
This is the first tutorial in my ‘Practical Introduction to Cloud Computing’ course. Click here to enrol in the complete course for free!
In this first cloud training tutorial, I’m going to talk about what we had before cloud, because to understand how cloud is different, you need to know what we had before it.
We’re going to discuss traditional on-premise solutions, also colocation solutions, and then in the next tutorial, I’ll talk about server virtualization. Server virtualization gave us a lot more flexibility in how we can deploy our data centres, and it’s also one of the main enablers that made cloud possible. Scroll down for the video and also text tutorial.
Traditional IT Deployment Models – On Prem and Colo – Video Tutorial

On Premises Solutions
On-premises solutions have been available really since IT first began. With on-premises, all equipment is located in your building and owned by you (where ‘you’ are the company).
On Prem Characteristics
There’s clear lines of demarcation – all of the equipment that is in your offices is your responsibility, but the network connections between your offices are the responsibility of your network service provider and will be subject to your Service Level Agreement with them.
All of the equipment in your offices has to be paid for up front, so you’ve got a one-time upfront fee, and it’s a capital expenditure cost. New equipment will typically take at least a week to deploy, because it needs to be approved by management for the purchase, you need to order it, it needs to get delivered to your location, you then need to unpack it and install it in the rack, and you then need to configure it as well. So, really, one week is a pretty optimistic time frame.
Equipment is going to need regular technology refreshes, because it gets out of date. If you look at the CPUs that we have now, they’re a lot more powerful than what we had five or 10 years ago. To avoid having outdated equipment you’re going to need to replace it fairly regularly.
You’re going to want to consider redundancy as well. If you’re running mission-critical applications on your equipment, things that are really important for your business to function, you’re going to want to make sure that it’s always available, so you’re going to want to eliminate any single points of failure. So if one piece of equipment fails, there’s another one there as a backup already waiting ahead of time.
Data Center Tiers
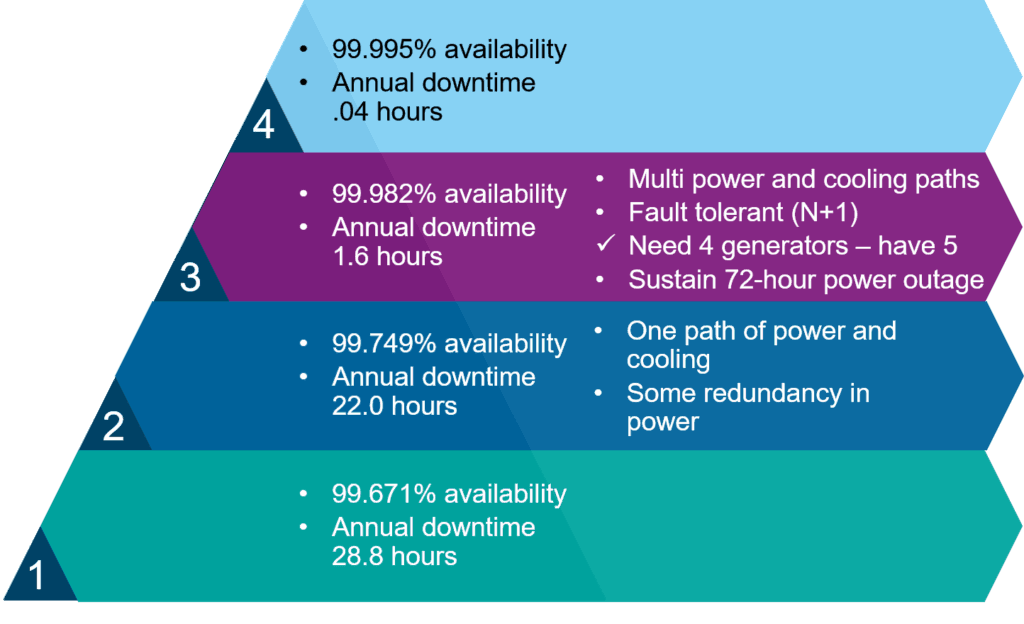
While we’re talking about mission-critical applications, if you do have these you’re also going to want to make sure that the facility that your equipment is located in is hardened. There’s standards for how ‘hardened’ – how available – our data centres are, and the higher the number of the tier, the more highly available the data centre will be. The tiers are shown in the diagram below:
Tier 1 Data Center
Starting down at the bottom layer, we’ve got Tier 1, which is expected to have a 99.671% availability, which equates to an annual downtime of 28.8 hours. With Tier 1, there’s no specific requirements for redundancy.
