
In this NetApp training tutorial, we will discuss the NetApp SnapMirror Engine. Scroll down for the video and also text tutorial.
NetApp SnapMirror Engine Video Tutorial

Abhishek Khulbe

I just cleared my NCDA in 1st attempt and all thanks to Neil’s amazing content on Flackbox, his training material, and guidance. His hands-on approach to coaching, detailed explanation with diagrams has won my respect. I am hopeful he will deliver even more in NetApp storage world.
The NetApp SnapMirror Engine
The SnapMirror engine is used to replicate data from a source volume to a destination volume. It's used for these features:
- Load Sharing Mirrors
- Data Protection Mirrors
- SnapVault
I'll be talking about each of those different features in this post.
With Clustered ONTAP, the volume is the unit of replication in the SnapMirror engine. In 7-Mode you could replicate at either the Qtree or the volume level, but Cluster Mode only does it at the volume level.
When you run a replication using the SnapMirror engine, the source volume will be a read-write copy and the destination will be a read-only copy. This is to ensure that you have a single, consistent copy of the data. If you were able to write to both locations, the two wouldn't be the same.
The initial replication from the source to destination volume is a complete baseline transfer. It copies all of the data from the source to the destination volume. Once that has completed, all of the following replications are incremental only.
The system uses source volume Snapshot copies to update the destination volumes. Updates can be performed manually (on demand) or, more typically, they can run automatically based on a configured schedule.
The mirror copies are updated asynchronously. The minimum time between replications is one minute. You can get synchronous replication in Clustered ONTAP by using MetroCluster, but SnapMirror is asynchronous.
Synchronous vs Asynchronous Replication
The difference between synchronous and asynchronous replication is shown in the diagram below.
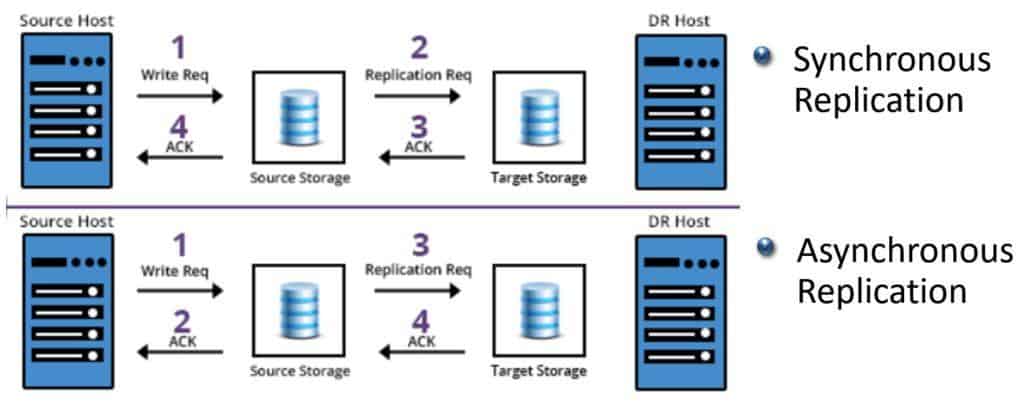
We have synchronous replication at the top. A client sends in a write request and it gets written to the source cluster. This change then gets replicated over to the destination cluster. It's only when the destination cluster has acknowledged the change back to the source that the final acknowledgement is sent back to the client.
With asynchronous replication on the other hand, the client sends in the write request and the source storage system immediately sends an acknowledgement back. The source will then replicate the data to the final destination storage system when it is next scheduled to do so, and another acknowledgement will come back from there.
Recovery Point Objective (RPO)
Your Recovery Point Objective (RPO) is the maximum amount of data you could lose if you had to fail over from your main site to a Disaster Recovery site.
If you're using synchronous replication, your recovery point objective (RPO) is going to basically be zero. If you have to failover from your primary site to your Disaster Recovery site you're not going to lose any data.
If you're using asynchronous replication and you have a failure of the primary site, the amount of data you lose when you failover to the secondary site will depend on the amount of data that had been written to the primary since the last replication.
Let’s say your system was scheduled to replicate once every ten minutes. The worst case scenario would be that you have a failure just before you were about to do the next replication. You could lose up to ten minutes' worth of writes that happened at the primary site since the last scheduled replication, so your RPO would be 10 minutes.
You’re probably thinking "well then it that case I’ll always use synchronous replication", but there’s a trade-off. This is because the acknowledgement with synchronous replication isn’t sent back to the client until it's been written to both sites.
Unless there’s minimal delay between the two sites, this can break applications on the client if its acknowledgement doesn't get back to it in time. For synchronous replication, you will typically need a really fast network between the two sites. That can be prohibitively expensive, in which case asynchronous replication would be a better solution for you.
How Replication Works
Let’s look at how replication works with SnapMirror. To begin with, the initial baseline transfer is completed. Then, a snapshot copy of all data on the source volume is created. This is then transferred to the destination volume. After that, you can run manual and/or scheduled updates. Typically you'll have scheduled updates. You can just run manual ones if you prefer, or you can do a combination of both.
When you do an update, a new snapshot copy of the source is taken. The current SnapMirror snapshot copy is compared with the previous SnapMirror snapshot copy, and then only changes are synchronized from the source to the destination incrementally.
If any files have changed, it doesn’t replicate the entire file. Replication is done at the block level, so it's only the changed blocks that get sent across. It's very efficient after the initial baseline transfer. Whenever you do a new replication, only incremental changes at the block level get replicated across.
