In this cloud training tutorial, we’re going to cover the cloud service model, IaaS, Infrastructure as a Service. Scroll down for the video and text tutorial.
This is part of my ‘Practical Introduction to Cloud Computing’ course. Click here to enrol in the complete course for free!
Cloud IaaS Infrastructure as a Service Video Tutorial

NIST defines IaaS as, “The capability provided to the consumer is to provision processing, storage, networks, and other fundamental computing resources where the consumer can deploy and run arbitrary software, which can include operating systems and applications.
The consumer does not manage or control the underlying cloud infrastructure but has control over operating systems, storage, and deployed applications; and possibly limited control of select networking components, for example, host firewalls.”

With IaaS, this is the service model that gives the customer the most control, they get access down at the operating system level.
Let’s have a look at that by looking at the data center stack. With IaaS, the provider will manage from the facility up to the hypervisor and the provider will also install the operating system and may patch it as well.
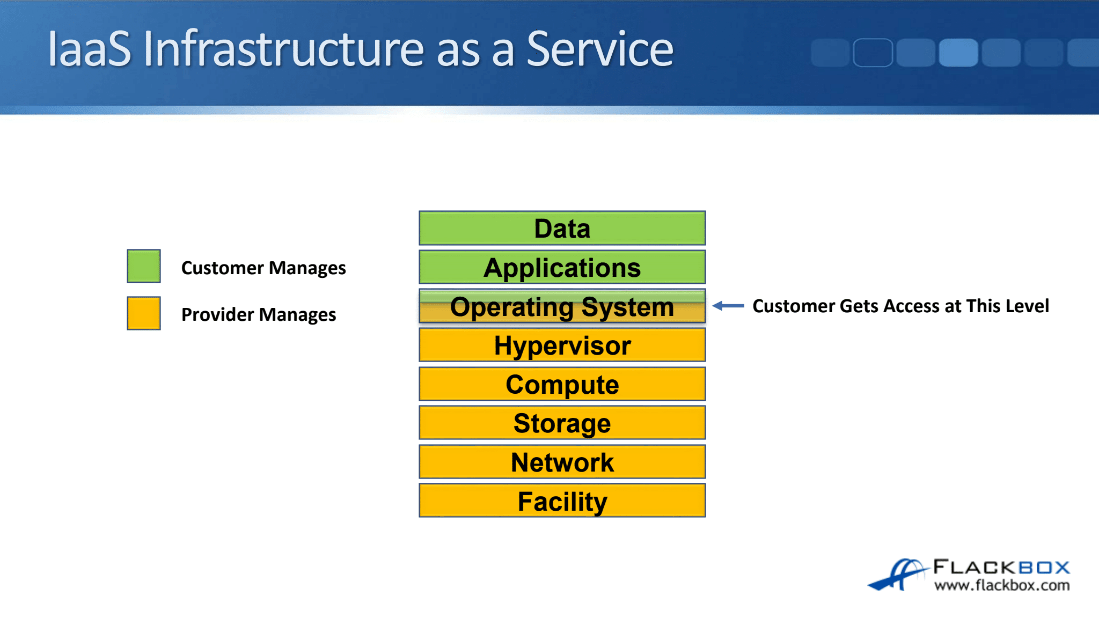
The customer gets access from the operating system level, so they can customize the operating system as they want, they also install the applications they want on there and they’ll be looking after their data.
Let’s have a look and see how that works in AWS. I’ve logged into the Amazon Web Services console and clicked on the instances tab and you can see the virtual machine that I created earlier.
I’m going to click on the connect button and I’ll get a pop-up. The first thing that I need to do is to find out what the administrator password is because this is the first time I’m connecting to this virtual machine. I’ll click on the get password button and then I need to browse to the Key Pair that I downloaded earlier.
In my downloads folder, there’s that Demo.PEM file, I’ll double click on that and now I can click on the decrypt password button and it shows me the password that was created for the administrator account.
I’m going to copy that into my clipboard and the next thing I’m going to do is download the remote desktop file, which is going to make it easy for me to connect with RDP.
I’ll click on OK to download that into the downloads folder. I will go to my downloads folder, there is the RDP file, I’ll double click on that and click on connect. Now I’m going to paste in the password that I copied and click on OK. Click YES, to the warning message and then this should log me into the desktop of the virtual machine that I created.
I can see my virtual machine is ready, I’m on the desktop now. I’m in Windows and what I would do now is I would install whichever applications I wanted to use this virtual machine for. Another thing that I would do at this point is to change the administrator password.