Tier 2 Data Center
With a Tier 2 data centre, it needs to be more available, with an annual downtime of only 22 hours. It only requires to have one path of power and cooling, so we don’t need to have physically separate redundant paths, but we will expect to have some redundancy for the power components.
Tier 3 Data Center
Moving up, a Tier 3 data centre allows for annual downtime of only 1.6 hours, is required to have multiple power and cooling paths, and it needs to support N+1 fault tolerance. N+1 means, for example, if you required four generators to supply the required power, then you would put in five. The power needs to be able to sustain a 72-hour power outage from the grid and still be able to provide backup from generators.
Tier 4 Data Center
At the highest level we have a Tier 4 data centre. That has an annual downtime of just 0.4 hours. Obviously, the higher the tier, the more expensive it’s going to be to build the facility. If you did want to have a highly available facility, and you’re building it yourself, that’s going to be a huge upfront capital expenditure cost.
Colocation Facilities
A way that you can make this more affordable is by using a colocation facility. A colocation centre, or “Colo,” is a data centre location where the owner of that facility rents out space to external customers. The facility owner provides the power, the cooling, and physical security, and the customer puts their own servers, storage, and networking equipment into the facility.
Independent Colo providers such as Equinix offer customers multiple network connectivity options through a choice of network service providers who have connections coming into the facility, and those network service providers will also typically peer with each other in the Colo. So your big network service providers like Verizon, AT&T, they all have connections coming into the Colos, and they also peer in there as well. In fact, that’s how network connectivity works across the Internet.
Colo Characteristics
Looking at the characteristics of Colo solutions, your server infrastructure, from the point of view of the customer, is located in an external Colo building, but it’s just your servers and supporting devices that you’re going to have in there. Obviously, your users aren’t going to be based in the colo building as well; you’re still going to have your own office, where you’re going to have your own staff with their own desktops, and you’re going to require connectivity from your office to the Colo facility so that your users get access to their servers.
The Colo provider owns the data centre facility and is responsible for providing highly available power, cooling, and physical security according to the terms of the Service Level Agreement that you have with them. You own your own server, storage, and networking equipment within the Colo facility, and the connections between your offices and the Colo are going to be your network service provider’s responsibility. You’ll have an agreement with them as well.
Your equipment within the Colo facility is a CapEx cost. You still had to buy it as an upfront cost, so that’s capital expenditure. But the monthly Colo hosting fees are now an operational expenditure. (CapEx is a one-off upfront cost, and OpEx cost is an ongoing monthly fee.) This makes having a highly available data centre more affordable, because rather than having to pay for that huge upfront CapEx cost, you can pay it as a monthly OpEx cost.
New equipment is still typically going to take over a week to deploy. You still own and provide the equipment in the data centre, so you’re still going to have to go through the same process again of ordering it, having it delivered, cabling it, and configuring it as well. And again, you still own the equipment, so you’re still going to have to update it regularly.
You need to consider redundancy for the hardware that you own. For example, if you’ve got mission-critical servers in the facility, you’re maybe going to look at clustering those servers so that there’s not a single point of failure. But the redundancy for the power and cooling is handled by the facility.
Additional Resources
CDP Corp: On-Premise Data Centers vs Colocation: Which is Better?