ‘Data Set 1’ which is on disks which are owned by Controller 1.

Data Set 1
Under normal operations, traffic from our clients for Data Set 1 will always go through a network port on Controller 1, and use Controller 1's SAS cables to the disk shelves.
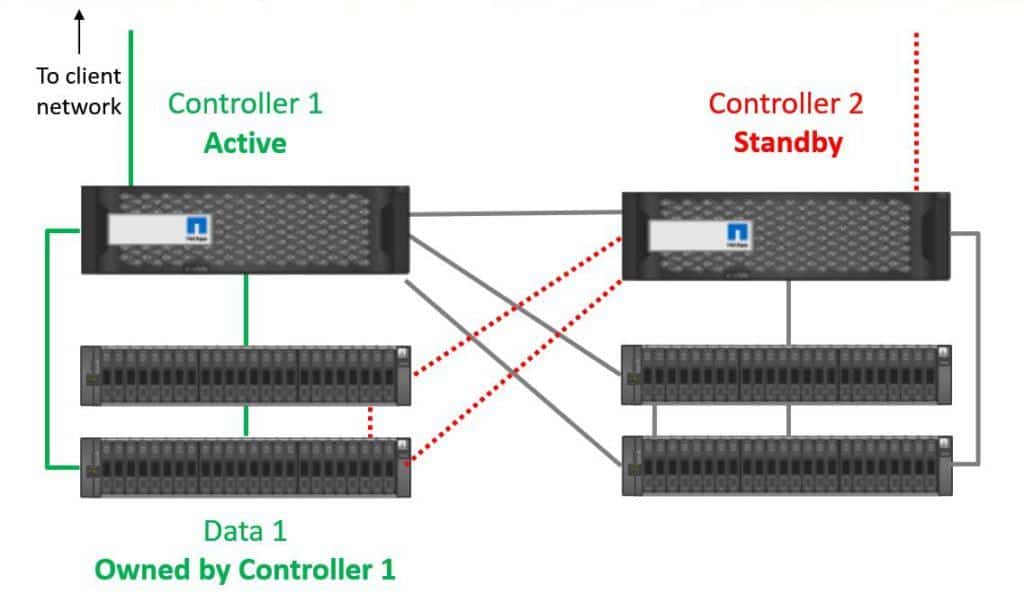
Controller 1 owns Data 1 disks
In 7-Mode, we don't get active-active load balancing through both controllers for the same set of data. Traffic for disks that are owned by Controller 1 is always going to go through Controller 1. Controller 2 is there as a standby only for that data. We do not get active-active load balancing through network ports to clients or SAS ports to disks through both controllers.
We do get active-active load balancing through our controllers for different sets of data however, because we're going to have Data Set 2 on disks that are owned by Controller 2.
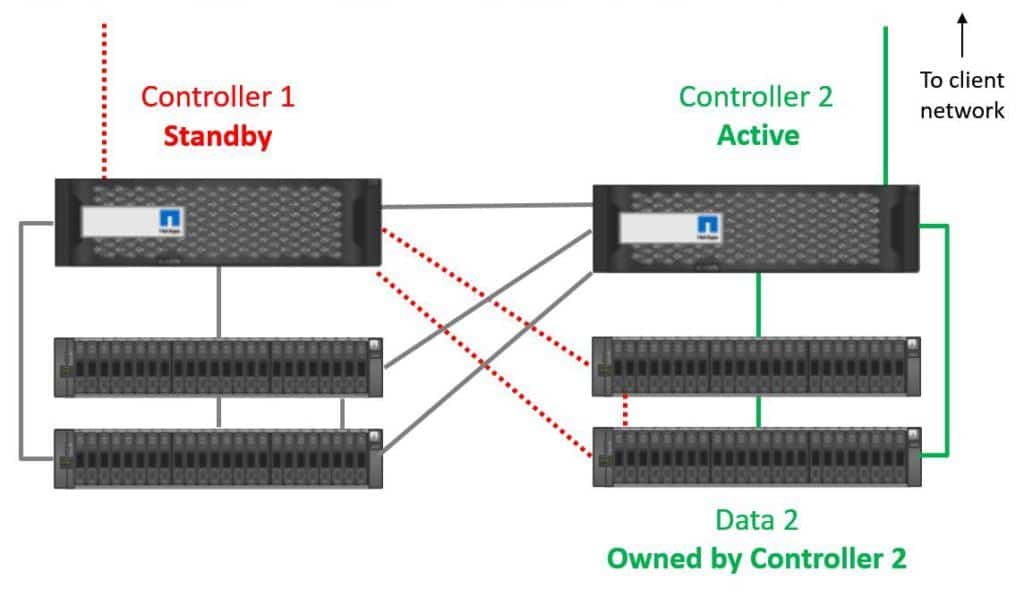
Controller 2 owns Data 2 disks
We get active-standby redundancy for Data Set 1, with Controller 1 being its active controller, and active-standby redundancy for Data Set 2, with Controller 2 being its active controller. As both controllers are actively serving data, this gives us an overall active-active system (just not active-active for the same data sets).
Controller Failover
Let's have a look at what happens if we have a controller failure. Controller 1 fails in our example.
