
In this Cisco CCNA tutorial, you are going to learn about the Cisco Troubleshooting Methodology and the different troubleshooting methods. Scroll down for the video and also the text tutorials.
The Cisco Troubleshooting Methodology Video Tutorial

Shah Ali

I just wanted to reach out to you to let you know how great your lectures are! With all the labs and scenarios you presented, it really helped me grasp routing and switch fundamentals which ultimately allowed me to pass the exam!
The Cisco Troubleshooting Methodology
Below is the official Cisco troubleshooting methodology diagram, and this is the recommended way by Cisco to work through troubleshooting a problem. To be honest, as you get more experienced, you'll be able to troubleshoot naturally without using a diagram like this.

This is quite useful if you're new to networking. It lays out in a logical fashion the steps that you can follow to figure out what's causing a problem. Up at the top, the first thing to do is to define a problem. This clearly specifies exactly what the problem is. Once you've done that, you then move into gathering information. This is to find out information about the problem.
For example, we've got a connectivity problem. We would check to see if we can ping from the source to the destination. If not, we would find out if it is just affecting that one host, or is it affecting other hosts in the same area?
If it's only affecting that one host, the problem is probably with that host. If it's affecting everybody on that IP subnet, then it's probably not a problem at the host level. It's probably something in between the host and the destination.
We would then find out other information, like asking has anything changed recently, if it was working before? If it was working before and now it's not, find out what's changed, and that's probably going to tell you what the problem is.
The next thing to do is to analyze that information. Ask all of the relevant questions, not just asking questions to people, but also using show and debug commands on your devices to get the information. Then, analyze that information and look for clues about what's causing the problem.
You can then move on to eliminating potential causes. For example, if we're troubleshooting that connectivity issue, from a source to a destination and there are several routers between the source to the destination, if we check the first hop router and the configuration all looks good there, we can eliminate that as the cause and then check the next hop router along the path.
Next is to propose a hypothesis. Taking all the information into account, you will determine what appears to be the most likely cause of the issue. Then you test the hypothesis where you actually put the commands in or do the thing that would fix that problem.
If the problem is fixed, you've solved the problem. We're down at the bottom now. The last thing to do is to document the solution. Now, this is something that's not fun to do, but it's important to do it. If you do get into the habit of doing it, you'll thank me later because, sooner rather than later, you will run into a problem that somebody else ran into the exact same problem before.
If you've got proper documentation in place in your organization, it should be very easy and quick for you to find a solution because somebody's documented that problem and the solution. If you're not doing any documentation, if it took an hour to fix it the first time, it's going to take you an hour to fix it this time as well. Whereas, if you had documentation, maybe it's only going to take a few minutes.
Also, this is not just for other people that may be facing the same problem as you afterward. It's for yourself too. Maybe you run into the same problem but a year down the line, and you can't remember exactly what the issue was. But if you've got the documentation there, you'll be able to quickly look it up and quickly find a solution.
That's your standard way to troubleshoot from start to end. You'll notice there are some other arrows and arrows going in different directions as well. Sometimes, we can move straight from the gather information stage to the propose hypothesis stage.