There’s a bit of a misconception where people think that if you’re on Infrastructure as a Service the cloud provider also has access to your machine so it’s not secure. That’s not that case at all, it’s a best practice that the first thing you do is change the administrator password and then it’s only you that has got access to the desktop of your virtual machines, the provider does not have any access at all. It is a secure solution.
You can see with Infrastructure as a Service that the provider is providing the underlying infrastructure and they installed the operating system for me, I get in at the operating system level at the desktop and I can do anything I want with the virtual machine from there.
Gartner IaaS Magic Quadrant
Let’s have a look at the most well-known IaaS providers through the Gartner IaaS magic quadrant below. Gartner is a research company and they research who are the biggest players in cloud services amongst a whole heap of other things. We’ve got Amazon Web Services up here in the top right.
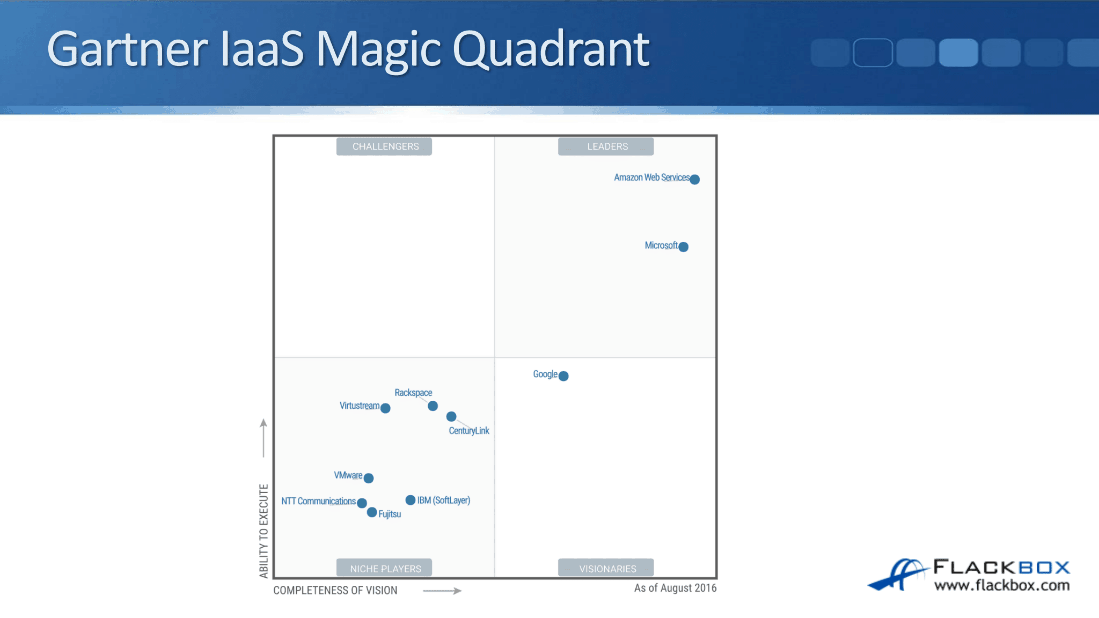
AWS is by far the biggest cloud provider. They’re currently bigger than all of their competitors combined, however, Microsoft Azure is gaining market share. They’ve been able to do that because it can be a very cost-effective option since pretty much all companies are Microsoft customers in some shape or form. They’re probably using Windows as their desktop operating system.
Because they’re already a Microsoft customer, they can get cheaper options for using Microsoft for cloud as well. AWS is still by far the biggest player with IaaS right now.
In the bottom section of the magic quadrant, you’ll see other well-known cloud services providers:
- VMware
- IBM (SoftLayer)
- Rackspace
IaaS Flavors
Different flavors are available for IAAS. Cloud providers will often offer three of these:
- Virtual machines on shared physical servers
- Virtual machines on dedicated physical servers
- Dedicated bare-metal physical servers
If you’re an IaaS customer, you don’t have to choose one of the three, you can mix and match between the three of them.

Virtual Machines on Shared Physical Servers
In virtual machines on shared physical servers, different customers can have their virtual machines on the same shared underlying physical servers.

Customer A could have a virtual machine on Physical Server 1 and Customer B could also have a virtual machine on that same shared underlying Physical Server 1. This is the least expensive option because you’re using shared resources. It’s cost-effective for the provider and they can pass those cost savings on to you as the customer as well.