Storage Efficiency and Volume Moves
The SnapMirror engine is compatible with storage efficiency and volume moves. Deduplication and compression savings are replicated from the source to the destination volume. The data is not inflated or decompressed for the transfer.
If you've got storage efficiency turned on at the source site, the space savings are going to be automatically replicated to the destination site as well. This also helps save on your network bandwidth and the amount of time it takes to do the transfer.
SnapMirror source or destination volumes can be moved to another aggregate in the cluster without breaking the SnapMirror relationships. If you want to move a volume because your aggregate is getting too full or you want to move it to higher or lower performance disks, you can. Any SnapMirror relationships will be retained even after you perform the move.
NetApp Load Sharing Mirrors
Let's now talk about the three different features that use the SnapMirror engine. They are Load Sharing (LS) mirrors, Data Protection (DP) mirrors, and SnapVault. I'll cover Load Sharing mirrors first. This will be a quick overview because they’re going to be covered in more detail in a later post.
Load Sharing mirrors are mirror copies of FlexVol volumes which provide redundancy and load balancing. They provide load balancing for read traffic only, not for write. Write requests always go to the one source volume so that you have that single, consistent copy of the data.
Load Sharing mirror destination volumes are always in the same cluster as the source volume. This is unlike DP mirrors and SnapVault. Data Protection Mirrors and SnapVault can perform their function either within the same cluster or to a different cluster, whereas Load Sharing mirrors only work within the same cluster.
Load Sharing mirrors are automatically mounted into the namespace with the same path as the source volume, and they provide redundancy for read access with no administrator intervention required.
If the source volume goes down, clients can still get read-only access the data without requiring any action from the administrator. (Getting write access back if the original source volume cannot be recovered does require the administrator to manually promote one of the mirror copies to be the new source).
NetApp Data Protection Mirrors
Next we have Data Protection mirrors (DP mirrors). With DP mirrors you can replicate a source volume to a destination volume in the same or in a different cluster. Most often it'll be a different cluster. They can be used for the following reasons:
- Replicate data between volumes in different clusters for Disaster Recovery. In this scenario you have a main primary site and a Disaster Recovery site. The way that you replicate data from the main site to the DR site is using SnapMirror DP mirrors. With DP mirrors, intervention is required to failover to the DR site. This differs from our Load Sharing mirrors. This will require either manual intervention, or you can configure software to do this.
- Provide load balancing for read access across different sites. We always have only one writable copy of the data to keep it consistent, but if we have a read only data set which is accessed by clients in multiple locations, we can keep separate mirrored copies of the data close to the clients to provide load balancing and better performance.
- Data migration between clusters or SVMs. This is for when you want to move some data from cluster A to cluster B or between SVMs in the same cluster. If you want to move data within the same SVM and you're moving the entire volume, you can use a volume copy. Volume copy only works within the same SVM, so if you want to move data between different SVMs you would use SnapMirror DP mirrors.
- Replicate data to a single centralised tape backup location. If you have clusters in multiple locations this removes the need to backup each one locally. (SnapVault can also do this, but uses disk to disk rather than disk to tape backups).
When we talk about ‘SnapMirror’ in general, we're talking about DP mirrors. Load Sharing mirrors, Data Protection mirrors and SnapVault all use the SnapMirror engine but if we refer to ‘SnapMirror’, we’re usually talking about DP mirrors.
As mentioned earlier (and unlike Load Sharing mirrors), DP mirror copies are not automatically mounted into the namespace and implicitly accessed by clients. DP mirror copies can be mounted through a junction into the namespace by the administrator if they need to be accessed at the destination.
Data Protection mirrors and SnapVault are both licensed features but Load Sharing mirrors are not. You don't need a license to implement Load Sharing mirrors.
The main functionality of DP mirrors is as a Disaster Recovery solution. If your primary site is lost, you can make the destination volumes writable in your DR site. This requires a failover which breaks the mirror relationship.
A FlexClone copy can also be taken on the destination without doing a failover. This will give us a separate writable copy without disrupting SnapMirror operations.
Our DP mirrors maintain two snapshots on the destination volume. When a replication occurs, the oldest snapshot is deleted. When it’s time for the next replication, the new snapshot is compared to the previous one to determine the incremental changes to replicate across.
DP mirrors keep the source and destination volumes in the same state with some lag as determined by your replication schedule. The source and destination are kept in sync with each other. If data is corrupted in the source volume it will therefore be corrupted in the destination volume as well.
DP mirrors provide Disaster Recovery, but they don't provide long term backups. The feature won’t help if you developed a problem in the main site, it then replicated across to your DR site, and you don't have backups going further back in time. It's a Disaster Recovery solution, not a backup solution.
NetApp SnapVault
That leads us on to the other feature which uses the SnapMirror engine, which is SnapVault. SnapVault is ONTAP's long term disk-to-disk backup solution. It has the same functionality as traditional tape backups but is much faster, more convenient, and requires less storage space.
Data is replicated from the source volume to a destination volume on a centralized backup cluster. Like our Data Protection mirrors, SnapVault is also a licensed feature. SnapMirror DP mirrors and SnapVault have separate licenses.
Unlike DP mirrors, SnapVault can retain multiple snapshots as backups over a long time period. Data can be restored to the original source volume or to a different volume.
The destination volume cannot be made writable so it's a backup, not a DR solution. Data Protection mirrors are our Disaster Recovery solution, SnapVault is our long term disk-to-disk backup solution. Separate FlexClone copies can, however, be made of the snapshot backups at the destination site to get a separate writable copy of the data there.