If this is a problem that you've seen before, and you're pretty confident it's the same thing again, you don't have to spend time gathering additional information. Just put in your solution that you think is going to work and see if it works or not. Also, often we can move back to an earlier stage if we don't manage to fix a problem the way that we thought we were going to.
Troubleshooting Methods
For the troubleshooting methods, again, experience is really going to help you here. Sometimes it makes sense to do a Top Down approach, sometimes a Bottom Up approach, and sometimes Divide and Conquer. What I'm talking about here is, as it relates to the OSI stack.
Some problems just make more logical sense to start off at the Application Layer and troubleshoot it moving down through the layers. Other times, it's easier to do it the other way around, where you start troubleshooting at the Physical Layer and then move your way up through the layers. Other times again, you can Divide and Conquer.
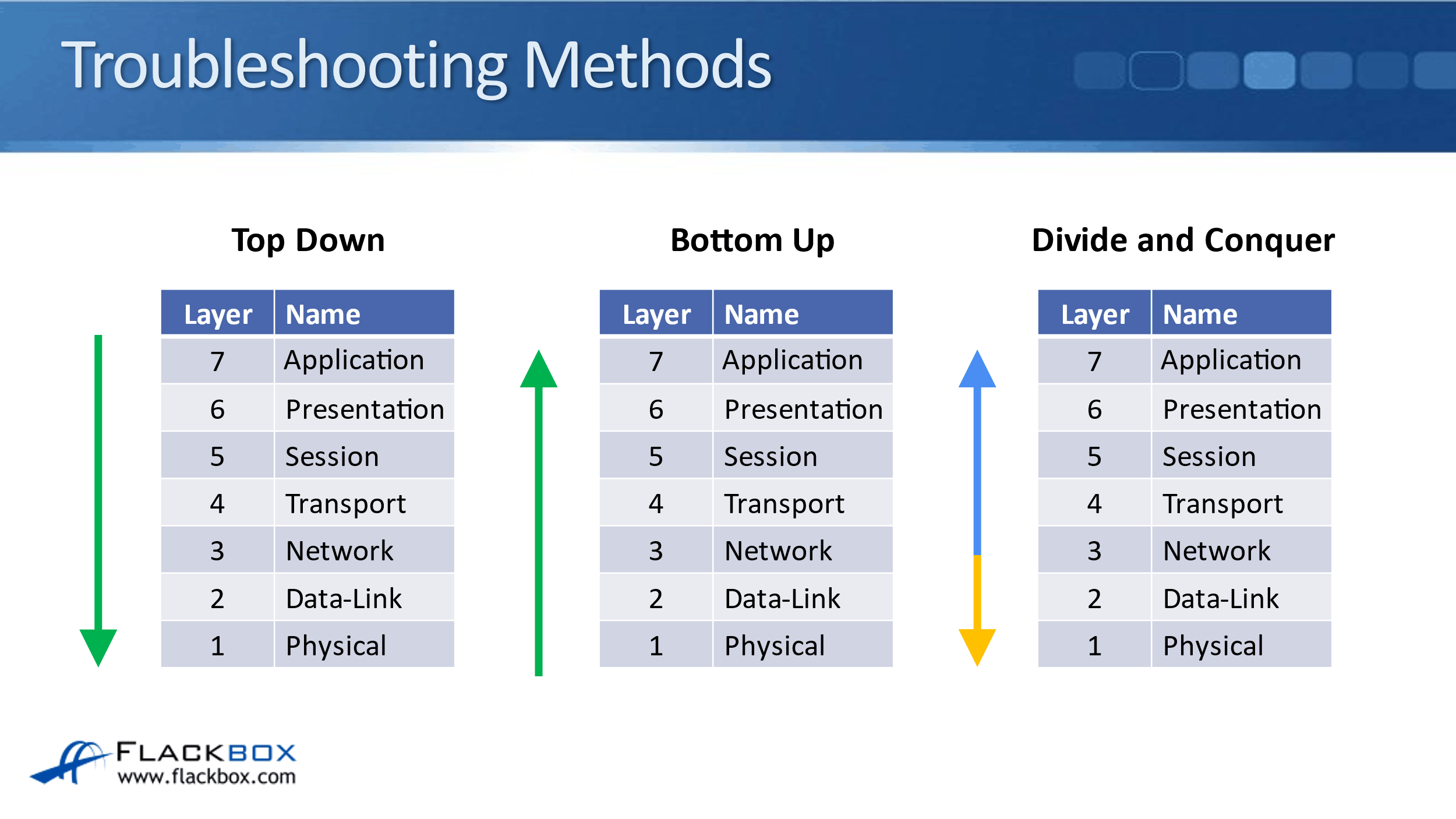
For example, if you see a problem like a connectivity problem, you've seen similar problems of this before, and it's always been caused by an issue at the Network Layer. You could go straight to the Network Layer and start troubleshooting there. Based on what you find, you could then move up or down through the OSI stack.
Remember, as we said before, having a good understanding of how IP networking works is going to really help you understand what's going on. When you understand what's going on, that makes it easier to troubleshoot problems.
Some methods we can use in our troubleshooting. The first one here, we can compare configurations. If you're in an organization, often you will use templates for configuring your routers and switches. In an existing organization, you've already got existing routers and switches there, so rather than doing a new configuration from scratch, you'll do it based on a template.
If you are doing this, and there's a problem, you think it's on a particular router, you can compare it with another router that should have a similar configuration and look for any differences. Maybe you've got a typo or maybe a missing command. By comparing it with a known good configuration, it can help you find the problem more quickly.

For connectivity issues, what we're usually going to do is trace the path. As a network engineer, a lot of your day-to-day job is going to be troubleshooting connectivity problems. The best way to troubleshoot connectivity problems and tracing the path, is to start off at the source and work your way towards the destination.
The last one mentioned here is swap out components. If you think that you have narrowed the problem down to a particular device, but you can't see a configuration error on there, a way you can confirm it is by swapping out with some known good hardware. The problem might be down to the physical level or maybe it's just something you're missing.
For example, a really simple one would be a cable. If you think it's possibly a cable issue because all the configuration appears okay, but there is some kind of Physical Layer problem, just swap out the cable and see if that fixes it.
Connectivity Troubleshooting Methods
We also use common commands to troubleshoot connectivity, one really super common command to use is ping. This checks connectivity between two devices. When you send out a ping, it uses ICMP, and it sends a packet from the source to the destination. The destination will then send a ping reply back again. So, ping verifies two-way connectivity.
If you've got connectivity from the source to the destination, but the return path from the destination back to the source isn't working, then the ping will not work either. This verifies two-way connectivity between our source and a destination. This is often one of the first commands that we'll use if we've got what looks to be a network connectivity issue.