Typically, it’s going to have the least amount of options in terms of how many vCPUs, RAM and storage settings available for the virtual machine out of the three possible flavors. The virtual machines can usually be provisioned more quickly than dedicated options. These can usually be provisioned very quickly, typically in less than 15 minutes. Since it’s the least expensive option, this is also the most commonly deployed option of the three as well.
Virtual Machines on Dedicated Physical Servers
In virtual machines on dedicated physical servers, the customer is guaranteed that the underlying physical server is dedicated to them.

If customer A has a virtual machine on Physical Host 1, no other customers are going to have any virtual machines on the Physical Host 1. Physical Host 1 is dedicated to Customer A.
This is a substantially more expensive option than virtual machines on shared physical servers because the provider has to dedicate physical hardware to the customer. It’s going to be a more expensive option.
There are typically more options here in terms of how many vCPUs, RAM and storage options are available for that virtual machine. Since the customer has got dedicated hardware, they may be required to sign a minimum length contract for this, but not necessarily. It depends on a particular cloud provider.
Dedicated Bare-Metal Servers
The last of the three options is the dedicated bare-metal servers. With these, a customer is given access to their physical server down at the lower server level.

A hypervisor is not installed and managed by the cloud provider. The customer can either install an operating system directly on the server or they can install and manage their own hypervisor.
This is the most expensive option of the three and it typically has the most options in terms of virtual CPUs, RAM and storage options that are available. Again, the customer may be required to sign a minimum length contract. AWS, who is the biggest cloud IaaS provider does not offer this option. With AWS, you only get the first two options currently. You can’t get a dedicated bare-metal server with them.
Looking at the data center stack where the provider is going to look after and where the customer gets in:
- Virtual machines on shared physical servers – Operating system level
- Virtual machines on dedicated physical servers – Operating system level
- Dedicated bare-metal servers – Compute level
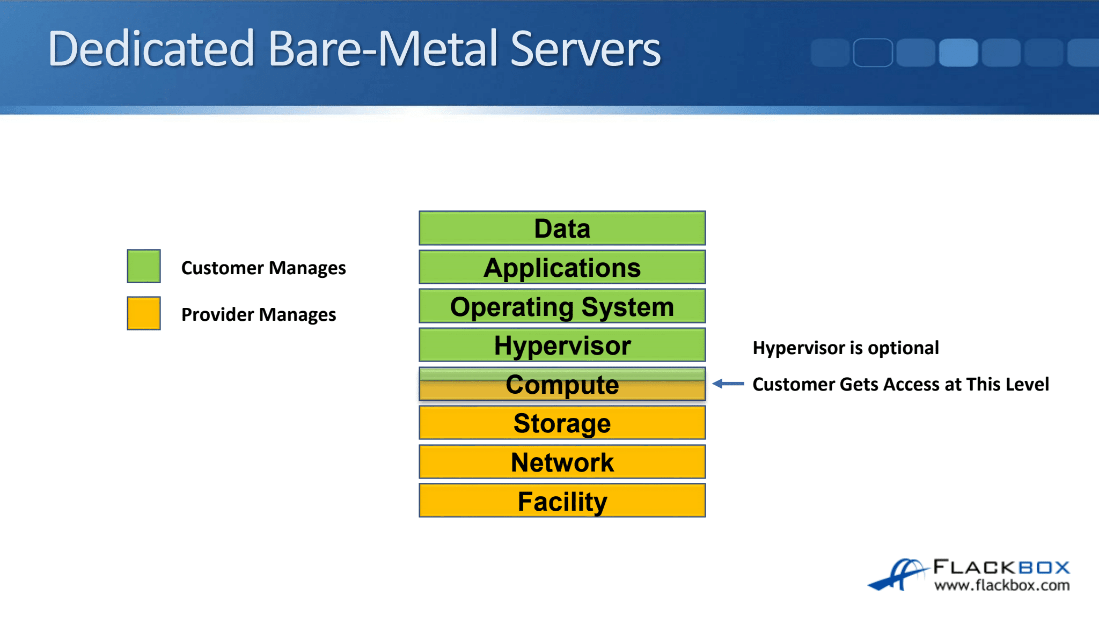
The operating system is not even installed yet, so the customer will get access using some kind of management application like IPMI or Lights Out, down to the physical server and they will be able to install the operating system from there.
They can install any operating system they want. They could install Windows or Linux directly onto the hardware, or they could install a hypervisor like VMware or Citrix Xen Server. The choice of the operating system is up to them.