LS Mirror, DP Mirror and SnapVault Summary
Let's summarize the similarities and differences between the features that use the SnapMirror engine and where we would use each one.
Load Sharing mirrors, Data Protection mirrors, and SnapVault all use the SnapMirror engine to replicate data between volumes. They all do their replication in the same way.
Load Sharing mirrors are used for redundancy and load balancing within the same cluster for read-only volumes. No license is required.
The main function of DP mirrors is as a Disaster Recovery solution between clusters. They can also be used to move data between SVMs or clusters.
SnapVault is our long term disk-to-disk backup solution.
DP Mirror and SnapVault Compatibility
With regard to hardware compatibility, the source and destination nodes can be different models of controller. Also, you can use inexpensive SATA drives on the destination volume while your main site can still be running SSD or SAS disks.
When you're replicating across to a SnapMirror Disaster Recovery location or to a SnapVault backup location, you can use cheaper drives in the remote location to achieve cost savings.
SnapMirror became available in Clustered ONTAP version 8.1, and SnapVault became available in version 8.2. At that point, the version of ONTAP that was running on the destination volume had to be the same or a later version than the one running on the source volume.
In ONTAP 8.3, a version flexible SnapMirror became available which breaks that limitation and allows different versions to be run on both the source and destination. This will become more useful as further versions are released.
ONTAP 7-Mode volumes cannot be used in Clustered ONTAP systems, and vice versa. However, if you are migrating from 7-Mode to Cluster Mode, you can use the 7-Mode Transition Tool (7MTT) which uses the SnapMirror engine to migrate your volumes across.
That's the one exception where you can actually use SnapMirror to replicate from 7-Mode to Cluster Mode. You can't have normal SnapMirror relationships between 7-Mode and Cluster Mode systems.
NetApp SnapMirror Engine Configuration Example
This configuration example is an excerpt from my ‘NetApp ONTAP 9 Complete’ course. Full configuration examples using both the CLI and System Manager GUI are available in the course.
Want to practice this configuration for free on your laptop? Download your free step-by-step guide ‘How to Build a NetApp ONTAP Lab for Free’

SnapMirror Asynchronous DP Mirrors
- Create a SnapMirror Data Protection mirror relationship from vol1 in Cluster1 to a new volume named vol1_m in Cluster2. Use the ‘MirrorAllSnapshots’ policy. Replication should take place once every minute.
Use the ‘snapmirror create’ command if performing the configuration using the CLI.
SnapMirror configuration is performed on the destination cluster. First create the schedule to run every minute.
cluster2::> job schedule cron create -name 1min -minute 00,01,02,03,04,05,06,07,08,09,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59
Create the destination volume as type DP. The size should be the same as the source volume.
cluster2::> volume create -vserver NAS_M -volume vol1_m -aggregate aggr1_C2N1 -size 100mb -type dp
[Job 29] Job succeeded: Successful
Then create the SnapMirror relationship.
cluster2::> snapmirror create -destination-path NAS_M:vol1_m -source-path NAS:vol1 -type XDP -policy MirrorAllSnapshots -schedule 1min
Operation succeeded: snapmirror create for the relationship with destination "NAS_M:vol1_m".
Then initialize it to perform the first replication.
cluster2::> snapmirror initialize -destination-path NAS_M:vol1_m
Operation is queued: snapmirror initialize of destination "NAS_M:vol1_m".
2. Wait for the replication to complete, then verify that the SnapMirror relationship has been configured successfully, it is healthy and data has been replicated to vol1_m.
cluster2::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
NAS:vol1 XDP NAS_M:vol1_m Snapmirrored
Idle - true -
cluster2::> volume show
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
NAS_M svm_root aggr1_C2N1 online RW 20MB 18.61MB 2%
NAS_M vol1_m aggr1_C2N1 online DP 100MB 84.51MB 15%
cluster2-01
vol0 aggr0_cluster2_01
online RW 807.3MB 453.2MB 40%
3 entries were displayed.
3. View the detailed information about the SnapMirror relationship on Cluster2.
cluster2::> snapmirror show -source-path NAS:vol1 -destination-path NAS_M:vol1_m -instance
Source Path: NAS:vol1
Destination Path: NAS_M:vol1_m
Relationship Type: XDP
Relationship Group Type: none
SnapMirror Schedule: 1min
SnapMirror Policy Type: async-mirror
SnapMirror Policy: MirrorAllSnapshots
Tries Limit: -
Throttle (KB/sec): unlimited
Mirror State: Snapmirrored
Relationship Status: Idle
File Restore File Count: -
File Restore File List: -
Transfer Snapshot: -
Snapshot Progress: -
< Output truncated >
4. Verify you can see the SnapMirror snapshots in vol1_m on Cluster2 and vol1 on Cluster1.
cluster2::> volume snapshot show -vserver NAS_M -volume vol1_m
---Blocks---
Vserver Volume Snapshot Size Total% Used%
-------- -------- ------------------------------------- -------- ------ -----
NAS_M vol1_m
snapmirror.6ed00d17-9be6-11e9-9521-000c29adabc3_2154150308.2019-07-02_144400
180KB 0% 1%
snapmirror.6ed00d17-9be6-11e9-9521-000c29adabc3_2154150308.2019-07-02_144500
132KB 0% 1%
2 entries were displayed.