The next command we'll probably use after a ping is a traceroute. If you've got multiple routers between the source and the destination, what you can do is you can troubleshoot it from source to destination.
Let's say, we've got routers R1, R2, R3, and R4. You could check R1 first, if it all looks good, you move on to R2, then onto R3, and so on. Well, a traceroute can sometimes speed this up a bit. A traceroute does a ping, hop by hop, from the source to the destination, and it will often indicate which router along the path has got the problem.
Finally, we can use telnet. Telnet is normally used for managing your network infrastructure devices, like your routers and switches. We can use that to get onto a command line on the device. Another thing that it can be used for is checking to see if a port is open on a destination.
Rather than using telnet to the default port of 23, we could, for example, telnet to port 80. That will verify if port 80 is open and receiving communications on the destination.
The Cisco Troubleshooting Methodology Configuration Example
This configuration example is taken from my free ‘Cisco CCNA Lab Guide’ which includes over 350 pages of lab exercises and full instructions to set up the lab for free on your laptop.
Click here to download your free Cisco CCNA Lab Guide.


Note that routers cannot be DNS servers in Packet Tracer (it does not support the ‘ip dns server’ command) so we are using a Packet Tracer server device as the DNS server.
1. The host with IP address 10.10.10.10 has been configured as a DNS server and should be able to resolve requests for ‘R1’, ‘R2’ and ‘R3’. Members of staff have complained that DNS is not working.
2. From R3, use Telnet to check if the DNS service appears operational on the DNS server at 10.10.10.10.
R3#telnet 10.10.10.10
Trying 10.10.10.10 ...
% Connection timed out; remote host not responding
3. When you have verified that DNS is not working, troubleshoot and fix the problem. You have fixed the problem when R3 can ping R1 by hostname. Note that there may be more than one issue causing the problem.
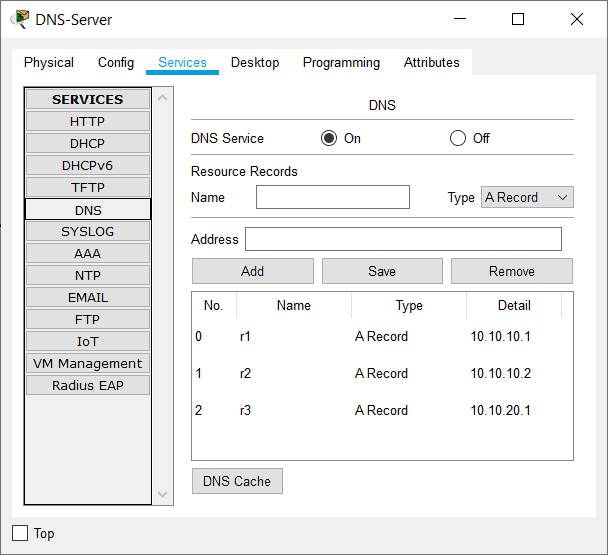
(You can click on the DNS server and then the ‘Services’ tab to check the server’s DNS configuration.)
There is more than one way to troubleshoot the issue. A suggested workflow is shown below.
The first two questions to ask when troubleshooting a problem are:
4. Was it working before? If so, has something changed which could cause the problem? This will usually direct you to the cause.
This question is not particularly useful for our example as the DNS server has just been brought online for the first time.
5. Is the problem affecting everybody or just one particular user? If it’s affecting just one user, the likelihood is that the problem is at their end.
In this case the problem is affecting all users, so the problem is likely on the server end or with the network.
The error message when we tried to Telnet was ‘remote host not responding’, so it looks like a connectivity issue.
Ping from R3 to the DNS server.
R3#ping 10.10.10.10
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.10.10.10, timeout is 2 seconds:
U.U.U
Success rate is 0 percent (0/5)
The ping fails at the network layer so there is little point in checking the DNS service at higher layers until we fix this problem.
Rather than checking connectivity hop by hop, we can possibly save a little time by using traceroute.
R3#traceroute 10.10.10.10
Type escape sequence to abort.
Tracing the route to 10.10.10.10
1 10.10.20.2 0 msec 0 msec 0 msec
2 10.10.20.2 !H * !H
3 * *
The traceroute got as far as R2, which lets us know that R3 has the correct route to get to the DNS server, and the problem is probably between R2 and the DNS server.
R2 has an interface connected to the 10.10.10.0/24 network, so we don’t need to check it has a route to the DNS server. We do need to check that the interface is up though.
R2#sh ip int brief
Interface IP-Address OK? Method Status Protocol
FastEthernet0/0 10.10.10.2 YES NVRAM administratively down down
FastEthernet0/1 unassigned YES NVRAM administratively down down
FastEthernet1/0 10.10.20.2 YES NVRAM up up
FastEthernet1/1 unassigned YES NVRAM administratively down down
Vlan1 unassigned YES NVRAM administratively down down
There’s the problem – FastEthernet0/0 facing the DNS server is administratively shutdown. Let’s fix it.
R2(config)#interface f0/0
R2(config-if)#no shutdown
Next we’ll try pinging from R3 to the DNS server again to verify we fixed connectivity.
R3#ping 10.10.10.10
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.10.10.10, timeout is 2 seconds:
..!!!
Success rate is 60 percent (3/5), round-trip min/avg/max = 0/0/0 ms
That looks better – don’t worry if the first one or two pings are dropped, there may be a delay while the ARP cache is updated. Next we’ll verify DNS is working.
R3#ping R1
Translating "R1"...domain server (10.10.10.1)
% Unrecognized host or address or protocol not running.
The error message tells us the problem if we take the time to really read it – R3 is using 10.10.10.1 as its DNS server, but the correct address is 10.10.10.10.
We fix that next. Don’t forget to remove the incorrect entry first.
R3(config)#no ip name-server 10.10.10.1
R3(config)#ip name-server 10.10.10.10
Then test again.
R3#ping R1
Translating "R1"...domain server (10.10.10.1)
% Unrecognized host or address or protocol not running.
The error message is still there. We know we have connectivity and the DNS server configured correctly on R3, so the problem looks like it’s on the DNS server.
Check the DNS service is running on the 10.10.10.10 host and that address records are configured for ‘R1’, ‘R2’ and ‘R3’.