The hypervisor is optional, maybe they have a hypervisor or maybe the OS is installed directly on the hardware. If the customer wanted to run just one workload on that particular physical server, let’s say they’re going to run an Oracle database and they want to have a high-performance server, then the Oracle database is going to be the only thing running on the server.
In that case, they would install the operating system directly onto the hardware. They wouldn’t put a hypervisor in there because it’s another layer. It’s another thing that can go wrong and it would add overhead as well. They’re going to want the best performance for that particular workload, therefore, they would install it directly on their hardware.
Virtual Machines on Dedicated Physical Servers vs Dedicated Bare-Metal Servers
The most common reason to choose virtual machines on dedicated physical servers is for compliance. The customer may have some kind of regulatory requirement that means that they can’t have virtual machines on shared physical servers.

Dedicated bare-metal servers will also fulfill the same compliance requirements. Both of these options require dedicated physical servers for the customer. The cost is typically similar, with bare-metal servers maybe being a little more expensive.
One reason a customer may prefer virtual machines on dedicated physical servers is if they do not have expertise in-house to manage the hypervisor. In dedicated bare-metal servers, running a hypervisor will require them to install it and manage it themselves. Therefore, they’ll need their staff with expertise in that area.
With virtual machines on dedicated servers, the provider is going to install and manage the hypervisor for them. They will just choose the operating system they want when they spin up the virtual machine and they get in at that level. That’s the better option if they don’t have IT staff who have got expertise in server virtualization.
Network Options
Customers can also be offered options for shared or dedicated network infrastructure appliances like firewalls and load balancers.

Again, it depends on the particular cloud provider if they’re going to offer those options or not. Customers can typically connect into the cloud providers’ data center over the internet and/or via a direct network connection.
Storage Options
With the storage options, the customer will typically have the option of local hard drives in the:
- Server
- external SAN
- NAS
The customer also has the option of managing their own storage operating system on a virtual machine or bare-metal server.

With IaaS, the customer gets in at the operating system level, so they could install some storage management software in the operating system and look after their own storage. The most common reason for doing this would be if they want to look after their own encryption.
The customer may also be able to install their own whole physical storage system in the cloud providers’ data center, so maybe they’ve got a storage system from a company like Net App or EMC. They can install that in the data center and connect their servers into that. Again, it depends on the individual cloud provider.
Management Options
The customer can manage their servers to install applications, patches, etc., through standard remote management methods such as:
- Remote Desktop for Windows Servers
- Secure Shell for Linux
API is also typically available to allow for automation of common tasks, such as provisioning a new virtual machine.

Application Options
The customer may also have the option of applications such as Microsoft SQL or antivirus. For the installation of the application, they can either:
- Install the application and look after the licensing themselves – Capital Expenditure (CapEx)
- The cloud provider will do it for them – Operational Expenditure (OpEx)

What I’m talking about here is when the customer gets in at the operating system level and they want to run SQL Server on their virtual machine, they could install SQL Server themselves and they would have to provide the license.
If the provider provides this option, the provider can install SQL for them and then the customer just pays for the license as a monthly fee to the service provider rather than providing the license themselves.
The cloud provider may also offer to manage the application as well. They might have, in our example, SQL database administrators on the provider’s staff who can look after the database for the customer.
IaaS Billing
Let’s have a look at how the billing works with IaaS. For virtual machines on shared physical servers, the CPU and RAM will typically only be billed when the virtual machine is powered on.
The physical CPU and RAM in the underlying server hardware will be available for use by other customers when the virtual machine is powered off. The provider isn’t going to charge you as the customer for CPU and RAM usage when you’re not using it because you’ve powered the server off, so you can get some cost savings there.

Network bandwidth will be billed as it’s used, some usage will typically be bundled in if you’ve got a monthly plan. Data storage will typically be billed whether the virtual machine is powered on or off as the data is always going to be there and taking up physical storage space. Optional software extras, such as a Windows operating system or a SQL server will be billed as a flat monthly fee.
If you’ve got Linux in your virtual machine, Linux is a free operating system so there’s no additional charge for that. But if you want to be running Windows in your virtual machine, then, there’s a fee for that operating system, so the service provider will include it in the charge.
Let’s have a look at some examples of billing. In AWS, let’s use AWS simple monthly calculator which is a tool that you can use to estimate what your monthly charge is going to be every month.