cluster1::> volume snapshot show -vserver NAS -volume vol1
---Blocks---
Vserver Volume Snapshot Size Total% Used%
-------- -------- ------------------------------------- -------- ------ -----
NAS vol1
snapmirror.6ed00d17-9be6-11e9-9521-000c29adabc3_2154150308.2019-07-02_144500
132KB 0% 1%
5. View SnapMirror destinations from Cluster1.
cluster1::> snapmirror list-destinations
Progress
Source Destination Transfer Last Relationship
Path Type Path Status Progress Updated Id
----------- ----- ------------ ------- --------- ------------ ---------------
NAS:vol1 XDP NAS_M:vol1_m Idle - - 37ea8a85-9d12-11e9-9521-000c29adabc3
6. Suspend the C1N1 and C1N2 virtual machines to simulate the Cluster1 site failing.
7. Perform a Disaster Recovery failover by enabling Windows clients to access vol1_m in the Cluster2 DR site.
On Cluster2, verify the SnapMirror state is idle. If not, abort the transfer.
cluster2::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
NAS:vol1 XDP NAS_M:vol1_m Snapmirrored
Transferring 2.30KB true 07/01 07:55:49
cluster2::> snapmirror abort -destination-path NAS_M:vol1_m
Operation is queued: snapmirror abort for the relationship with destination "NAS_M:vol1_m".
cluster2::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
NAS:vol1 XDP NAS_M:vol1_m Snapmirrored
Idle - false -
Quiesce the SnapMirror relationship to pause transfers.
cluster2::> snapmirror quiesce -destination-path NAS_M:vol1_m
Operation succeeded: snapmirror quiesce for destination "NAS_M:vol1_m".
Break the SnapMirror relationship to make vol1_m writeable. (Abort the operation and run the break command again if you receive an error message.)
cluster2::> snapmirror break -destination-path NAS_M:vol1_m
Error: command failed: Another transfer is in progress.
cluster2::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
NAS:vol1 XDP NAS_M:vol1_m Snapmirrored
Quiescing 2.30KB false 07/01 07:57:03
cluster2::> snapmirror abort -destination-path NAS_M:vol1_m
Operation is queued: snapmirror abort for the relationship with destination "NAS_M:vol1_m".
cluster2::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
NAS:vol1 XDP NAS_M:vol1_m Snapmirrored
Quiesced - false -
cluster2::> snapmirror break -destination-path NAS_M:vol1_m
Operation succeeded: snapmirror break for destination "NAS_M:vol1_m".
Verify the vol1_m volume type is now RW (not DP).
cluster2::> volume show
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
NAS_M svm_root aggr1_C2N1 online RW 20MB 18.63MB 1%
NAS_M vol1_m aggr1_C2N1 online RW 100MB 84.98MB 15%
cluster2-01
vol0 aggr0_cluster2_01
online RW 807.3MB 446.0MB 41%
3 entries were displayed.
Mount the volume. I’m using the path /vol1_m here but you could use the same /vol1 path as the original source volume.
cluster2::> volume mount -vserver NAS_M -volume vol1_m -junction-path /vol1_m
Warning: The export-policy "default" has no rules in it. The volume will therefore be inaccessible over NFS and CIFS protocol.
Do you want to continue? {y|n}: y
Share the volume. I’m using the share name /vol1_m here but again you could use the same /vol1 share name as the original source volume.
cluster2::> cifs share create -vserver NAS_M -share-name vol1_m -path /vol1_m
8. Verify the state of the SnapMirror relationship.
The SnapMirror state should be ‘Broken-off’.
cluster2::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
NAS:vol1 XDP NAS_M:vol1_m Broken-off
Idle - false -
9. Power on the WinA virtual machine and verify its date and time.
10. Set the date and time on Cluster2 to match the WinA client. The example below sets the date and time to 20th March 2019, 09:23am PST.
cluster2::> cluster date modify -dateandtime 201903200923
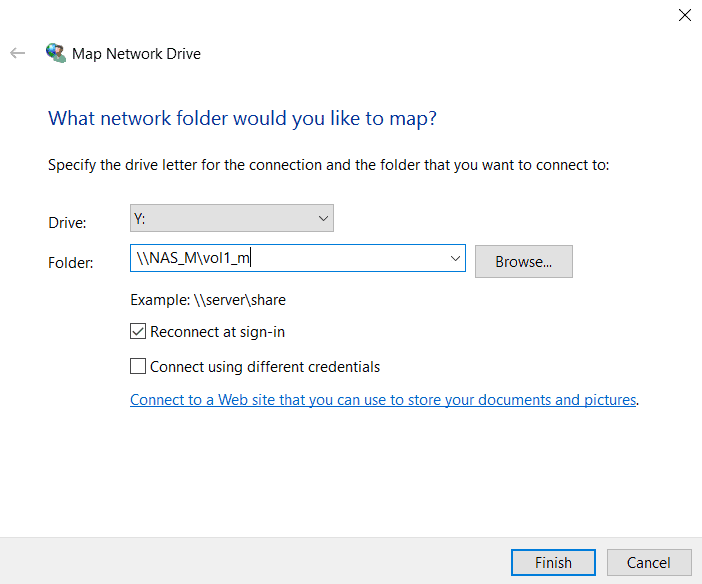
11. On the WinA host, verify you can access the volume in the Cluster2 DR site. It should contain the ‘Windows Defender’ folder.