The address records are there but the DNS service is turned off. Turn it back on.
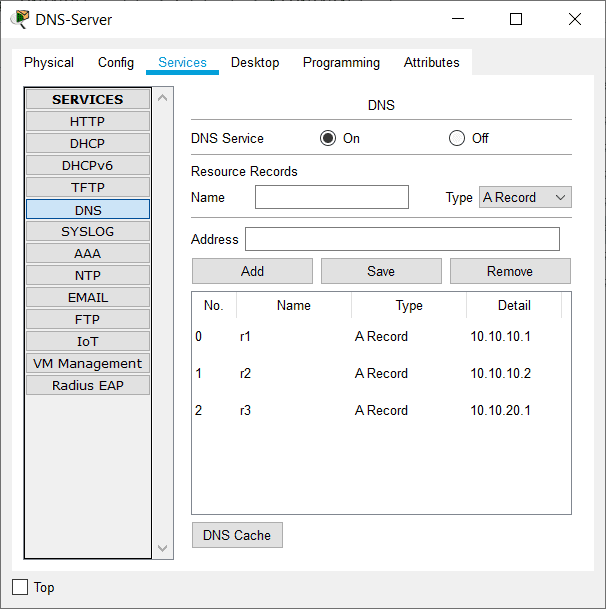
Time to test it from R3 again.
R3#ping R1
Translating "R1"...domain server (10.10.10.10)
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.10.10.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 0/0/4 ms
That’s the problem solved.
To summarise the issues: port FastEthernet0/0 was shut down on R2, R3 was using the wrong IP address for the DNS server, and the DNS service was not running on the server.
Problems in the real world are usually caused by just one error rather than three as in this case. This can still occur though, particularly when a new service is being deployed.
Additional Resources
Cisco Troubleshooting Guide: https://www.cisco.com/en/US/docs/internetworking/troubleshooting/guide/tr1901.html
Troubleshooting Methods for Cisco IP Networks: https://www.ciscopress.com/articles/article.asp?p=2273070&seqNum=2
Preventive Maintenance and Troubleshooting: https://www.ciscopress.com/articles/article.asp?p=2999386&seqNum=5
Libby Teofilo

Text by Libby Teofilo, Technical Writer at www.flackbox.com
Libby’s passion for technology drives her to constantly learn and share her insights. When she’s not immersed in the tech world, she’s either lost in a good book with a cup of coffee or out exploring on her next adventure. Always curious, always inspired.