The first thing we do is up at the top we chose the region because there’s a slightly different charge for different regions. I will choose Singapore in here, and then under the Amazon EC2 Instances, you add your virtual machines that are on shared servers.
I’ll click on the plus button and then select the type. Let’s say that we have got a virtual machine which has four vCPU cores and 16GB of memory, that’s the type T2 extra-large in Amazon. I’ll select that, and close, and save.
You can see that the monthly fee for this server if I had it powered on 100% of the time, would be a little over $175. You can also select your other options here as well, for example, I also required 500 gigabytes of SSD storage. When I enter my additional storage, that cost will be added as well which was another $50 per month. Further down you can add all of the other options. So that’s how you can figure out your bill on AWS.
Let’s look at another example, we’ll have a look at Telstra’s pricing structure. I’ve opened up their pricing guide, which comes as a PDF.
Telstra is the main Telco in Australia and they also offer IaaS services. Telstra offers both virtual servers and dedicated servers. Let’s have a look at how the billing works for the virtual servers on shared underlying infrastructure.
Telstra uses a monthly plan structure. If you spend $200 a month with them you get the extra small plan where you get two vCPUs and 4 GB of RAM, if you go up to $4000 per month you get 64 CPUs and 256 GB of RAM.
These vCPUs and RAM can be divided up amongst multiple different virtual machines. For example, you could have eight virtual machines with eight cores each, or you could have 16 virtual machines with four cores each. You can mix and match.
They also have a pay as you go plan as well but you get a bit of a discount if you avail one of the monthly plans.
Cloud IaaS Infrastructure as a Service Design Example
Now, I will show you the basics of how to do an IaaS design. The reason I’m going to do this is that if you are moving from purely On Premises to a Cloud solution, you can be tasked with doing the design.
 IaaS Design
Designing an IaaS solution is just like designing an On Premises solution which is accessed from a remote office. It uses the same data center design principles, it’s just that the data center hardware is in the Cloud Provider’s facility instead of in yours.
The hardware components that you’re going to use are the same, the way it’s all networked together is the same, the way it’s accessed is the same, and the way it’s secured is also the same.
|
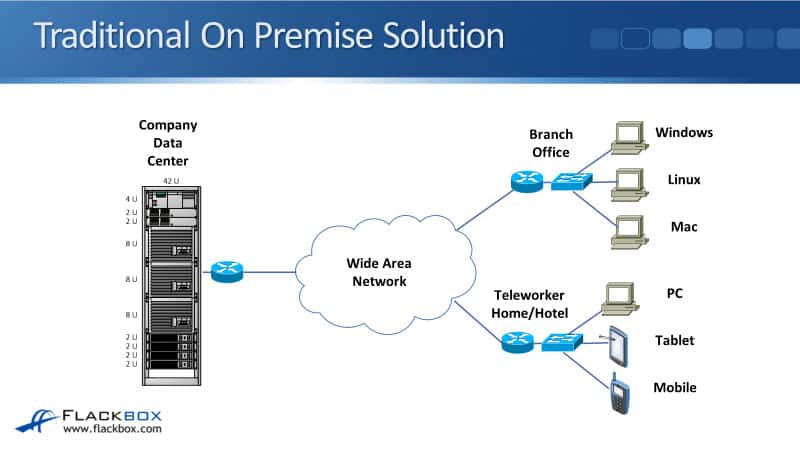
Traditional On Premise Solution
How the network looks like in a traditional On Premise solution is shown below. We’re accessing our servers in the company data center over on the left, from branch offices over on the right. From teleworkers working from a hotel or at home, for example.
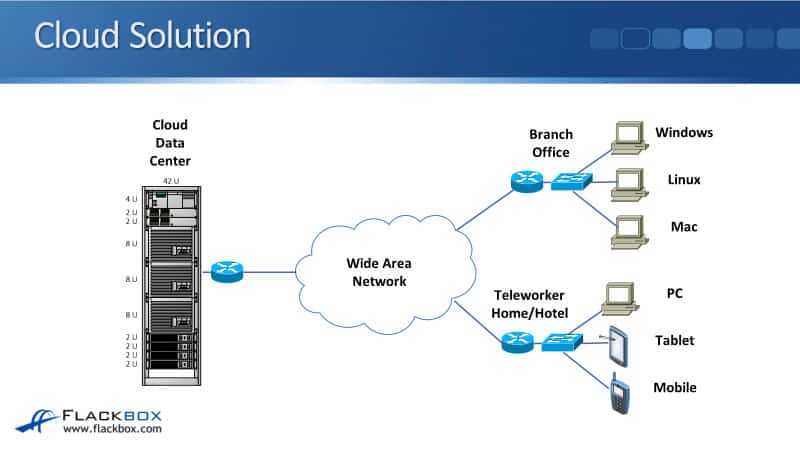
Cloud Solution
That’s how it looks like, that’s how we do the network design for a traditional On Premise solution. How the network looks like for a Cloud IaaS solution is exactly the same.