Open Windows File Explorer. Right-click on ‘Network’ and select ‘Map network drive…’
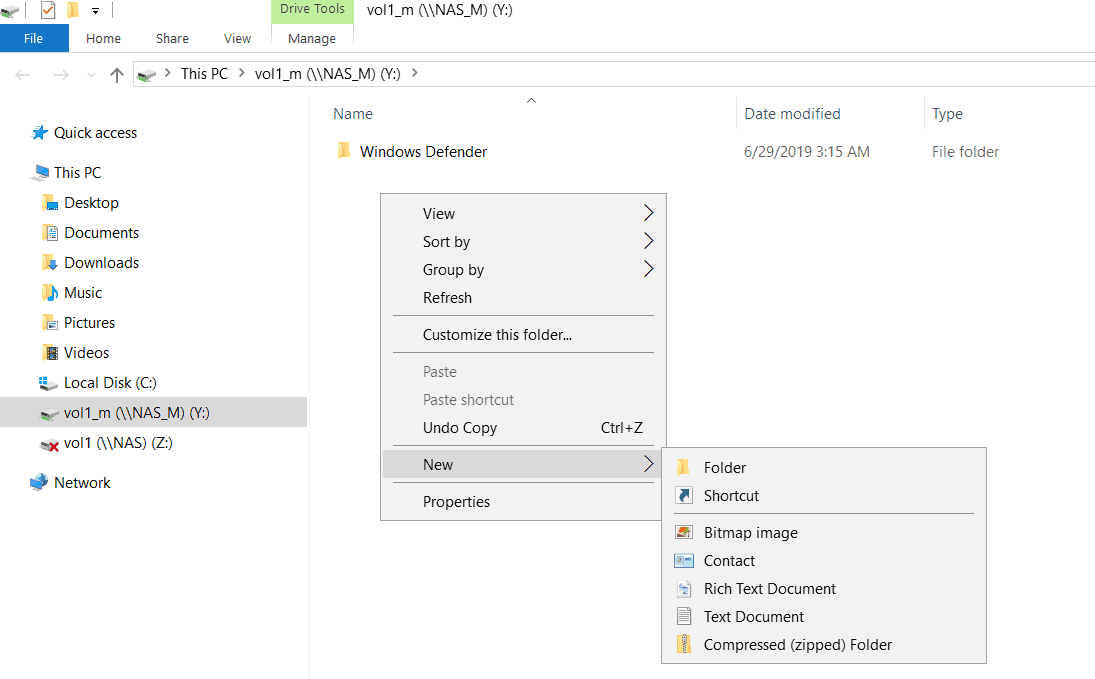
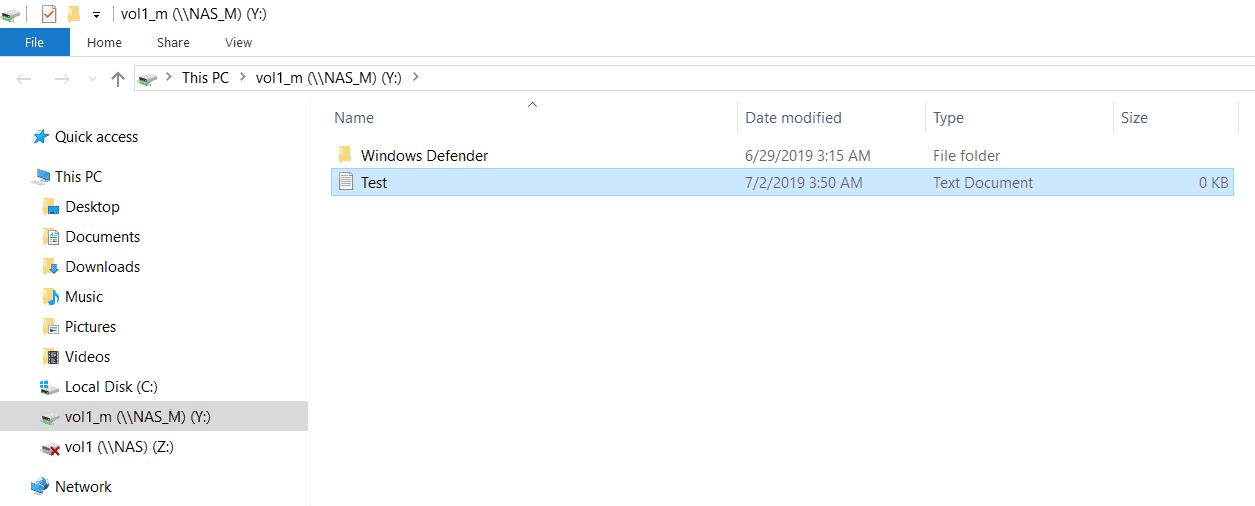
12. Verify the volume is writeable by creating a new text file in it named Test.
13. Suspend the WinA virtual machine. (If your laptop has more than 18GB RAM you can leave the WinA virtual machine running.)
14. Power on the C1N1 and C1N2 virtual machines. Set the Cluster1 date and time to match Cluster2.
cluster2::> cluster date show
Node Date Time zone
--------- ------------------------- -------------------------
cluster2-01
7/1/2019 01:59:00 -07:00 US/Pacific
1 entries were displayed.
The example below sets the date and time to 1st July 2019, 01:59am PST.
cluster1::> cluster date modify -dateandtime 201907010159
15. What do you expect the volume type of vol1 in Cluster1 and vol1_m in Cluster2 to be (RW or DP)? Verify this.
Both vol1 and vol1_m are RW because you broke the SnapMirror relationship. In order to maintain one consistent copy of the data, it is important that no data is written to vol1 in Cluster1 until a fail back is completed.
cluster1::> volume show
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
NAS svm_root aggr2_C1N1 online RW 20MB 17.77MB 6%
NAS svm_root_m1 aggr1_C1N1 online LS 20MB 17.82MB 6%
NAS svm_root_m2 aggr1_C1N2 online LS 20MB 17.82MB 6%
NAS vol1 aggr1_C1N1 online RW 100MB 79.78MB 16%
cluster1-01
vol0 aggr0_cluster1_01
online RW 1.66GB 1.04GB 34%
cluster1-02
vol0 aggr0_cluster1_02
online RW 807.3MB 231.6MB 69%
6 entries were displayed.
cluster2::> volume show
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
NAS_M svm_root aggr1_C2N1 online RW 20MB 18.62MB 1%
NAS_M vol1_m aggr1_C2N1 online RW 100MB 84.82MB 15%
cluster2-01
vol0 aggr0_cluster2_01
online RW 807.3MB 439.3MB 42%
3 entries were displayed.