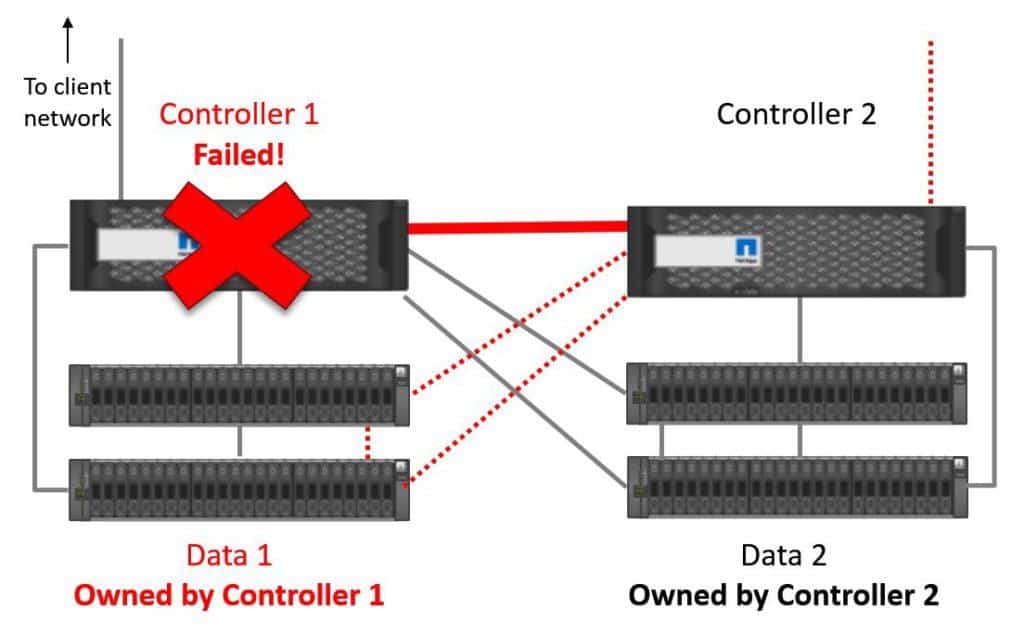
Controller 1 Fails
Controller 2 will stop receiving keepalives over the High Availability connection and realise that Controller 1 has gone down. Controller 2 will then take temporary ownership of Controller 1's disks. For NAS protocols, the IP address that the clients were using to access the data on Controller 1 will also fail over to Controller 2. For SAN protocols, multipath software on the clients will fail network connectivity over to Controller 2.
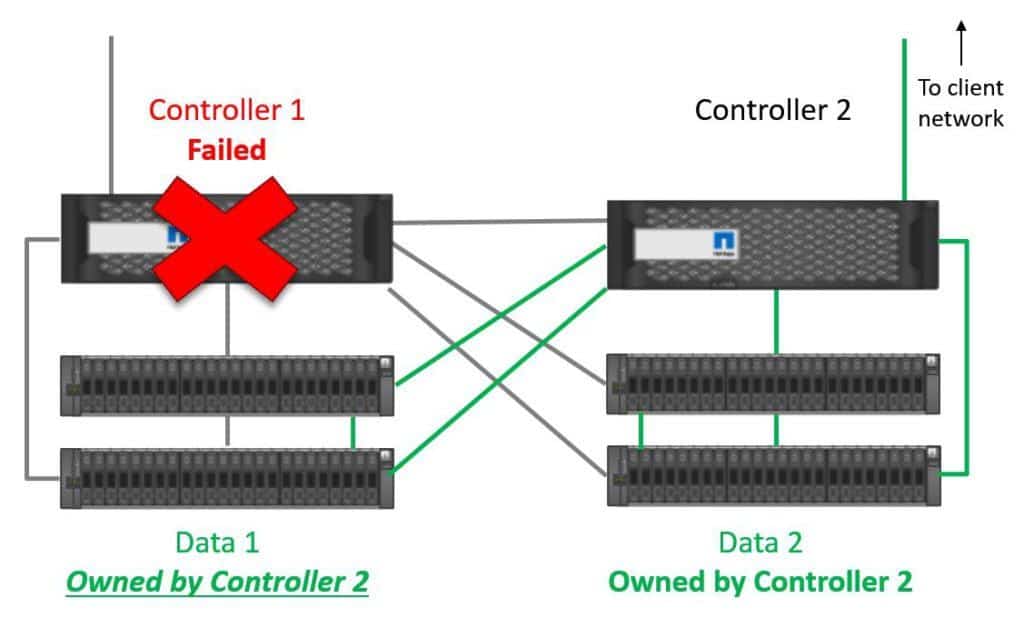
Controller 2 Takes Ownership of Controller 1's Disks
Controller 2 is now serving both Data Set 1 and Data Set 2. For this reason, it's recommended that neither controller runs at more than 50% load during normal operations. By limiting the performance utilization to 50% we’ll still have available capacity during a failover and get good performance.
7-Mode Scalability Issues
The maximum amount of controllers in a system is two. This is a limiting factor because there is a maximum throughput and storage capacity supported per controller. The capacity varies depending on the model. The higher end the controller, the more it will support. If you needed more capacity than is supported on a two controller system then you could deploy another pair of controllers, but this would be viewed as a separate system by clients. It would also be managed as a separate system and that increases complexity and operational costs.
7-Mode offers only active-standby redundancy for the same set of data, not active-active load balancing. We cannot combine the CPU, memory and throughput of multiple controllers for a data set.
It is typically disruptive to move data between a pair of controllers. This requires an outage if we want to rebalance data more evenly across controllers or if we want to move data to higher or lower performance disks on the other controller.
Clustered ONTAP (renamed to ONTAP from version 9) solves the scalability problems of 7-Mode. But I'll get to that in the next post which you can see here...
https://www.flackbox.com/netapp-ontap-hardware-architecture
Additional Resources
Command Map for 7-Mode Administrators
Click Here to get my 'NetApp ONTAP 9 Storage Complete' training course.