The only difference is that the servers are now in the Cloud providers data center rather than in our data center. For doing the design, we do the design just the same way as we’ve always done it traditionally.
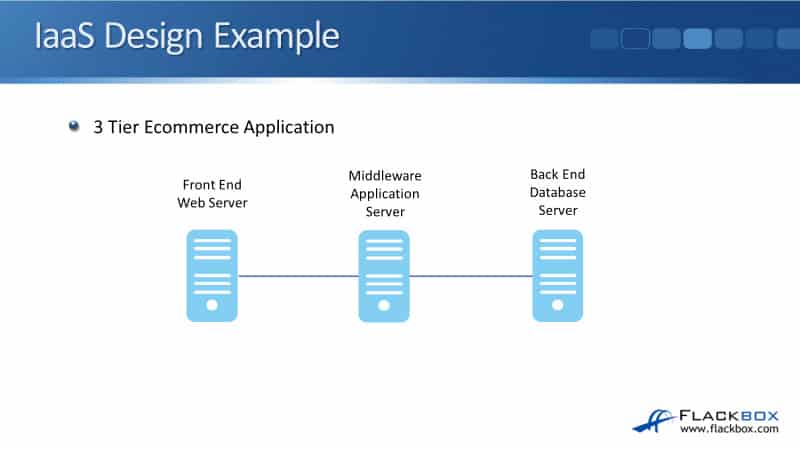
IaaS Design Example
|
|
In the example, I’m going to use a pretty standard three-tier eCommerce application:
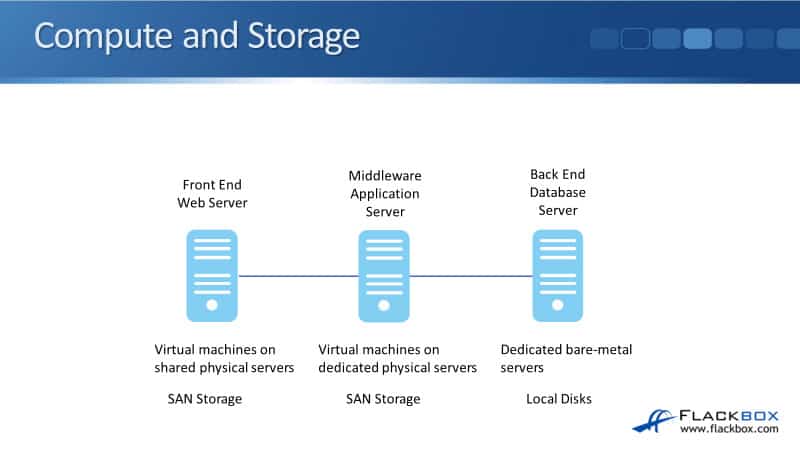
Compute and Storage
The first thing to consider is what are we going to do for compute and storage, and we need to figure out of those three flavors of IaaS, what are we going to use for the different types of servers?
Front end web servers:
|
|
For the middleware application server:
Database server at the back end:
|
|
That’s the compute taken care of, we’ve made those decisions. The next thing to consider is what are we going to do for the storage.
For the front end web server and the middleware application servers, we’re going to have multiple of those servers, but they’re all going to have the same content on there.
We’re going to put the contents into a Server Farm for both types of the two different servers. The easiest option we’re going to have for the storage there is to use SAN storage for them.
For the back end database server, let’s say that for this example we have got high-performance requirements for the storage as well, we need a certain amount of IOPS there, so in that case, we’re going to use local discs in that dedicated bare-metal server to get the highest possible storage performance.
Networking |
|
The next thing we’re going to look at is networking. With this three-tier eCommerce application, traffic is going to come in from external customers over the internet.