16. The Cluster1 site is now back online, fail back to Cluster1.
Any changes that were made to the vol1 data while Cluster1 was offline must be kept, and the SnapMirror relationship from Cluster1 to Cluster2 must be reinstated.
Create a SnapMirror relationship with vol1_m in Cluster2 as the source and vol1 in Cluster1 as the destination.
cluster1::> snapmirror create -destination-path NAS:vol1 -source-path NAS_M:vol1_m -type XDP -policy MirrorAllSnapshots
Operation succeeded: snapmirror create for the relationship with destination "NAS:vol1".
Replicate the data that was written to vol1_m while vol1 was offline, back from vol1_m to vol1.
cluster1::> snapmirror resync -destination-path NAS:vol1
Warning: All data newer than Snapshot copy snapmirror.6ed00d17-9be6-11e9-9521-000c29adabc3_2154150302.2019-07-01_075400 on volume NAS:vol1 will be deleted.
Do you want to continue? {y|n}: y
Operation is queued: initiate snapmirror resync to destination "NAS:vol1".
Wait for the replication to complete.
cluster1::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
NAS_M:vol1_m
XDP NAS:vol1 Snapmirrored
Transferring 0B true 07/01 08:07:22
cluster1://NAS/svm_root
LS cluster1://NAS/svm_root_m2
Snapmirrored
Idle - true -
cluster1://NAS/svm_root_m1
Snapmirrored
Idle - true -
3 entries were displayed.
cluster1::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
NAS_M:vol1_m
XDP NAS:vol1 Snapmirrored
Idle - true -
cluster1://NAS/svm_root
LS cluster1://NAS/svm_root_m2
Snapmirrored
Idle - true -
cluster1://NAS/svm_root_m1
Snapmirrored
Idle - true -
3 entries were displayed.
Once both volumes are back in sync, you can remove the SnapMirror relationship from vol1_m to vol1.
cluster1::> snapmirror quiesce -destination-path NAS:vol1
Operation succeeded: snapmirror quiesce for destination "NAS:vol1".
cluster1::> snapmirror break -destination-path NAS:vol1
Operation succeeded: snapmirror break for destination "NAS:vol1".
cluster1::> snapmirror delete -destination-path NAS:vol1
Operation succeeded: snapmirror delete for the relationship with destination "NAS:vol1".
cluster1::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
cluster1://NAS/svm_root
LS cluster1://NAS/svm_root_m2
Snapmirrored
Idle - true -
cluster1://NAS/svm_root_m1
Snapmirrored
Idle - true -
2 entries were displayed.
Then resync back from vol1 to vol1_m to reinstate the original SnapMirror relationship.
cluster2::> snapmirror resync -destination-path NAS_M:vol1_m
Warning: All data newer than Snapshot copy snapmirror.b0d1ec4c-99c1-11e9-afbf-000c296f941d_2156825624.2019-07-01_080722 on volume NAS_M:vol1_m will be deleted.
Do you want to continue? {y|n}: y
Operation is queued: initiate snapmirror resync to destination "NAS_M:vol1_m".
17. Verify the SnapMirror and volume settings are back to the same as before Cluster1 went offline.
cluster1::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
cluster1://NAS/svm_root
LS cluster1://NAS/svm_root_m2
Snapmirrored
Idle - true -
cluster1://NAS/svm_root_m1
Snapmirrored
Idle - true -
2 entries were displayed.
cluster1::> snapmirror list-destinations
Progress
Source Destination Transfer Last Relationship
Path Type Path Status Progress Updated Id
----------- ----- ------------ ------- --------- ------------ ---------------
NAS:vol1 XDP NAS_M:vol1_m Idle - - 37ea8a85-9d12-11e9-9521-000c29adabc3
cluster1::> volume show
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
NAS svm_root aggr2_C1N1 online RW 20MB 17.76MB 6%
NAS svm_root_m1 aggr1_C1N1 online LS 20MB 17.82MB 6%
NAS svm_root_m2 aggr1_C1N2 online LS 20MB 17.82MB 6%
NAS vol1 aggr1_C1N1 online RW 100MB 79.35MB 16%
cluster1-01
vol0 aggr0_cluster1_01
online RW 1.66GB 1.05GB 33%
cluster1-02
vol0 aggr0_cluster1_02
online RW 807.3MB 225.7MB 70%
cluster2::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
NAS:vol1 XDP NAS_M:vol1_m Snapmirrored
Idle - true -
cluster2::> volume show
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
NAS_M svm_root aggr1_C2N1 online RW 20MB 18.59MB 2%
NAS_M vol1_m aggr1_C2N1 online DP 100MB 84.36MB 15%
cluster2-01
vol0 aggr0_cluster2_01
online RW 807.3MB 447.8MB 41%
3 entries were displayed.
18. Suspend the C2N1 virtual machine and power on the WinA virtual machine. (You can leave C2N1 running if you have at least 18GB RAM on your laptop.)
