
In this Cisco CCNA training tutorial, you’ll learn about Retrieval-Augmented Generation (RAG) for Large Language Models (LLMs). Scroll down for the video and also text tutorials.
Cisco Retrieval-Augmented Generation (RAG) Video Tutorial

Daniel Sauerbier

Neil, just wanted to say thank you and that you have another success story! I successfully passed my CCNA on the first try using just your course and AlphaPrep. The exam was not easy by any means – thank you for all of your hard work. You truly have a gift for teaching. Keep up the good work!
LLM Hallucination
Large Language Models are susceptible to hallucinations where they generate incorrect output data. Consider a router configuration that contains errors. This is because the training data that this particular LLM was trained on did not include information about routing configurations.
If you put in a query to an LLM asking it to create a configuration, LLMs are not good at saying they don't know. They will provide you with an answer, but if they don't actually know the answer, it will contain incorrect information. This is a known problem with LLMs.

General LLM models are excellent at generating natural text. They've been trained on a huge amount of text, so they're able to speak in a natural kind of language. However, they can fall short when technical knowledge of a topic or up-to-date information is required.
Generally, when the LLM is created, it's got that data set. It is trained on that data set, which is going to give it general information and train it to speak naturally.
But once that's done, it's not common for it to be updated again after that. So, it's only up to date to when it was actually trained.
You might be able to incorporate data, such as a running configuration, into an input prompt for an LLM, providing it with some context. However, the maximum length of the prompt is limited, making it a less scalable solution.
Ways to Reduce Hallucination
How can we reduce hallucinations? Well, you could build a new LLM model your own from scratch and build it with a relevant data set with the data that it's going to be actually used for. For example, you could incorporate network configurations into your model.
However, creating an LLM can often run into millions of dollars. This is obviously out of the reach of organizations. The cost is high because it requires a significant amount of expertise, time, and compute resources. That's really just not feasible.

The next option is fine tuning. This involves taking a pre-existing LLM and loading additional relevant data into it. Then use techniques such as backpropagation to tune it.
There are public LLMs available. You can download one and add your own data. When you add your own data, you must tune it to get the right output.
Doing that is not as expensive as building a new model from scratch, but it's still very costly and time-consuming because you're going to need experts who know how to tune the LLM. It also carries the risk of the model forgetting previously learned information.
This is a known issue that can occur if you add data to an existing LLM. It can actually cause it to forget information that it has already learned. Both options are impractical for keeping the data up-to-date.
Again, you've got the same issue there that once an LLM is trained, you're typically not going to be adding new data to it again, because if you do that then you would need to retrain it again.
You would need to do the back propagation again to make sure that there's no errors. So those are really not feasible options, typically.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) enhances the accuracy and currentness of an existing LLM. That's the solution for those problems, and the way it works is it uses an external database.
You've still got the LLM. You've got an external database as well, which is where you add your relevant and up-to-date information.
When queries come in, it uses both the LLM to generate the language in the response and also the external database, so you've got relevant contextual information that can be constantly kept up to date as well.

Nearly any LLM can use RAG. It's all running on standards. It's relatively easy to implement with public tools and knowledge bases available, so your organization could be using a public LLM. You can download those readily available tools, and there are also public knowledge bases.
There might be one that already has the relevant information for your particular scenario there. You can also utilize internal knowledge bases, which are kept private.
So you can take a public LLM, and then you can create your own private knowledge base to use as an external database. You can utilize this internally, ensuring that your internal knowledge base remains secure from public leaks.
How RAG Works – Creating the Database
How does RAG work? Well, first off, we have to create that external database. You need your knowledge base first. That can be things like running configuration examples, articles with relevant information, etc.
Then, with that typically text-based knowledge base, you're going to do preprocessing first. The knowledge base is split into tokens and chunks. For instance, a sentence that requires loading must be searchable.