It’s then going to hit our front end web servers where the customers will be able to browse our catalog and be able to put things into their shopping carts. From there the traffic then hits the application server middleware, and from there it goes to our database servers at the back end. So that’s the traffic flow. |
|
I’m going to have a firewall in front of my web servers to make sure that traffic can only come in as web traffic on port 80. I’m going to have a local load balancer as well because I don’t just have one web server. I’m going to have more connections coming in than one server can handle.
Also, I don’t want to have a single point of failure. I’m going to have multiple web servers which are all identical copies of each other, they’ve got the same content, and I’m going to put them into our server pool.
The local load balancer in front of them is going to balance the incoming connections to the different servers that are on my Server Farm. I’ve got a global load balancer on the outside as well, I’ll talk about it in the disaster recovery topic below.
|
|
So, I’ve got my firewall and my load balancer in front of my front end web servers. I’m going to put my application servers into a different subnetwork because the traffic should never hit the application servers directly from the internet.
I’m going to have a firewall in front of the application servers and they’re going to be in a different subnet. The traffic is only going to be allowed to get to the application server if it’s coming from the web servers and if it’s coming through the correct port number. I’m doing that to secure them.
Again, I don’t just have a single application server. I’m going to have multiple servers to handle the volume of traffic and because I don’t want a single point of failure. Therefore, I’m going to have an application load balancer in front of my application servers to load balance those incoming connections.
|
|
At the back end of my database server, traffic should not hit the database servers directly from the internet or the web servers. I’m going to have a firewall in front of them, I put them in a different subnet, and on my firewall rules, I allow traffic from the application servers on the correct ports.
I don’t have a load balancer in front of my database servers, because for this example application, that is handled within the application itself. I’m going to have at least two database servers because I don’t want to have a single point of failure.
|
|
Other things to talk about here, the Server Farms can be automatically scaled. With those web servers and the application servers, they’re identical, they’ve got the same content on them. I can build an image of those ahead of time.
Then, I can configure a threshold where I say that if the load on my existing servers goes above a certain level, I’m going to automatically spin up an additional server and add it to the server pool.
The load balancer will add it to the servers that it’s going to be sending the incoming connections to. Therefore, I can automatically scale up and scale down the number of servers I have in line with the current demand.
|
|
With the traffic flow we’ve discussed there, that was for traffic coming from external customers to do their shopping. We also need to consider management traffic as well, because our own IT engineers are sometimes going to need to get onto those servers to do maintenance.
For incoming management connections, our engineers can either use a virtual private network (VPN) over the internet, or we could set up a direct connection from our office into the cloud provider’s facility.
Backups |
|
We need to consider backups in the same way as we would with an On-Premise solution. The Cloud Provider will not automatically back up your data.
This is another bit of a misconception or misunderstanding some people have about Cloud. They think if they have their servers deployed as a Cloud solution, it’s in a hardened data center, there are no single points of failure, and backups will be automatically taken as well.
That is not the case. The service provider is not going to back up your data by default, you need to provide that.
The data center is a hardened facility with no single points of failure if you’ve designed your solution like that, but that doesn’t protect your data against regional disasters, the entire data center going down, or data corruption.
|
|
If we look back at the previous slide you see with my database servers here, I’ve put two of them in there for redundancy, but if my data gets corrupted, it’s going to get replicated between both of them.
It’s going to be corrupted on both servers, so having two servers isn’t going to help me, I need to take backups in case I need to do a restore from a previous version.
You have network connectivity to the Cloud facility, so one of the ways you could configure your backup is you could backup back to your own premises office, and use your existing backup solution. So you could back up to tape in your office for example if you wanted to.
|
|
You can also back up to the Cloud Provider’s storage. If you are going to back up your data to the Cloud Provider’s storage make sure you’re backing up to a different data center than where your servers are located.
Again, we might have that regional disaster, if we lose the entire data center, it’s not going to help us much if our backups are also in the same data center. Data should always be backed up to an offsite location.
|
|
The next thing to talk about is disaster recovery. If the data center is lost, you’ll be able to recover to a different location, to a different data center from those backups as long as they were stored offsite. In that case, you’ll lose all new data since the last backup was taken.
We’re talking about RPO here, the recovery point objective. What RPO means is in the worst-case scenario, how much data could you lose if you have to restore to a different location?
For example, if you’re taking backups every night, your RPO would be 24 hours, because the worst-case scenario would be you had the disaster just before you take the next backup. So all of the new data that was written today since the last backup is going to be lost.