19. On Cluster1, set the date and time to match the WinA client. The example below sets the date and time to 20th March 2019, 09:23am PST.
cluster1::> cluster date modify -dateandtime 201903200923
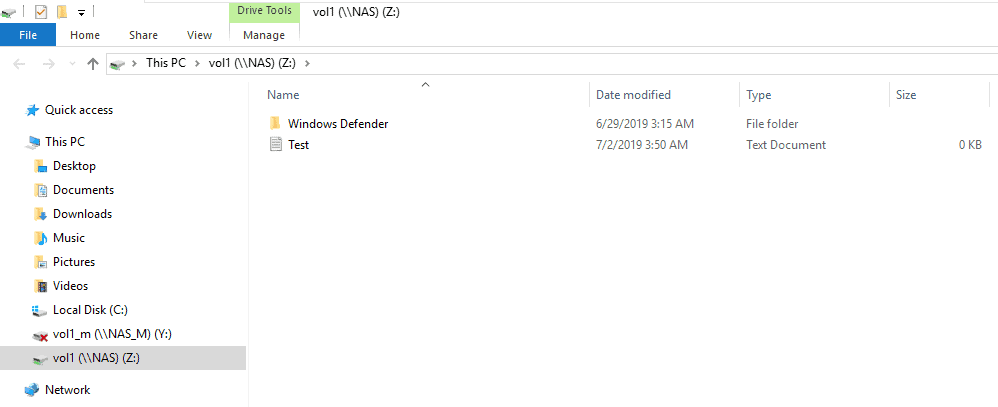
20. On the WinA host, verify the file you created in vol1 while it was failed over to the Cluster2 DR site is there.
You may need to hit F5 to refresh the view to show the drive mapped to \\NAS\vol1 as connected.
Clean-up
21. Suspend the WinA virtual machine and power on C2N1. (You can leave WinA running if you have at least 18GB RAM on your laptop.) Remove the SnapMirror relationship on Cluster2 and delete vol1_m.
cluster2::> snapmirror delete -destination-path NAS_M:vol1_m
Operation succeeded: snapmirror delete for the relationship with destination "NAS_M:vol1_m".
cluster2::> snapmirror release -source-path NAS_M:vol1_m -destination-path NAS:vol1
Warning: Snapshot copies on source volume "NAS_M:vol1_m" generated by SnapMirror for the purpose of mirroring to destination volume "NAS:vol1" will be deleted. Once these Snapshot copies are deleted, it will not be possible to re-establish a mirroring relationship between these two volumes unless there are other common Snapshot copies between the source and the destination volumes.
Do you want to continue? {y|n}: y
[Job 38] Job succeeded: SnapMirror Release Succeeded
cluster2::> volume modify -vserver NAS_M -volume vol1_m -state offline
Warning: Volume "vol1_m" on Vserver "NAS_M" must be unmounted before being taken offline or restricted. Clients will not be able to access the affected volume and related junction paths after that. Do you still want to unmount the volume and continue? {y|n}: y
Volume modify successful on volume vol1_m of Vserver NAS_M.
cluster2::> volume delete -vserver NAS_M -volume vol1_m
Warning: Are you sure you want to delete volume "vol1_m" in Vserver "NAS_M" ? {y|n}: y
[Job 39] Job succeeded: Successful
22. On Cluster1, release the SnapMirror relationship and delete all snapshots in vol1.
cluster1::> snapmirror release -source-path NAS:vol1 -destination-path NAS_M:vol1_m -force
[Job 121] Job is queued: snapmirror release for destination "NAS_M:vol1_m".
Warning: Snapshot copies on source volume "NAS:vol1" generated by SnapMirror for the purpose of mirroring to destination volume "NAS_M:vol1_m" will be deleted. Once these Snapshot copies are deleted, it will not be possible to re-establish a mirroring relationship between these two volumes unless there are other common Snapshot copies between the source and the destination volumes.
[Job 121] Job succeeded: SnapMirror Release Succeeded
cluster1::> volume snapshot show -vserver NAS -volume vol1
---Blocks---
Vserver Volume Snapshot Size Total% Used%
-------- -------- ------------------------------------- -------- ------ -----
NAS vol1
snapmirror.b0d1ec4c-99c1-11e9-afbf-000c296f941d_2156825624.2019-07-02_105901
936KB 1% 6%
cluster1::> volume snapshot delete -vserver NAS -volume vol1 -snapshot snapmirror.b0d1ec4c-99c1-11e9-afbf-000c296f941d_2156825624.2019-07-02_105901
Warning: Deleting a Snapshot copy permanently removes any data that is stored only in that Snapshot copy. Are you sure you want to delete Snapshot copy "snapmirror.b0d1ec4c-99c1-11e9-afbf-000c296f941d_2156825624.2019-07-02_105901" for volume "vol1" in Vserver "NAS" ?
{y|n}: y
SnapMirror Synchronous DP Mirrors
- Create a SnapMirror Synchronous Data Protection mirror relationship from vol1 in Cluster1 to a new volume named vol1_m in Cluster2. All writes should fail if the replication to Cluster2 fails.
Use the ‘snapmirror protect’ command if performing the configuration using the CLI.
Note that SnapMirror Synchronous is not supported in the lab environment. You will be able to configure it but Initialization will fail.
Use the ‘Sync’ policy so all writes fail if synchronization fails.
cluster2::> snapmirror protect -path-list NAS:vol1 -destination-vserver NAS_M -policy Sync -destination-volume-suffix _m
[Job 42] Job is queued: snapmirror protect for list of volumes beginning with "NAS:vol1".