You split that into tokens, which could be the words or even smaller in that sentence, and then they are expanded into chunks, which are a bit longer but still smaller than the overall sentence.
You split the knowledge base into tokens and chunks, then convert it into a machine-readable numeric vector format.
An embedding model creates vector databases optimized for search and retrieval. So you've got your knowledge base, which is all your text articles that get split into tokens and chunks with pre-processing and converted to the machine-readable format.
Then it is the embedding model that takes that information and creates the vector database from it. The vector database is optimized for searching for that relevant information, which is in your knowledge base.
In the background, the embedding model continuously updates the vector database as the knowledge base is updated.
Therefore, when you add new information to your knowledge base, the embedding model automatically updates the vector database with this new information. It's automatically kept up-to-date.
Then once your vector database has been built and you've got your LLM, then your users can start sending queries and they can start using the LLM.
How RAG Works – User Queries
When users enter a query, the embedding model converts it into that numeric format again, which is compared to the vector database for any similar relevant information.
Matches are then retrieved and sent to the LLM along with the query. The LLM combines the retrieved entries from the knowledge base with its own response to create the final output for the user.
Therefore, the LLM creates natural language in the response, ensuring technical accuracy and up-to-dateness by utilizing information from the database.

Let's take a closer look at the diagram. First off, we need to create the vector database. We have already established our knowledge base. The information that we want to add goes through preprocessing using some software to break it down into tokens and chunks.
The embedding model then uses this information to create the vector database. After that, the user interacts with an AI application, like a chatbot.
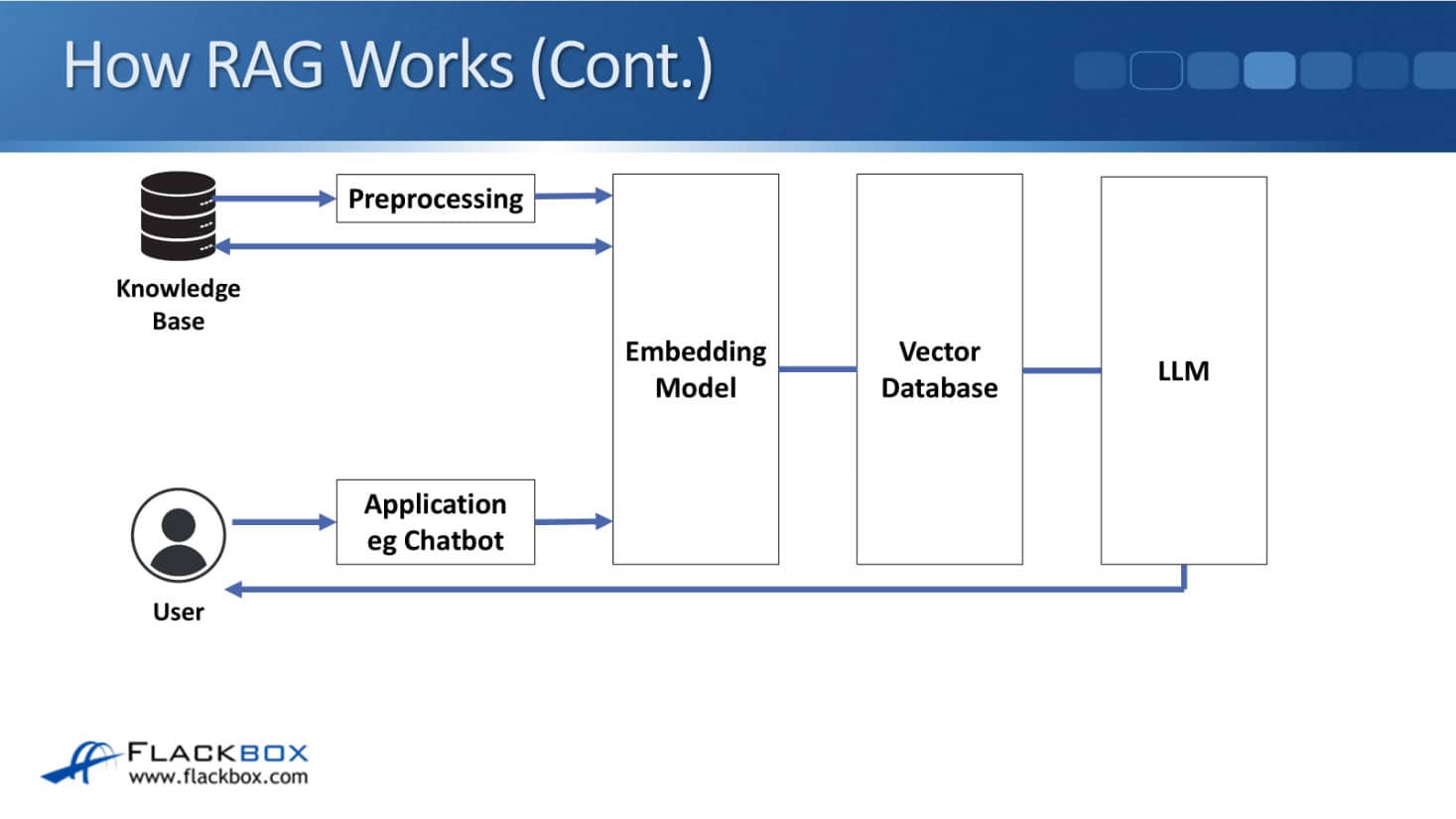
For example, they say, "Please show me an OSPF configuration example for this particular scenario. I've got these routers with these interfaces and networks." They send that to the chatbot and it will then go to the embedding model.
It's converted to the numerical format, and then the embedding model checks the vector database for similar contextual information to that.
When it finds some, that then gets sent retrieved. It gets fetched from the knowledge base, and that relevant information gets sent to the LLM along with the user query.
The LLM is then able to create the response using that relevant information as well, and that is what is sent down to the user.
RAG Usage in Network Operations
How can we use RAG in network operations? One example is configuration generation in your knowledge base. You could include different configuration examples.
Now, when a user sends in a query asking the LLM to generate a configuration for it, it can use that relevant information.
You can also use it to help with troubleshooting. Your knowledge base can contain relevant IT articles and previous incident reports from inside your organization and their solutions.
Thus, it's highly relevant, and whenever there's new incident reports being created, you add that to the knowledge base and the solution as well.