The best-case scenario would be that the disaster occurs just after we’d taken the back up. When we talk about RPO, it’s the worst-case scenario we talk about. So if you’re recovering for backups and you take a back up every day, your RPO would be 24 hours.
|
|
It could take a significant amount of time to deploy the infrastructure in the new location and store the data as well. Just like we’ve got the RPO, the recovery point objective, we need to consider the recovery time objective as well.
Using our same example again, let’s say we’re going to just restore from backups, so our RPO is 24 hours. When we do a failover to the new location, it’s not like, bang, we can just click our fingers and everything is going to be back up and running.
We’re going to have to do the restore which is going to take time. We’re also going to have to deploy our new servers. We’re also going to need to configure our firewall rules, configure our load balancing, et cetera, that’s all going to take time.
|
|
The RTO is going to be how long it takes to get back up and running again. It’s not as easy to calculate this like it is with RPO, the RTO, if you need to calculate this you need to do a test recovery. So do a test failover at the new site and see how long it takes you to get back up and running again.
|
|
Okay, so if we are just restoring from backups, you can see there that the RPO and the RTO are going to be quite long, and that might not be acceptable. You may want to provision a disaster recovery solution to reduce the RPO and RTO.
Disaster Recovery
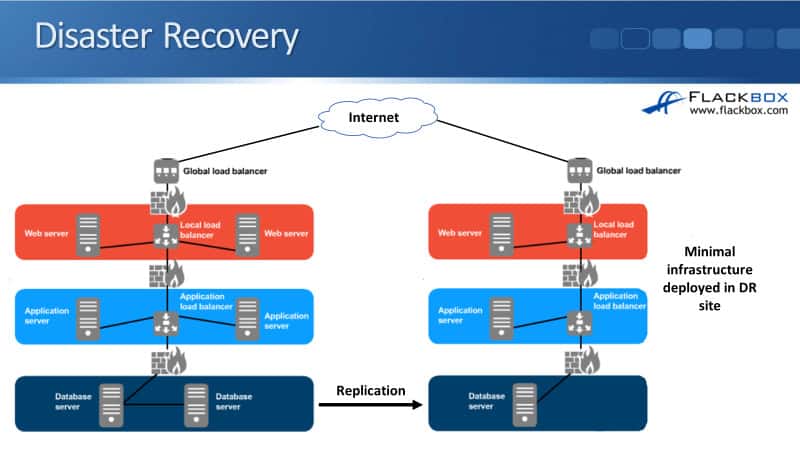
On the left is the same Cloud solution that we deployed. This is the main site here, customers are going to be coming in over the internet and we’re going to be hitting our three-tier application in the main Cloud data center on the left. But we want to have a fast disaster recovery solution available as well.
|
|
What we’re going to do for that is in a different data center, we are going to provision a web server, application server, and database server, and configure our load balancer and Firewall rules as well.
We’re going to have the infrastructure already set up ahead of time so that if we do have to failover, this is going to give us a fast RTO because we’re ready to failover when we need to.
We are also going to need the data to be available in that disaster recovery site as well, so we’re going to need to replicate the data from the database servers on the left in the main site, to the database server in the DR site.
I don’t need to replicate my web servers and application servers in this example, because they are just using static content, so I can deploy these from images.
|
|
The last thing to mention here is my global load balancers. They’re there to direct incoming connections to the correct data center. In normal operations, incoming connections will get directed to the main site.
If the main site goes down, I will failover to the DR site and my global load balancer will direct new incoming connections there. You only need the global load balancer if you’ve got a disaster recovery solution. If we only had our servers running in one site, we wouldn’t need that component.
|
|
Now obviously if you’re going for this kind of disaster recovery solution rather than just backups, it’s going to be more expensive because you do need to deploy additional infrastructure in the disaster recovery site, but this is going to give you reduced RPO and RTO.
We’re typically not going to deploy exactly the same infrastructure in the disaster recovery site as in the main site, because this is just a backup site, we’ll just put a minimal infrastructure in there to give us the most cost-effective way of doing this.
Additional Resources
What is IaaS? Your data center in the cloud: https://www.infoworld.com/article/3220669/what-is-iaas-your-data-center-in-the-cloud.html
Cloud Architecture Principles for IaaS: https://uit.stanford.edu/cloud-transformation/iaas-architecture-principles
Libby Teofilo Text by Libby Teofilo, Technical Writer at www.flackbox.com Libby’s passion for technology drives her to constantly learn and share her insights. When she’s not immersed in the tech world, she’s either lost in a good book with a cup of coffee or out exploring on her next adventure. Always curious, always inspired. |