2. Verify that the SnapMirror relationship has been configured successfully, but initialization has failed because SnapMirror Synchronous is not supported in the lab environment.
cluster2::> snapmirror show
Progress
Source Destination Mirror Relationship Total Last
Path Type Path State Status Progress Healthy Updated
----------- ---- ------------ ------- -------------- --------- ------- --------
NAS:vol1 XDP NAS_M:vol1_m
Uninitialized
Idle - false -
cluster2::> volume show
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
NAS_M svm_root aggr1_C2N1 online RW 20MB 18.02MB 5%
NAS_M vol1_m aggr2_C2N1 online DP 22MB 21.78MB 1%
cluster2-01
vol0 aggr0_cluster2_01
online RW 807.3MB 402.4MB 47%
5 entries were displayed.
3. Why did the SnapMirror replication fail? View the detailed SnapMirror information to verify this.
The transfer failed because the SnapMirror Synchronous license is not installed.
cluster2::> snapmirror show -source-path NAS:vol1 -destination-path NAS_M:vol1_m -instance
Source Path: NAS:vol1
Destination Path: NAS_M:vol1_m
Relationship Type: XDP
Relationship Group Type: none
SnapMirror Schedule: -
SnapMirror Policy Type: sync-mirror
SnapMirror Policy: Sync
Tries Limit: -
Throttle (KB/sec): unlimited
Mirror State: Uninitialized
Relationship Status: Idle
Healthy: false
Unhealthy Reason: Transfer failed.
Destination Volume Node: cluster2-01
Relationship ID: 930e34c7-9e9c-11e9-9521-000c29adabc3
Current Operation ID: -
Transfer Type: -
Transfer Error: -
Current Throttle: -
Current Transfer Priority: -
Last Transfer Type: initialize
Last Transfer Error: Failed to create Snapshot copy snapmirror.3985c590-9e95-11e9-9521000c29adabc3_2154150304.2019-07-04_134453 on volume NAS:vol1. (SnapMirror Synchronous license check failed for cluster [SRC Cluster]. Reason: SnapMirror Synchronous License not found.)
Last Transfer Size: -
< output truncated >
4. View SnapMirror destinations from Cluster1.
cluster1::> snapmirror list-destinations
Progress
Source Destination Transfer Last Relationship
Path Type Path Status Progress Updated Id
----------- ----- ------------ ------- --------- ------------ ---------------
NAS:vol1 XDP NAS_M:vol1_m2
- - - 4ef36e1c-9db6-11e9-9521-000c29adabc3
Clean-up
5. Remove the SnapMirror relationship on Cluster2 and delete vol1_m.
cluster2::> snapmirror quiesce -destination-path NAS_M:vol1_m
Operation succeeded: snapmirror quiesce for destination "NAS_M:vol1_m".
cluster2::> snapmirror delete -destination-path NAS_M:vol1_m
Operation succeeded: snapmirror delete for the relationship with destination "NAS_M:vol1_m".
cluster2::> volume modify -vserver NAS_M -volume vol1_m -state offline
Warning: Volume "vol1_m" on Vserver "NAS_M" must be unmounted before being taken offline or restricted. Clients will not be able to access the affected volume and related junction paths after that. Do you still want to unmount the volume and continue? {y|n}: y
Volume modify successful on volume vol1_m of Vserver NAS_M.
cluster2::> volume delete -vserver NAS_M -volume vol1_m
Warning: Are you sure you want to delete volume "vol1_m" in Vserver "NAS_M" ? {y|n}: y
[Job 39] Job succeeded: Successful
6. On Cluster1, release the SnapMirror relationship and delete all snapshots in vol1.
cluster1::> snapmirror release -source-path NAS:vol1 -destination-path NAS_M:vol1_m -force
[Job 121] Job is queued: snapmirror release for destination "NAS_M:vol1_m".
Warning: Snapshot copies on source volume "NAS:vol1" generated by SnapMirror for the purpose of mirroring to destination volume "NAS_M:vol1_m" will be deleted. Once these Snapshot copies are deleted, it will not be possible to re-establish a mirroring relationship between these two volumes unless there are other common Snapshot copies between the source and the destination volumes.
[Job 121] Job succeeded: SnapMirror Release Succeeded
cluster1::> volume snapshot show -vserver NAS -volume vol1
---Blocks---
Vserver Volume Snapshot Size Total% Used%
-------- -------- ------------------------------------- -------- ------ -----
NAS vol1
snapmirror.b0d1ec4c-99c1-11e9-afbf-000c296f941d_2156825624.2019-07-02_105901
936KB 1% 6%
cluster1::> volume snapshot delete -vserver NAS -volume vol1 -snapshot snapmirror.b0d1ec4c-99c1-11e9-afbf-000c296f941d_2156825624.2019-07-02_105901
Warning: Deleting a Snapshot copy permanently removes any data that is stored only in that Snapshot copy. Are you sure you want to delete Snapshot copy "snapmirror.b0d1ec4c-99c1-11e9-afbf-000c296f941d_2156825624.2019-07-02_105901" for volume "vol1" in Vserver "NAS" ?
{y|n}: y
Additional Resources
NetApp Back to Basics: SnapMirror
Click Here to get my 'NetApp ONTAP 9 Storage Complete' training course.

Text by Alex Papas, Technical Writer at www.flackbox.com
Alex has been working with Data Center technologies for over 20 years. Currently he is the Network Lead for Costa, one of the largest agricultural companies in Australia. When he’s not knee deep in technology you can find Alex performing with his band 2am