If a network engineer uses the chatbot and says, "I'm experiencing this issue, could you please suggest a solution?" The LLM is able to do that. You can also use it for up-to-date documentation generation. You can load information about your network devices into the knowledge base.
Then, you can ask your AI application, please create a network diagram for me. It's able to do it because it's able to look up that information. The database can be constantly updated, and this is really useful for keeping your documentation updated as well.
The last example is predictive maintenance. Your knowledge base may contain previously implemented maintenance schedules for any anomalies or hardware that failed earlier than usual.
It also includes the environmental data, heat levels, and vibration statistics for your devices. Your AI could then perform predictive maintenance, identifying areas where this specific hardware may fail early. We recommend you check it or maybe swap out a part.
Additional Resources
Cisco Generative AI Models: https://www.flackbox.com/cisco-generative-ai-models
What is Retrieval-Augmented Generation (RAG)?: https://cloud.google.com/use-cases/retrieval-augmented-generation
Generative AI, Retrieval Augmented Generation (RAG), and Langchain: https://community.cisco.com/t5/security-blogs/generative-ai-retrieval-augmented-generation-rag-and-langchain/ba-p/4933714
Libby Teofilo

Text by Libby Teofilo, Technical Writer at www.flackbox.com
Libby’s passion for technology drives her to constantly learn and share her insights. When she’s not immersed in the tech world, she’s either lost in a good book with a cup of coffee or out exploring on her next adventure. Always curious, always inspired.